本文简要介绍 python 语言中 scipy.stats.jarque_bera 的用法。
用法:
scipy.stats.jarque_bera(x, *, axis=None, nan_policy='propagate', keepdims=False)#对样本数据执行 Jarque-Bera 拟合优度检验。
Jarque-Bera 检验测试样本数据是否具有与正态分布匹配的偏度和峰度。
请注意,此检验仅适用于足够多的数据样本 (>2000),因为检验统计量渐近具有 2 个自由度的卡方分布。
- x: array_like
随机变量的观察。
- axis: int 或无,默认:无
如果是 int,则计算统计量的输入轴。输入的每个axis-slice(例如行)的统计信息将出现在输出的相应元素中。如果
None,输入将在计算统计数据之前被分解。- nan_policy: {‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入 NaN。
propagate:如果计算统计数据的轴切片(例如行)中存在NaN,则输出的相应条目将为 NaN。omit: 计算时将省略NaNs。如果计算统计数据的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。raise:如果存在 NaN,则会引发ValueError。
- keepdims: 布尔值,默认值:假
如果将其设置为 True,则缩小的轴将作为尺寸为 1 的尺寸留在结果中。使用此选项,结果将针对输入数组正确广播。
- result: SignificanceResult
具有以下属性的对象:
- 统计 浮点数
检验统计量。
- p值 浮点数
假设检验的 p 值。
参数 ::
返回 ::
注意:
从 SciPy 1.9 开始,
np.matrix输入(不建议用于新代码)在执行计算之前转换为np.ndarray。在这种情况下,输出将是标量或适当形状的np.ndarray而不是 2Dnp.matrix。同样,虽然屏蔽数组的屏蔽元素被忽略,但输出将是标量或np.ndarray而不是带有mask=False的屏蔽数组。参考:
[1]Jarque, C. 和 Bera, A. (1980) “回归残差的正态性、同方差性和序列独立性的有效检验”,6 Econometric Letters 255-259。
[2]夏皮罗,S.S. 和威尔克,M.B. (1965)。正态性方差检验分析(完整样本)。生物计量学,52(3/4),591-611。
[3]B. Phipson 和 G. K. Smyth。 “排列 P 值不应该为零:随机抽取排列时计算精确的 P 值。”遗传学和分子生物学中的统计应用 9.1 (2010)。
[4]帕纳吉奥塔科斯,D.B. (2008)。 p 值在生物医学研究中的值。开放心血管医学杂志,2, 97。
例子:
假设我们希望从测量中推断医学研究中成年男性的体重是否不服从正态分布 [2]。重量(磅)记录在下面的数组
x中。>>> import numpy as np >>> x = np.array([148, 154, 158, 160, 161, 162, 166, 170, 182, 195, 236])Jarque-Bera 测试首先根据样本偏度和峰度计算统计量。
>>> from scipy import stats >>> res = stats.jarque_bera(x) >>> res.statistic 6.982848237344646由于正态分布具有零偏度和零(“excess” 或 “Fisher”)峰度,因此对于从正态分布中抽取的样本,此统计量的值往往较低。
