這是一個變體 geom_point(),它計算每個位置的觀測數量,然後將計數映射到點區域。當您有離散數據和過度繪製時,它很有用。
用法
geom_count(
mapping = NULL,
data = NULL,
stat = "sum",
position = "identity",
...,
na.rm = FALSE,
show.legend = NA,
inherit.aes = TRUE
)
stat_sum(
mapping = NULL,
data = NULL,
geom = "point",
position = "identity",
...,
na.rm = FALSE,
show.legend = NA,
inherit.aes = TRUE
)參數
- mapping
-
由
aes()創建的一組美學映射。如果指定且inherit.aes = TRUE(默認),它將與繪圖頂層的默認映射組合。如果沒有繪圖映射,則必須提供mapping。 - data
-
該層要顯示的數據。有以下三種選擇:
如果默認為
NULL,則數據繼承自ggplot()調用中指定的繪圖數據。data.frame或其他對象將覆蓋繪圖數據。所有對象都將被強化以生成 DataFrame 。請參閱fortify()將為其創建變量。將使用單個參數(繪圖數據)調用
function。返回值必須是data.frame,並將用作圖層數據。可以從formula創建function(例如~ head(.x, 10))。 - position
-
位置調整,可以是命名調整的字符串(例如
"jitter"使用position_jitter),也可以是調用位置調整函數的結果。如果需要更改調整設置,請使用後者。 - ...
-
其他參數傳遞給
layer()。這些通常是美學,用於將美學設置為固定值,例如colour = "red"或size = 3。它們也可能是配對的 geom/stat 的參數。 - na.rm
-
如果
FALSE,則默認缺失值將被刪除並帶有警告。如果TRUE,缺失值將被靜默刪除。 - show.legend
-
合乎邏輯的。該層是否應該包含在圖例中?
NA(默認值)包括是否映射了任何美學。FALSE從不包含,而TRUE始終包含。它也可以是一個命名的邏輯向量,以精細地選擇要顯示的美學。 - inherit.aes
-
如果
FALSE,則覆蓋默認美學,而不是與它們組合。這對於定義數據和美觀的輔助函數最有用,並且不應繼承默認繪圖規範的行為,例如borders()。 - geom, stat
-
用於覆蓋
geom_count()和stat_sum()之間的默認連接。
美學
geom_point() 理解以下美學(所需的美學以粗體顯示):
-
x -
y -
alpha -
colour -
fill -
group -
