Tidy 总结了有关模型组件的信息。模型组件可能是回归中的单个项、单个假设、聚类或类。 tidy 所认为的模型组件的确切含义因模型而异,但通常是不言而喻的。如果模型具有多种不同类型的组件,您将需要指定要返回哪些组件。
参数
- x
-
从
survival::survfit()返回的survfit对象。 - ...
-
附加参数。不曾用过。仅需要匹配通用签名。注意:拼写错误的参数将被吸收到
...中,并被忽略。如果拼写错误的参数有默认值,则将使用默认值。例如,如果您传递conf.lvel = 0.9,所有计算将使用conf.level = 0.95进行。这里有两个异常:
也可以看看
其他生存整理器:augment.coxph() , augment.survreg() , glance.aareg() , glance.cch() , glance.coxph() , glance.pyears() , glance.survdiff() , glance.survexp() , glance.survfit() , glance.survreg() , tidy.aareg() , tidy.cch() , tidy.coxph() , tidy.pyears() , tidy.survdiff() , tidy.survexp() , tidy.survreg()
值
带有列的 tibble::tibble():
- conf.high
-
估计置信区间的上限。
- conf.low
-
估计置信区间的下限。
- n.censor
-
审查事件的数量。
- n.event
-
时间 t 时的事件数。
- n.risk
-
零时刻处于危险中的人数。
- std.error
-
回归项的标准误差。
- time
-
时间点。
- estimate
-
多状态时生存率或累积发病率的估计
- state
-
状态是否为多状态 survfit 对象输入
- strata
-
strata if 分层 survfit 对象输入
例子
# load libraries for models and data
library(survival)
# fit model
cfit <- coxph(Surv(time, status) ~ age + sex, lung)
sfit <- survfit(cfit)
# summarize model fit with tidiers + visualization
tidy(sfit)
#> # A tibble: 186 × 8
#> time n.risk n.event n.censor estimate std.error conf.high conf.low
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 5 228 1 0 0.996 0.00419 1 0.988
#> 2 11 227 3 0 0.983 0.00845 1.00 0.967
#> 3 12 224 1 0 0.979 0.00947 0.997 0.961
#> 4 13 223 2 0 0.971 0.0113 0.992 0.949
#> 5 15 221 1 0 0.966 0.0121 0.990 0.944
#> 6 26 220 1 0 0.962 0.0129 0.987 0.938
#> 7 30 219 1 0 0.958 0.0136 0.984 0.933
#> 8 31 218 1 0 0.954 0.0143 0.981 0.927
#> 9 53 217 2 0 0.945 0.0157 0.975 0.917
#> 10 54 215 1 0 0.941 0.0163 0.972 0.911
#> # ℹ 176 more rows
glance(sfit)
#> # A tibble: 1 × 10
