Tidy 總結了有關模型組件的信息。模型組件可能是回歸中的單個項、單個假設、聚類或類。 tidy 所認為的模型組件的確切含義因模型而異,但通常是不言而喻的。如果模型具有多種不同類型的組件,您將需要指定要返回哪些組件。
參數
- x
-
從
survival::survreg()返回的survreg對象。 - conf.level
-
用於置信區間的置信水平(如果
conf.int = TRUE)。必須嚴格大於 0 且小於 1。默認為 0.95,對應於 95% 的置信區間。 - conf.int
-
邏輯指示是否在整理的輸出中包含置信區間。默認為
FALSE。 - ...
-
附加參數。不曾用過。僅需要匹配通用簽名。注意:拚寫錯誤的參數將被吸收到
...中,並被忽略。如果拚寫錯誤的參數有默認值,則將使用默認值。例如,如果您傳遞conf.lvel = 0.9,所有計算將使用conf.level = 0.95進行。這裏有兩個異常:
也可以看看
其他 survreg 整理器:augment.survreg() 、glance.survreg()
其他生存整理器:augment.coxph() , augment.survreg() , glance.aareg() , glance.cch() , glance.coxph() , glance.pyears() , glance.survdiff() , glance.survexp() , glance.survfit() , glance.survreg() , tidy.aareg() , tidy.cch() , tidy.coxph() , tidy.pyears() , tidy.survdiff() , tidy.survexp() , tidy.survfit()
值
帶有列的 tibble::tibble():
- conf.high
-
估計置信區間的上限。
- conf.low
-
估計置信區間的下限。
- estimate
-
回歸項的估計值。
- p.value
-
與觀察到的統計量相關的兩側 p 值。
- statistic
-
在回歸項非零的假設中使用的 T-statistic 的值。
- std.error
-
回歸項的標準誤差。
- term
-
回歸項的名稱。
例子
# load libraries for models and data
library(survival)
# fit model
sr <- survreg(
Surv(futime, fustat) ~ ecog.ps + rx,
ovarian,
dist = "exponential"
)
# summarize model fit with tidiers + visualization
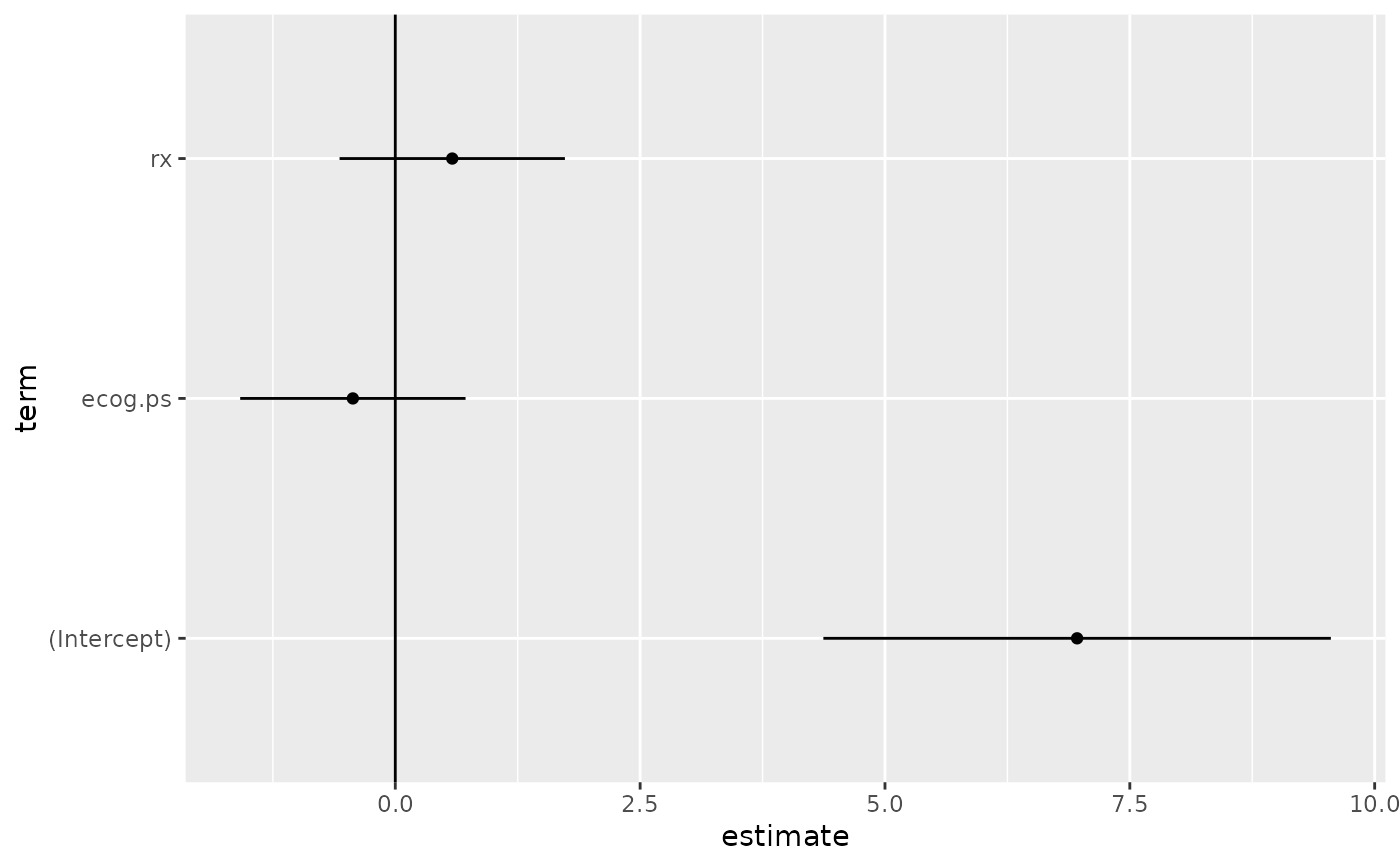
tidy(sr)
#> # A tibble: 3 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 6.96 1.32 5.27 0.000000139
#> 2 ecog.ps -0.433 0.587 -0.738 0.461
#> 3 rx 0.582 0.587 0.991 0.322
augment(sr, ovarian)
#> # A tibble: 26 × 9
#> futime fustat age resid.ds rx ecog.ps .fitted .se.fit .resid
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 59 1 72.3 2 1 1 1224. 639. -1165.
#> 2 115 1 74.5 2 1 1 1224. 639. -1109.
#> 3 156 1 66.5 2 1 2 794. 350. -638.
#> 4 421 0 53.4 2 2 1 2190. 1202. -1769.
#> 5 431 1 50.3 2 1 1 1224. 639. -793.