shape -
size -
stroke
在 vignette("ggplot2-specs") 中了解有關設置這些美學的更多信息。
計算變量
這些是由層的 'stat' 部分計算的,可以使用 delayed evaluation 訪問。
-
after_stat(n)
位置觀測值的數量。 -
after_stat(prop)
該麵板中該位置的點的百分比。
也可以看看
對於連續的 x 和 y ,請使用 geom_bin2d() 。
例子
ggplot(mpg, aes(cty, hwy)) +
geom_point()
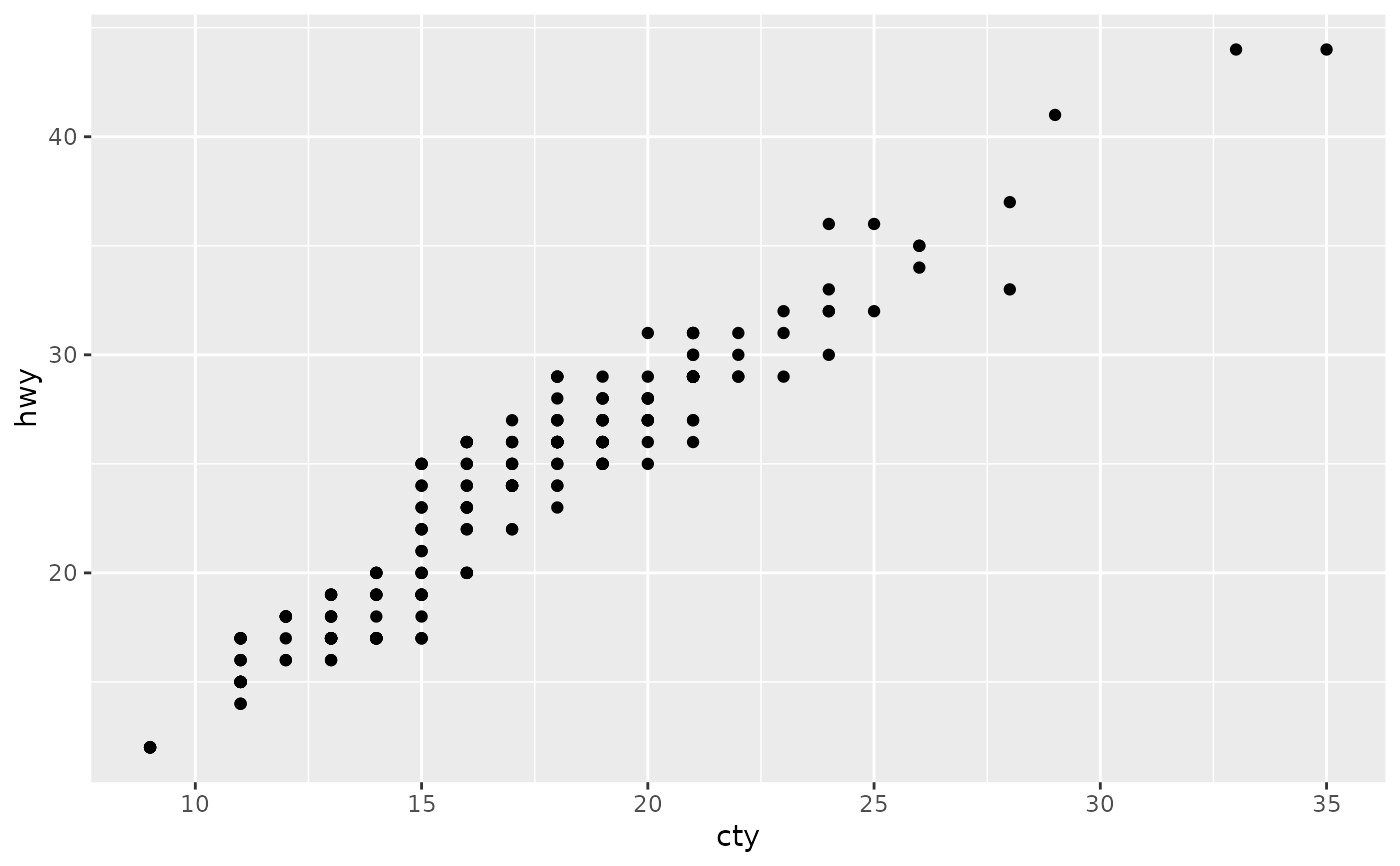 ggplot(mpg, aes(cty, hwy)) +
geom_count()
ggplot(mpg, aes(cty, hwy)) +
geom_count()
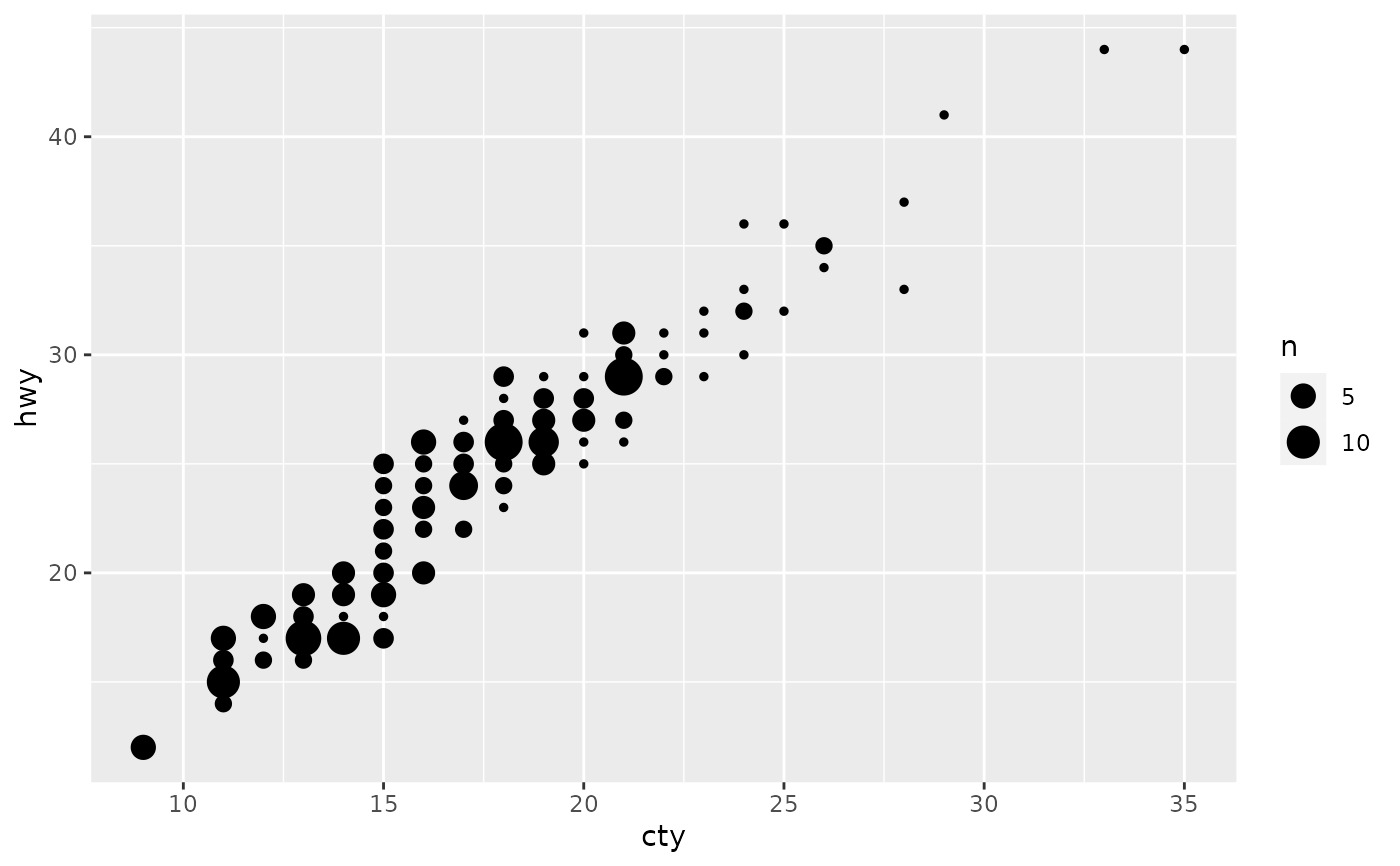 # Best used in conjunction with scale_size_area which ensures that
# counts of zero would be given size 0. Doesn't make much different
# here because the smallest count is already close to 0.
ggplot(mpg, aes(cty, hwy)) +