#> records n.max n.start events rmean rmean.std.error median conf.low
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 228 228 228 165 381. 20.3 320 285
#> # ℹ 2 more variables: conf.high <dbl>, nobs <int>
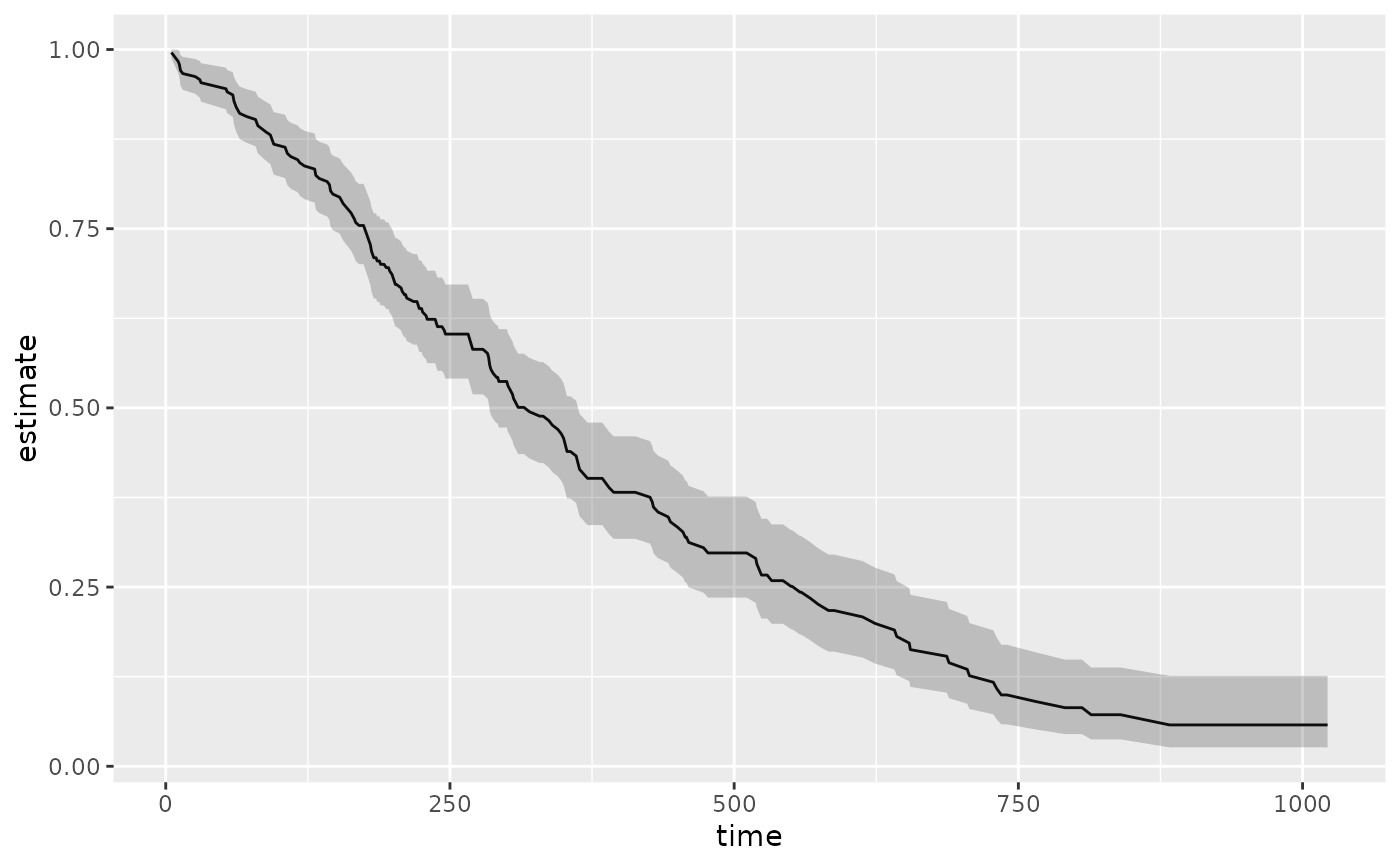
library(ggplot2)
ggplot(tidy(sfit), aes(time, estimate)) +
geom_line() +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .25)
 # multi-state
fitCI <- survfit(Surv(stop, status * as.numeric(event), type = "mstate") ~ 1,
data = mgus1, subset = (start == 0)
)
td_multi <- tidy(fitCI)
td_multi
#> # A tibble: 711 × 9
#> time n.risk n.event n.censor estimate std.error conf.high conf.low
#> <dbl> <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 6 241 0 0 0.996 0.00414 1 0.988
#> 2 7 240 0 0 0.992 0.00584 1 0.980
#> 3 31 239 0 0 0.988 0.00714 1 0.974
#> 4 32 238 0 0 0.983 0.00823 1.00 0.967
#> 5 39 237 0 0 0.979 0.00918 0.997 0.961
#> 6 60 236 0 0 0.975 0.0100 0.995 0.956
#> 7 61 235 0 0 0.967 0.0115 0.990 0.944
#> 8 152 233 0 0 0.963 0.0122 0.987 0.939
#> 9 153 232 0 0 0.959 0.0128 0.984 0.934
#> 10 174 231 0 0 0.954 0.0134 0.981 0.928
#> # ℹ 701 more rows
#> # ℹ 1 more variable: state <chr>
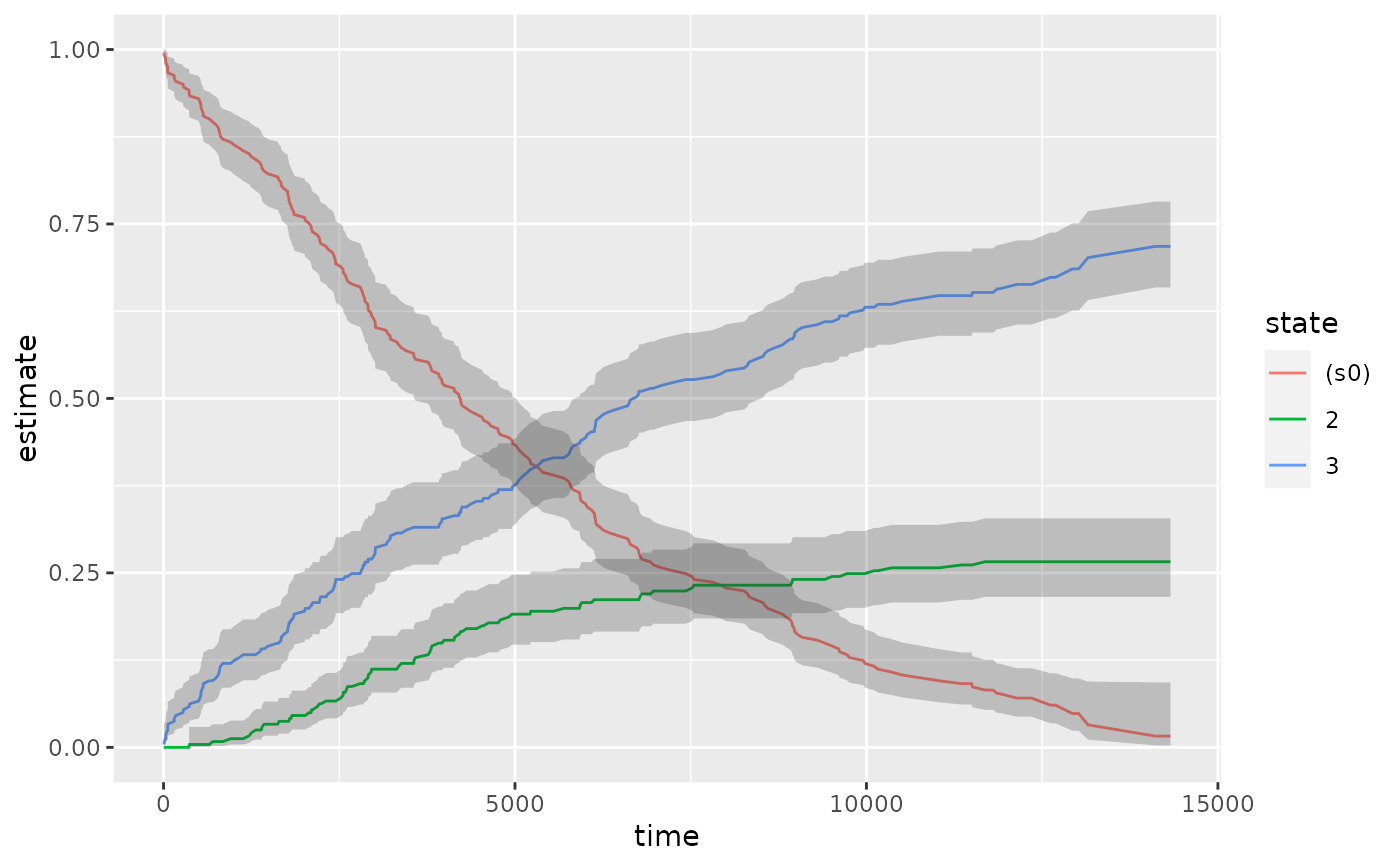
ggplot(td_multi, aes(time, estimate, group = state)) +
geom_line(aes(color = state)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .25)
# multi-state
fitCI <- survfit(Surv(stop, status * as.numeric(event), type = "mstate") ~ 1,
data = mgus1, subset = (start == 0)
)
td_multi <- tidy(fitCI)
td_multi
#> # A tibble: 711 × 9
#> time n.risk n.event n.censor estimate std.error conf.high conf.low
#> <dbl> <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 6 241 0 0 0.996 0.00414 1 0.988