该检验是通过将统计量的观测值与零分布进行比较来执行的:零分布是在权重从正态分布中得出的零假设下得出的统计值的分布。对于Jarque-Bera 检验,非常大的样本的零分布是具有两个自由度的卡方分布。
>>> import matplotlib.pyplot as plt >>> dist = stats.chi2(df=2) >>> jb_val = np.linspace(0, 11, 100) >>> pdf = dist.pdf(jb_val) >>> fig, ax = plt.subplots(figsize=(8, 5)) >>> def jb_plot(ax): # we'll re-use this ... ax.plot(jb_val, pdf) ... ax.set_title("Jarque-Bera Null Distribution") ... ax.set_xlabel("statistic") ... ax.set_ylabel("probability density") >>> jb_plot(ax) >>> plt.show()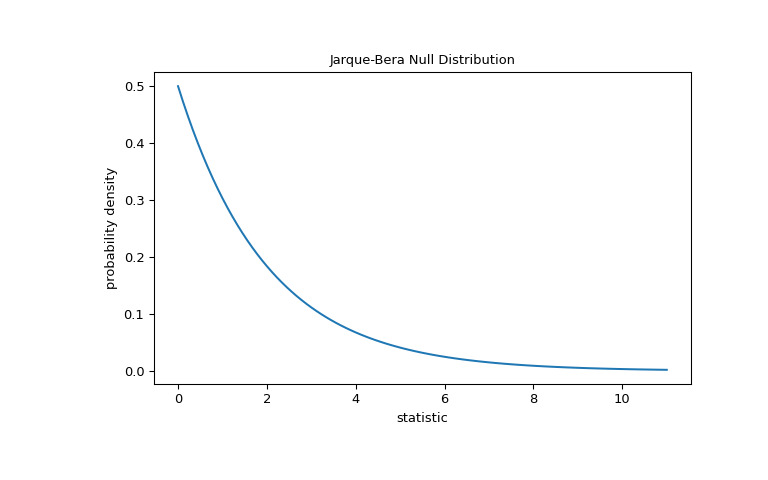
比较通过 p 值进行量化:零分布中大于或等于统计观测值的值的比例。
>>> fig, ax = plt.subplots(figsize=(8, 5)) >>> jb_plot(ax) >>> pvalue = dist.sf(res.statistic) >>> annotation = (f'p-value={pvalue:.6f}\n(shaded area)') >>> props = dict(facecolor='black', width=1, headwidth=5, headlength=8) >>> _ = ax.annotate(annotation, (7.5, 0.01), (8, 0.05), arrowprops=props) >>> i = jb_val >= res.statistic # indices of more extreme statistic values >>> ax.fill_between(jb_val[i], y1=0, y2=pdf[i]) >>> ax.set_xlim(0, 11) >>> ax.set_ylim(0, 0.3) >>> plt.show()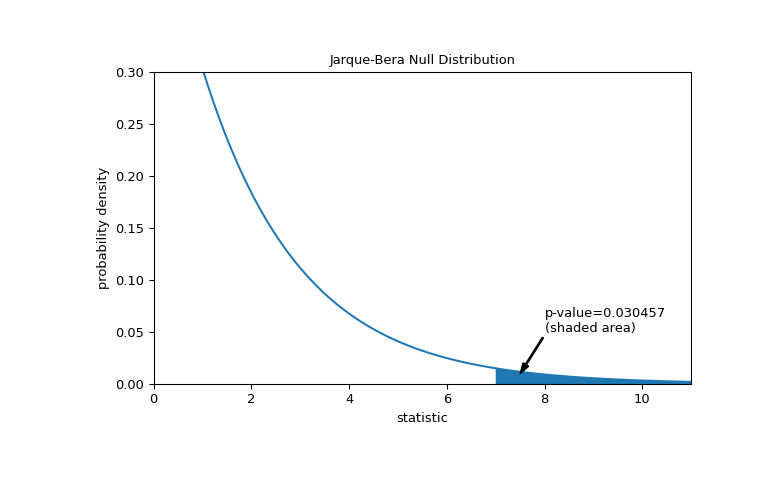
>>> res.pvalue 0.03045746622458189如果 p 值为 “small” - 也就是说,如果从正态分布总体中采样数据产生统计数据的极值的概率较低 - 这可以作为反对零假设的证据另一种选择:权重不是从正态分布中得出的。注意:
反之则不成立;也就是说,检验不用于为原假设提供证据。
将被视为 “small” 的值的阈值是在分析数据之前应做出的选择 [3],同时考虑误报(错误地拒绝原假设)和漏报(未能拒绝假设)的风险。错误的原假设)。
请注意,卡方分布提供了零分布的渐近近似;它仅对于具有许多观测值的样本是准确的。对于像我们这样的小样本,