geom_count() +
scale_size_area()
# Best used in conjunction with scale_size_area which ensures that
# counts of zero would be given size 0. Doesn't make much different
# here because the smallest count is already close to 0.
ggplot(mpg, aes(cty, hwy)) +
geom_count() +
scale_size_area()
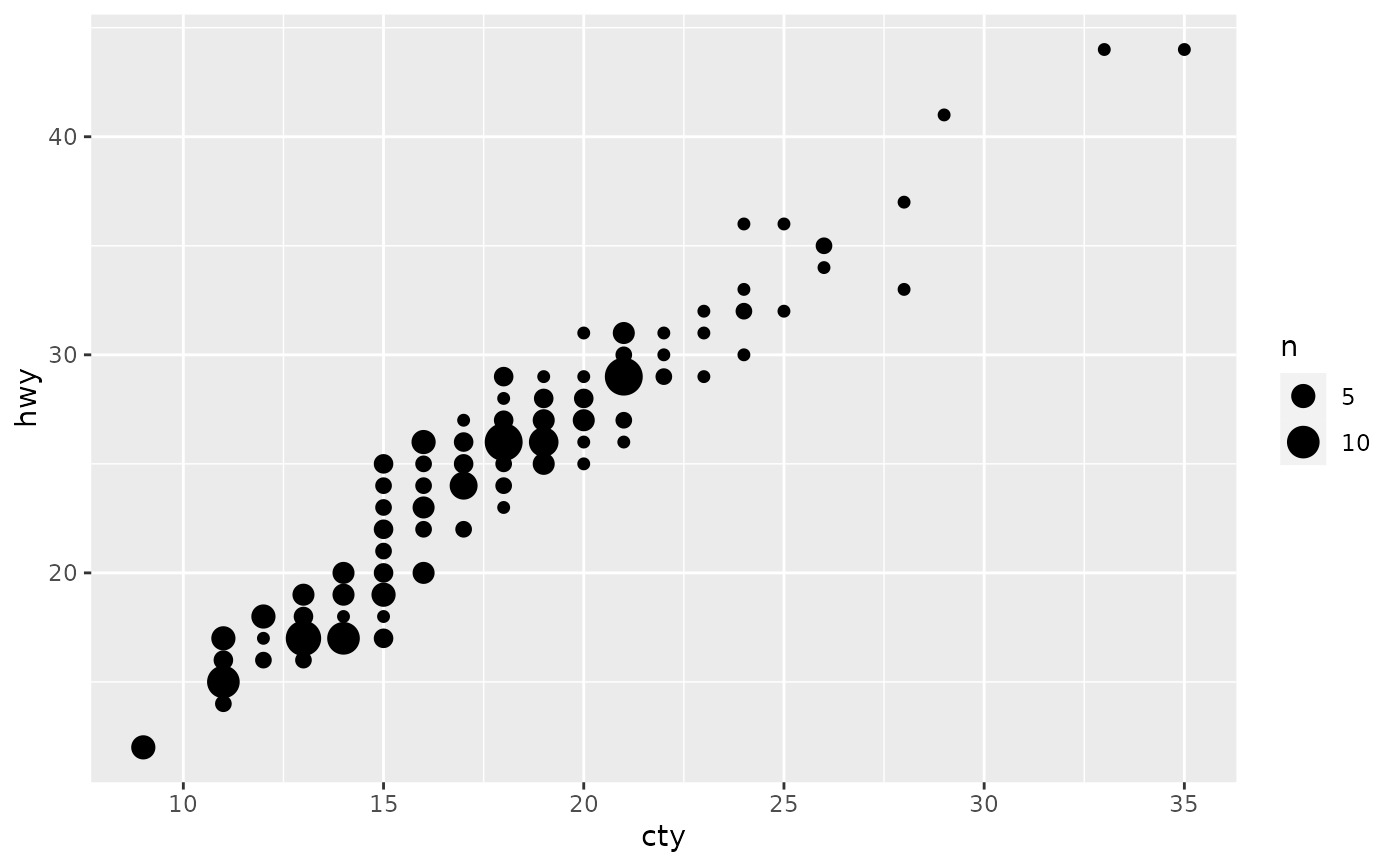 # Display proportions instead of counts -------------------------------------
# By default, all categorical variables in the plot form the groups.
# Specifying geom_count without a group identifier leads to a plot which is
# not useful:
d <- ggplot(diamonds, aes(x = cut, y = clarity))
