Augment 接受模型对象和数据集,并添加有关数据集中每个观察值的信息。最常见的是,这包括 .fitted 列中的预测值、.resid 列中的残差以及 .se.fit 列中拟合值的标准误差。新列始终以 . 前缀开头,以避免覆盖原始数据集中的列。
用户可以通过 data 参数或 newdata 参数传递数据以进行增强。如果用户将数据传递给 data 参数,则它必须正是用于拟合模型对象的数据。将数据集传递给 newdata 以扩充模型拟合期间未使用的数据。这仍然要求至少存在用于拟合模型的所有预测变量列。如果用于拟合模型的原始结果变量未包含在 newdata 中,则输出中不会包含 .resid 列。
根据是否给出 data 或 newdata,增强的行为通常会有所不同。这是因为通常存在与训练观察(例如影响或相关)测量相关的信息,而这些信息对于新观察没有有意义的定义。
为了方便起见,许多增强方法提供默认的 data 参数,以便 augment(fit) 将返回增强的训练数据。在这些情况下,augment 尝试根据模型对象重建原始数据,并取得了不同程度的成功。
增强数据集始终以 tibble::tibble 形式返回,其行数与传递的数据集相同。这意味着传递的数据必须可强制转换为 tibble。如果预测变量将模型作为协变量矩阵的一部分输入,例如当模型公式使用 splines::ns() 、 stats::poly() 或 survival::Surv() 时,它会表示为矩阵列。
我们正在定义适合各种 na.action 参数的模型的行为,但目前不保证数据丢失时的行为。
用法
# S3 method for survreg
augment(
x,
data = model.frame(x),
newdata = NULL,
type.predict = "response",
type.residuals = "response",
...
)参数
- x
-
从
survival::survreg()返回的survreg对象。 - data
-
base::data.frame 或
tibble::tibble()包含用于生成对象x的原始数据。默认为stats::model.frame(x),以便augment(my_fit)返回增强的原始数据。不要将新数据传递给data参数。增强将报告传递给data参数的数据的影响和烹饪距离等信息。这些度量仅针对原始训练数据定义。 - newdata
-
base::data.frame()或tibble::tibble()包含用于创建x的所有原始预测变量。默认为NULL,表示没有任何内容传递给newdata。如果指定了newdata,则data参数将被忽略。 - type.predict
-
指示要使用的预测类型的字符。传递给
stats::predict()泛型的type参数。允许的参数因模型类而异,因此请务必阅读predict.my_class文档。 - type.residuals
-
指示要使用的残差类型的字符。传递给
stats::residuals()泛型的type参数。允许的参数因模型类而异,因此请务必阅读residuals.my_class文档。 - ...
-
附加参数。不曾用过。仅需要匹配通用签名。注意:拼写错误的参数将被吸收到
...中,并被忽略。如果拼写错误的参数有默认值,则将使用默认值。例如,如果您传递conf.lvel = 0.9,所有计算将使用conf.level = 0.95进行。这里有两个异常:
也可以看看
augment() , survival::survreg()
其他 survreg 整理器:glance.survreg() 、tidy.survreg()
其他生存整理器:augment.coxph() , glance.aareg() , glance.cch() , glance.coxph() , glance.pyears() , glance.survdiff() , glance.survexp() , glance.survfit() , glance.survreg() , tidy.aareg() , tidy.cch() , tidy.coxph() , tidy.pyears() , tidy.survdiff() , tidy.survexp() , tidy.survfit() , tidy.survreg()
例子
# load libraries for models and data
library(survival)
# fit model
sr <- survreg(
Surv(futime, fustat) ~ ecog.ps + rx,
ovarian,
dist = "exponential"
)
# summarize model fit with tidiers + visualization
tidy(sr)
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 6.96 1.32 5.27 0.000000139
#> 2 ecog.ps -0.433 0.587 -0.738 0.461
#> 3 rx 0.582 0.587 0.991 0.322
augment(sr, ovarian)
#> # A tibble: 26 × 9
#> futime fustat age resid.ds rx ecog.ps .fitted .se.fit .resid
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 59 1 72.3 2 1 1 1224. 639. -1165.
#> 2 115 1 74.5 2 1 1 1224. 639. -1109.
#> 3 156 1 66.5 2 1 2 794. 350. -638.
#> 4 421 0 53.4 2 2 1 2190. 1202. -1769.
#> 5 431 1 50.3 2 1 1 1224. 639. -793.
#> 6 448 0 56.4 1 1 2 794. 350. -346.
#> 7 464 1 56.9 2 2 2 1420. 741. -956.
#> 8 475 1 59.9 2 2 2 1420. 741. -945.
#> 9 477 0 64.2 2 1 1 1224. 639. -747.
#> 10 563 1 55.2 1 2 2 1420. 741. -857.