#> 2 7 240 0 0 0.992 0.00584 1 0.980
#> 3 31 239 0 0 0.988 0.00714 1 0.974
#> 4 32 238 0 0 0.983 0.00823 1.00 0.967
#> 5 39 237 0 0 0.979 0.00918 0.997 0.961
#> 6 60 236 0 0 0.975 0.0100 0.995 0.956
#> 7 61 235 0 0 0.967 0.0115 0.990 0.944
#> 8 152 233 0 0 0.963 0.0122 0.987 0.939
#> 9 153 232 0 0 0.959 0.0128 0.984 0.934
#> 10 174 231 0 0 0.954 0.0134 0.981 0.928
#> # ℹ 701 more rows
#> # ℹ 1 more variable: state <chr>
ggplot(td_multi, aes(time, estimate, group = state)) +
geom_line(aes(color = state)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .25)
相关用法
- R broom tidy.survreg 整理 a(n) survreg 对象
- R broom tidy.survexp 整理 a(n) survexp 对象
- R broom tidy.survdiff 整理 a(n) survdiff 对象
- R broom tidy.summary_emm 整理一个(n)summary_emm对象
- R broom tidy.summary.glht 整理一个(n)summary.glht对象
- R broom tidy.summary.lm 整理 a(n)summary.lm 对象
- R broom tidy.svyolr 整理 a(n) svyolr 对象
- R broom tidy.spec 整理一个(n)规范对象
- R broom tidy.sarlm 空间自回归模型的整理方法
- R broom tidy.speedglm 整理 a(n) speedglm 对象
- R broom tidy.speedlm 整理 a(n) speedlm 对象
- R broom tidy.systemfit 整理 a(n) systemfit 对象
- R broom tidy.robustbase.glmrob 整理 a(n) glmrob 对象
- R broom tidy.acf 整理 a(n) acf 对象
- R broom tidy.robustbase.lmrob 整理 a(n) lmrob 对象
- R broom tidy.biglm 整理 a(n) biglm 对象
- R broom tidy.garch 整理 a(n) garch 对象
- R broom tidy.rq 整理 a(n) rq 对象
- R broom tidy.kmeans 整理 a(n) kmeans 对象
- R broom tidy.betamfx 整理 a(n) betamfx 对象
- R broom tidy.anova 整理 a(n) anova 对象
- R broom tidy.btergm 整理 a(n) btergm 对象
- R broom tidy.cv.glmnet 整理 a(n) cv.glmnet 对象
- R broom tidy.roc 整理 a(n) roc 对象
- R broom tidy.poLCA 整理 a(n) poLCA 对象
注:本文由纯净天空筛选整理自等大神的英文原创作品 Tidy a(n) survfit object。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。