d + geom_count(aes(size = after_stat(prop)))
# Display proportions instead of counts -------------------------------------
# By default, all categorical variables in the plot form the groups.
# Specifying geom_count without a group identifier leads to a plot which is
# not useful:
d <- ggplot(diamonds, aes(x = cut, y = clarity))
d + geom_count(aes(size = after_stat(prop)))
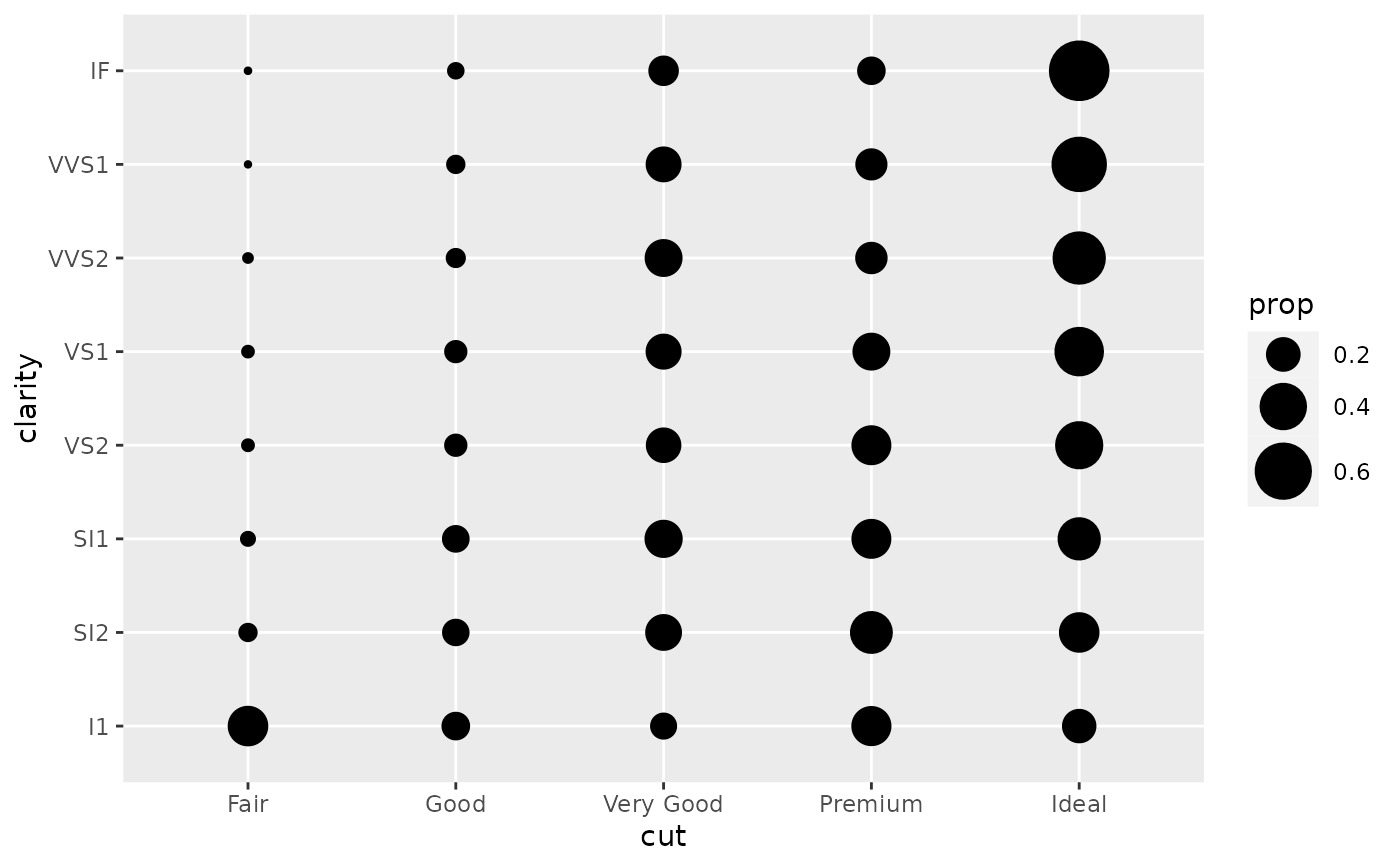
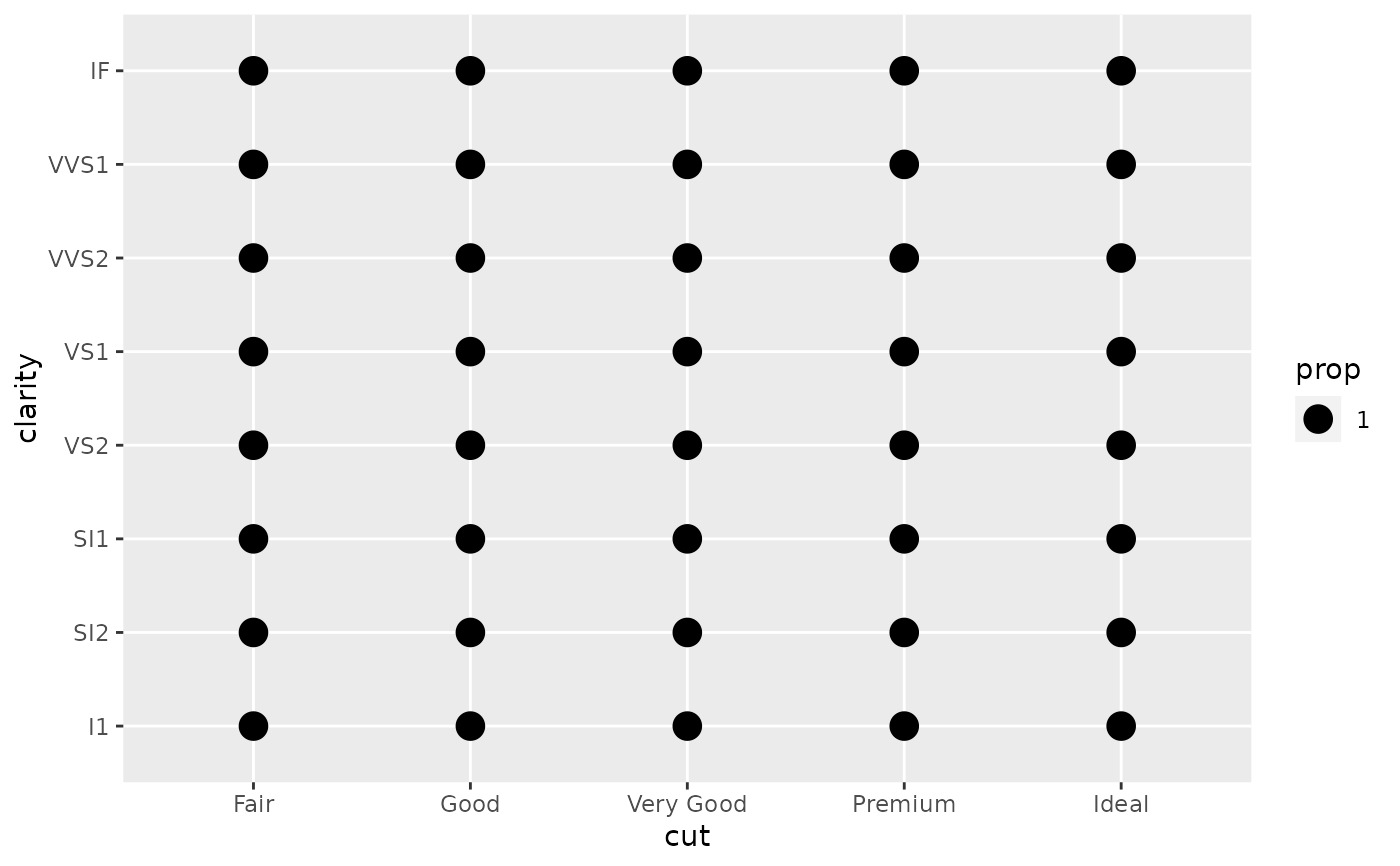 # To correct this problem and achieve a more desirable plot, we need