scipy.stats.monte_carlo_test可以提供更准确的(尽管是随机的)精确 p 值的近似值。>>> def statistic(x, axis): ... # underlying calculation of the Jarque Bera statistic ... s = stats.skew(x, axis=axis) ... k = stats.kurtosis(x, axis=axis) ... return x.shape[axis]/6 * (s**2 + k**2/4) >>> res = stats.monte_carlo_test(x, stats.norm.rvs, statistic, ... alternative='greater') >>> fig, ax = plt.subplots(figsize=(8, 5)) >>> jb_plot(ax) >>> ax.hist(res.null_distribution, np.linspace(0, 10, 50), ... density=True) >>> ax.legend(['aymptotic approximation (many observations)', ... 'Monte Carlo approximation (11 observations)']) >>> plt.show()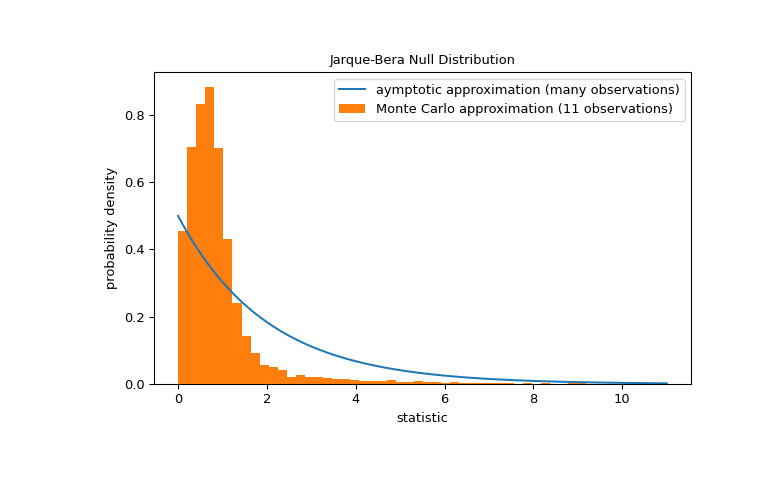
>>> res.pvalue 0.0097 # may vary此外,尽管具有随机性,以这种方式计算的 p 值可用于精确控制原假设的错误拒绝率 [4]。
相关用法
- Python SciPy stats.johnsonsu用法及代码示例
- Python SciPy stats.jf_skew_t用法及代码示例
- Python SciPy stats.johnsonsb用法及代码示例
- Python SciPy stats.anderson用法及代码示例
- Python SciPy stats.iqr用法及代码示例
- Python SciPy stats.genpareto用法及代码示例
- Python SciPy stats.skewnorm用法及代码示例
- Python SciPy stats.cosine用法及代码示例
- Python SciPy stats.norminvgauss用法及代码示例
- Python SciPy stats.directional_stats用法及代码示例
- Python SciPy stats.invwishart用法及代码示例
- Python SciPy stats.bartlett用法及代码示例
- Python SciPy stats.levy_stable用法及代码示例
- Python SciPy stats.page_trend_test用法及代码示例
- Python SciPy stats.itemfreq用法及代码示例
- Python SciPy stats.exponpow用法及代码示例
- Python SciPy stats.gumbel_l用法及代码示例
- Python SciPy stats.chisquare用法及代码示例
- Python SciPy stats.semicircular用法及代码示例
- Python SciPy stats.gzscore用法及代码示例
- Python SciPy stats.gompertz用法及代码示例
- Python SciPy stats.normaltest用法及代码示例
- Python SciPy stats.dirichlet_multinomial用法及代码示例
- Python SciPy stats.genlogistic用法及代码示例
- Python SciPy stats.skellam用法及代码示例
注:本文由纯净天空筛选整理自scipy.org大神的英文原创作品 scipy.stats.jarque_bera。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。