#> 6 448 0 56.4 1 1 2 794. 350. -346.
#> 7 464 1 56.9 2 2 2 1420. 741. -956.
#> 8 475 1 59.9 2 2 2 1420. 741. -945.
#> 9 477 0 64.2 2 1 1 1224. 639. -747.
#> 10 563 1 55.2 1 2 2 1420. 741. -857.
#> # ℹ 16 more rows
glance(sr)
#> # A tibble: 1 × 9
#> iter df statistic logLik AIC BIC df.residual nobs p.value
#> <int> <int> <dbl> <dbl> <dbl> <dbl> <int> <int> <dbl>
#> 1 4 3 1.67 -97.2 200. 204. 23 26 0.434
# coefficient plot
td <- tidy(sr, conf.int = TRUE)
library(ggplot2)
ggplot(td, aes(estimate, term)) +
geom_point() +
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high), height = 0) +
geom_vline(xintercept = 0)
相關用法
- R broom tidy.survexp 整理 a(n) survexp 對象
- R broom tidy.survdiff 整理 a(n) survdiff 對象
- R broom tidy.survfit 整理 a(n) survfit 對象
- R broom tidy.summary_emm 整理一個(n)summary_emm對象
- R broom tidy.summary.glht 整理一個(n)summary.glht對象
- R broom tidy.summary.lm 整理 a(n)summary.lm 對象
- R broom tidy.svyolr 整理 a(n) svyolr 對象
- R broom tidy.spec 整理一個(n)規範對象
- R broom tidy.sarlm 空間自回歸模型的整理方法
- R broom tidy.speedglm 整理 a(n) speedglm 對象
- R broom tidy.speedlm 整理 a(n) speedlm 對象
- R broom tidy.systemfit 整理 a(n) systemfit 對象
- R broom tidy.robustbase.glmrob 整理 a(n) glmrob 對象
- R broom tidy.acf 整理 a(n) acf 對象
- R broom tidy.robustbase.lmrob 整理 a(n) lmrob 對象
- R broom tidy.biglm 整理 a(n) biglm 對象
- R broom tidy.garch 整理 a(n) garch 對象
- R broom tidy.rq 整理 a(n) rq 對象
- R broom tidy.kmeans 整理 a(n) kmeans 對象
- R broom tidy.betamfx 整理 a(n) betamfx 對象
- R broom tidy.anova 整理 a(n) anova 對象
- R broom tidy.btergm 整理 a(n) btergm 對象
- R broom tidy.cv.glmnet 整理 a(n) cv.glmnet 對象
- R broom tidy.roc 整理 a(n) roc 對象
- R broom tidy.poLCA 整理 a(n) poLCA 對象
注:本文由純淨天空篩選整理自等大神的英文原創作品 Tidy a(n) survreg object。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。