# to specify which group the proportion is to be calculated over.
d + geom_count(aes(size = after_stat(prop), group = 1)) +
scale_size_area(max_size = 10)
# To correct this problem and achieve a more desirable plot, we need
# to specify which group the proportion is to be calculated over.
d + geom_count(aes(size = after_stat(prop), group = 1)) +
scale_size_area(max_size = 10)
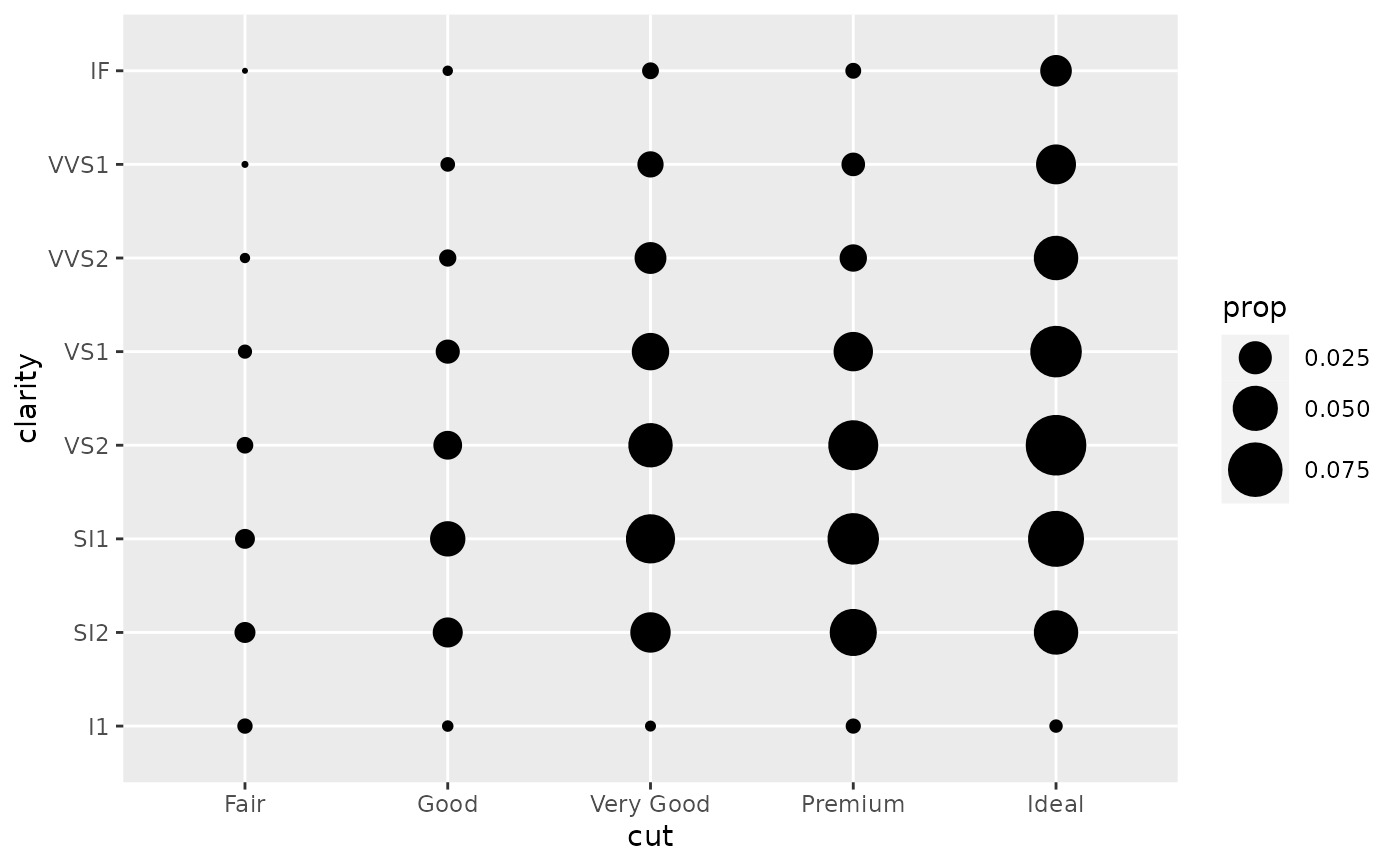 # Or group by x/y variables to have rows/columns sum to 1.
d + geom_count(aes(size = after_stat(prop), group = cut)) +
scale_size_area(max_size = 10)
# Or group by x/y variables to have rows/columns sum to 1.
d + geom_count(aes(size = after_stat(prop), group = cut)) +