#> # ℹ 16 more rows
glance(sr)
#> # A tibble: 1 × 9
#> iter df statistic logLik AIC BIC df.residual nobs p.value
#> <int> <int> <dbl> <dbl> <dbl> <dbl> <int> <int> <dbl>
#> 1 4 3 1.67 -97.2 200. 204. 23 26 0.434
# coefficient plot
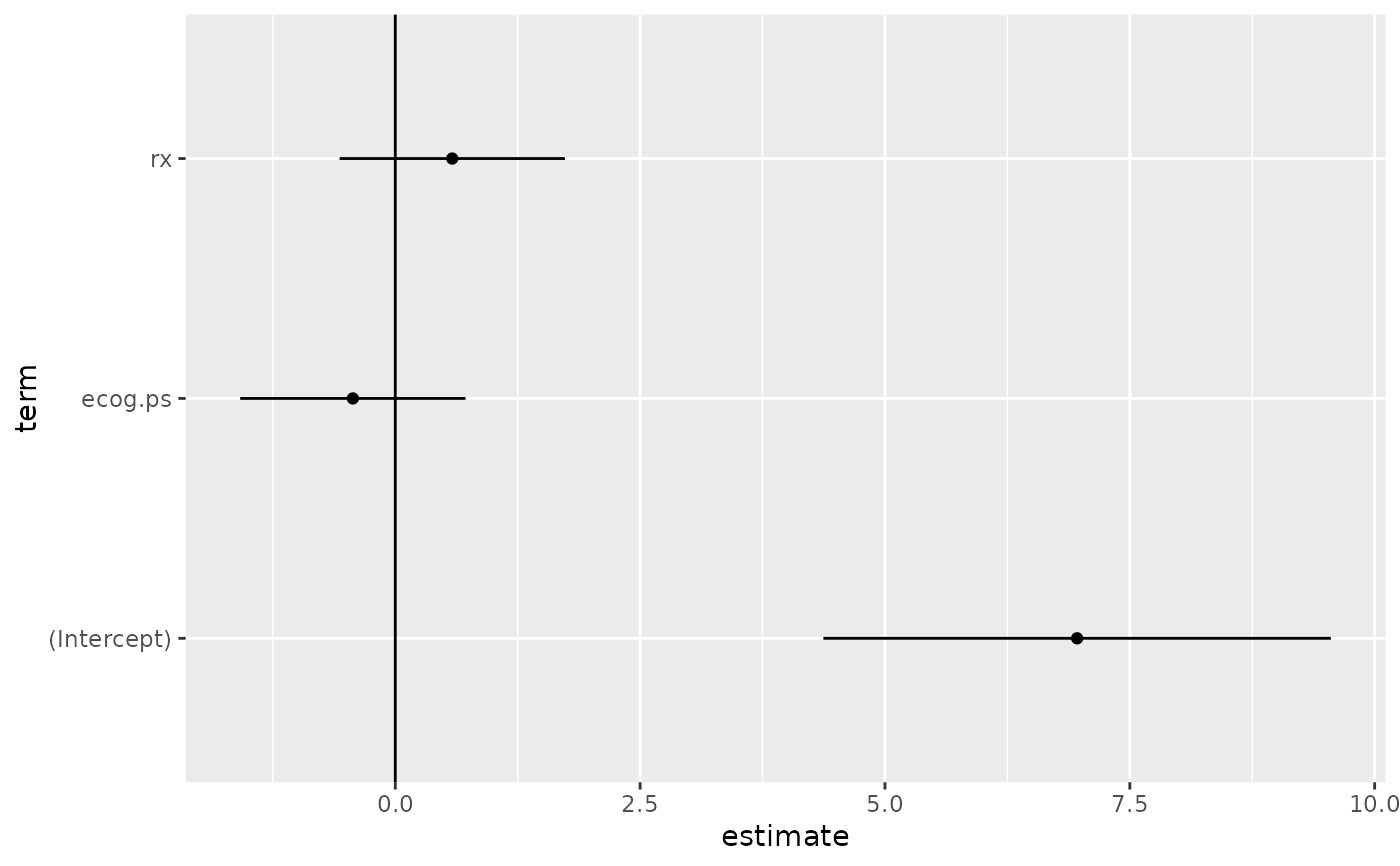
td <- tidy(sr, conf.int = TRUE)
library(ggplot2)
ggplot(td, aes(estimate, term)) +
geom_point() +
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high), height = 0) +
geom_vline(xintercept = 0)
相关用法
- R broom augment.speedlm 使用来自 speedlm 对象的信息增强数据
- R broom augment.smooth.spline 整理一个(n)smooth.spline对象
- R broom augment.sarlm 使用来自(n)个spatialreg对象的信息来增强数据
- R broom augment.betamfx 使用来自 betamfx 对象的信息增强数据
- R broom augment.robustbase.glmrob 使用来自 glmrob 对象的信息增强数据
- R broom augment.rlm 使用来自 rlm 对象的信息增强数据
- R broom augment.htest 使用来自(n)个 htest 对象的信息来增强数据
- R broom augment.clm 使用来自 clm 对象的信息增强数据
- R broom augment.felm 使用来自 (n) 个 felm 对象的信息来增强数据
- R broom augment.drc 使用来自 a(n) drc 对象的信息增强数据
- R broom augment.decomposed.ts 使用来自 decomposed.ts 对象的信息增强数据
- R broom augment.poLCA 使用来自 poLCA 对象的信息增强数据
- R broom augment.lm 使用来自 (n) lm 对象的信息增强数据
- R broom augment.rqs 使用来自 (n) 个 rqs 对象的信息来增强数据
- R broom augment.polr 使用来自 (n) 个 polr 对象的信息增强数据
- R broom augment.plm 使用来自 plm 对象的信息增强数据
- R broom augment.nls 使用来自 nls 对象的信息增强数据
- R broom augment.gam 使用来自 gam 对象的信息增强数据
- R broom augment.fixest 使用来自(n)个最固定对象的信息来增强数据
- R broom augment.rq 使用来自 a(n) rq 对象的信息增强数据
- R broom augment.Mclust 使用来自 Mclust 对象的信息增强数据
- R broom augment.nlrq 整理 a(n) nlrq 对象
- R broom augment.robustbase.lmrob 使用来自 lmrob 对象的信息增强数据
- R broom augment.lmRob 使用来自 lmRob 对象的信息增强数据
- R broom augment.mlogit 使用来自 mlogit 对象的信息增强数据
注:本文由纯净天空筛选整理自等大神的英文原创作品 Augment data with information from a(n) survreg object。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。