scale_size_area(max_size = 10)
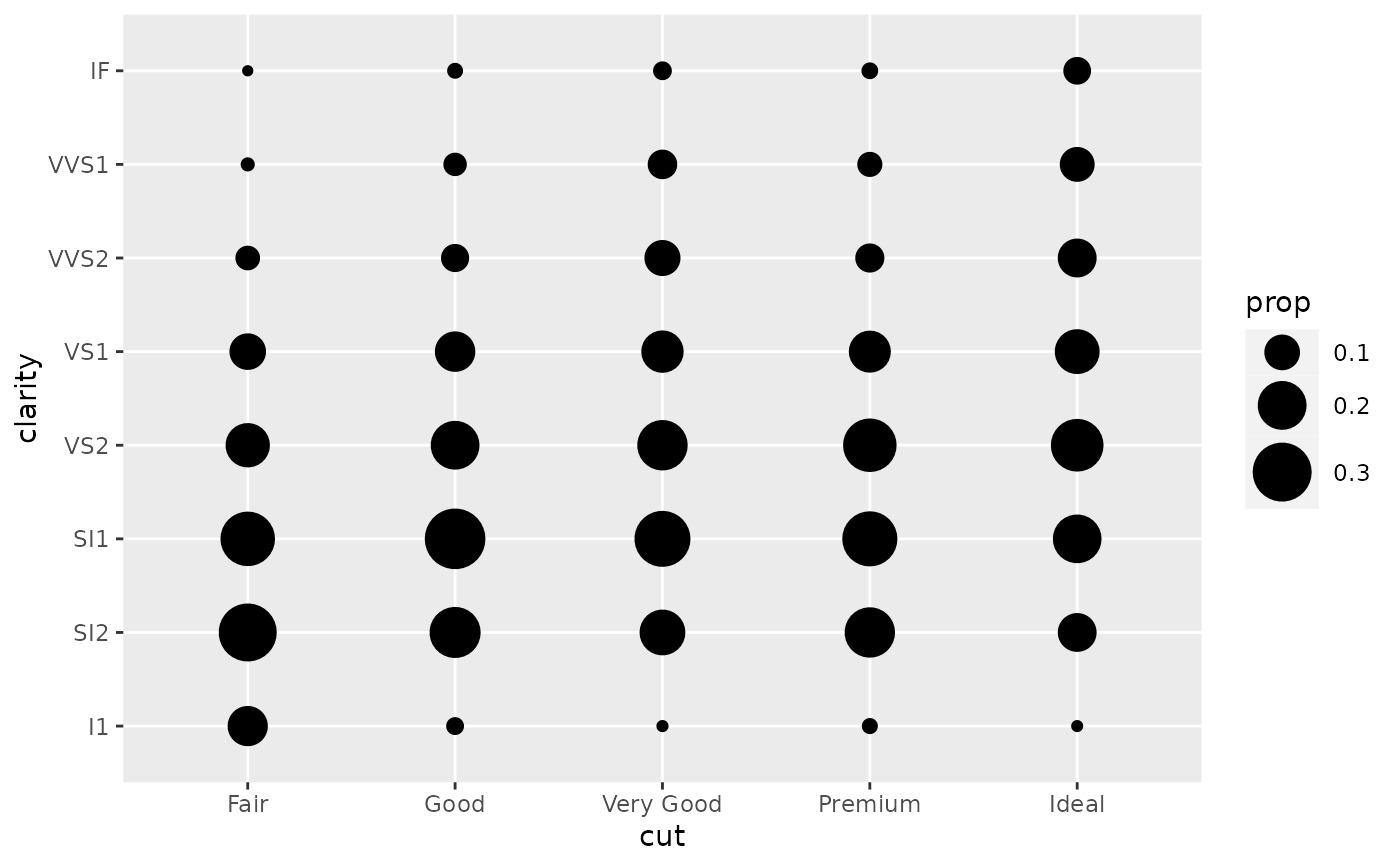 d + geom_count(aes(size = after_stat(prop), group = clarity)) +
scale_size_area(max_size = 10)
d + geom_count(aes(size = after_stat(prop), group = clarity)) +
scale_size_area(max_size = 10)
相關用法
- R ggplot2 geom_contour 3D 表麵的 2D 輪廓
- R ggplot2 geom_qq 分位數-分位數圖
- R ggplot2 geom_spoke 由位置、方向和距離參數化的線段
- R ggplot2 geom_quantile 分位數回歸
- R ggplot2 geom_text 文本
- R ggplot2 geom_ribbon 函數區和麵積圖
- R ggplot2 geom_boxplot 盒須圖(Tukey 風格)
- R ggplot2 geom_hex 二維箱計數的六邊形熱圖
- R ggplot2 geom_bar 條形圖
- R ggplot2 geom_bin_2d 二維 bin 計數熱圖
- R ggplot2 geom_jitter 抖動點
- R ggplot2 geom_point 積分
- R ggplot2 geom_linerange 垂直間隔:線、橫線和誤差線
- R ggplot2 geom_blank 什麽也不畫
- R ggplot2 geom_path 連接觀察結果
- R ggplot2 geom_violin 小提琴情節
- R ggplot2 geom_dotplot 點圖
- R ggplot2 geom_errorbarh 水平誤差線
- R ggplot2 geom_function 將函數繪製為連續曲線
- R ggplot2 geom_polygon 多邊形
- R ggplot2 geom_histogram 直方圖和頻數多邊形
- R ggplot2 geom_tile 矩形
- R ggplot2 geom_segment 線段和曲線
- R ggplot2 geom_density_2d 二維密度估計的等值線
- R ggplot2 geom_map 參考Map中的多邊形
注:本文由純淨天空篩選整理自Hadley Wickham等大神的英文原創作品 Count overlapping points。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。