Broom 整理了许多列表,这些列表实际上是没有类属性的 S3 对象。例如, stats::optim() 、 svd() 和 interp::interp() 产生一致的输出,但由于它们没有类属性,因此无法由 S3 调度处理。
这些函数查看列表的元素并确定是否有适当的整理方法可应用于该列表。这些整理器作为 tidy_<function> 或 glance_<function> 形式的函数实现,并且不会导出(但它们已记录在案!)。
如果找不到合适的整理方法,它们会抛出错误。
参数
- x
-
base::svd()返回的组件u、d、v的列表。 - matrix
-
指定应整理 PCA 的哪个组件的字符。
-
"u"、"samples"、"scores"或"x":返回有关从原始空间到主成分空间的映射的信息。 -
"v"、"rotation"、"loadings"或"variables":将有关从主成分空间映射回原始空间的信息返回。 -
"d"、"eigenvalues"或"pcs":返回有关特征值的信息。
-
- ...
-
附加参数。不曾用过。仅需要匹配通用签名。注意:拼写错误的参数将被吸收到
...中,并被忽略。如果拼写错误的参数有默认值,则将使用默认值。例如,如果您传递conf.lvel = 0.9,所有计算将使用conf.level = 0.95进行。这里有两个异常:
值
tibble::tibble,其列取决于正在整理的 PCA 的组件。
如果 matrix 是 "u" 、 "samples" 、 "scores" 或 "x" ,整理输出中的每一行对应于 PCA 空间中的原始数据。这些列是:
row-
原始观察的 ID(即原始数据中的行名称)。
PC-
表示主成分的整数。
value-
该特定主成分的观察分数。即 PCA 空间中观测的位置。
如果 matrix 是 "v" 、 "rotation" 、 "loadings" 或 "variables" ,则整理输出中的每一行对应于原始空间中主成分的信息。这些列是:
row-
执行 PCA 的数据集的变量标签(列名)。
PC-
指示主成分的整数向量。
value-
指定主成分上的特征向量(轴得分)值。
如果 matrix 是 "d" 、 "eigenvalues" 或 "pcs" ,则列为:
PC-
指示主成分的整数向量。
std.dev-
此 PC 解释的标准偏差。
percent-
该分量解释的变异分数(0 到 1 之间的数值)。
cumulative-
由主要成分解释的累积变异分数,直至该成分(0 到 1 之间的数值)。
细节
有关如何解释各种整理矩阵的信息,请参阅 https://stats.stackexchange.com/questions/134282/relationship-between-svd-and-pca-how-to-use-svd-to-perform-pca。请注意,SVD 仅相当于中心数据上的 PCA。
也可以看看
其他 svd 整理器:augment.prcomp()、tidy.prcomp()、tidy_irlba()
其他列表整理器: glance_optim() 、 list_tidiers 、 tidy_irlba() 、 tidy_optim() 、 tidy_xyz()
例子
library(modeldata)
data(hpc_data)
mat <- scale(as.matrix(hpc_data[, 2:5]))
s <- svd(mat)
tidy_u <- tidy(s, matrix = "u")
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
tidy_u
#> # A tibble: 17,324 × 3
#> row PC value
#> <int> <dbl> <dbl>
#> 1 1 1 0.00403
#> 2 2 1 -0.00436
#> 3 3 1 -0.00196
#> 4 4 1 -0.00444
#> 5 5 1 -0.00437
#> 6 6 1 -0.00437
#> 7 7 1 -0.00431
#> 8 8 1 -0.00436
#> 9 9 1 -0.00434
#> 10 10 1 -0.00440
#> # ℹ 17,314 more rows
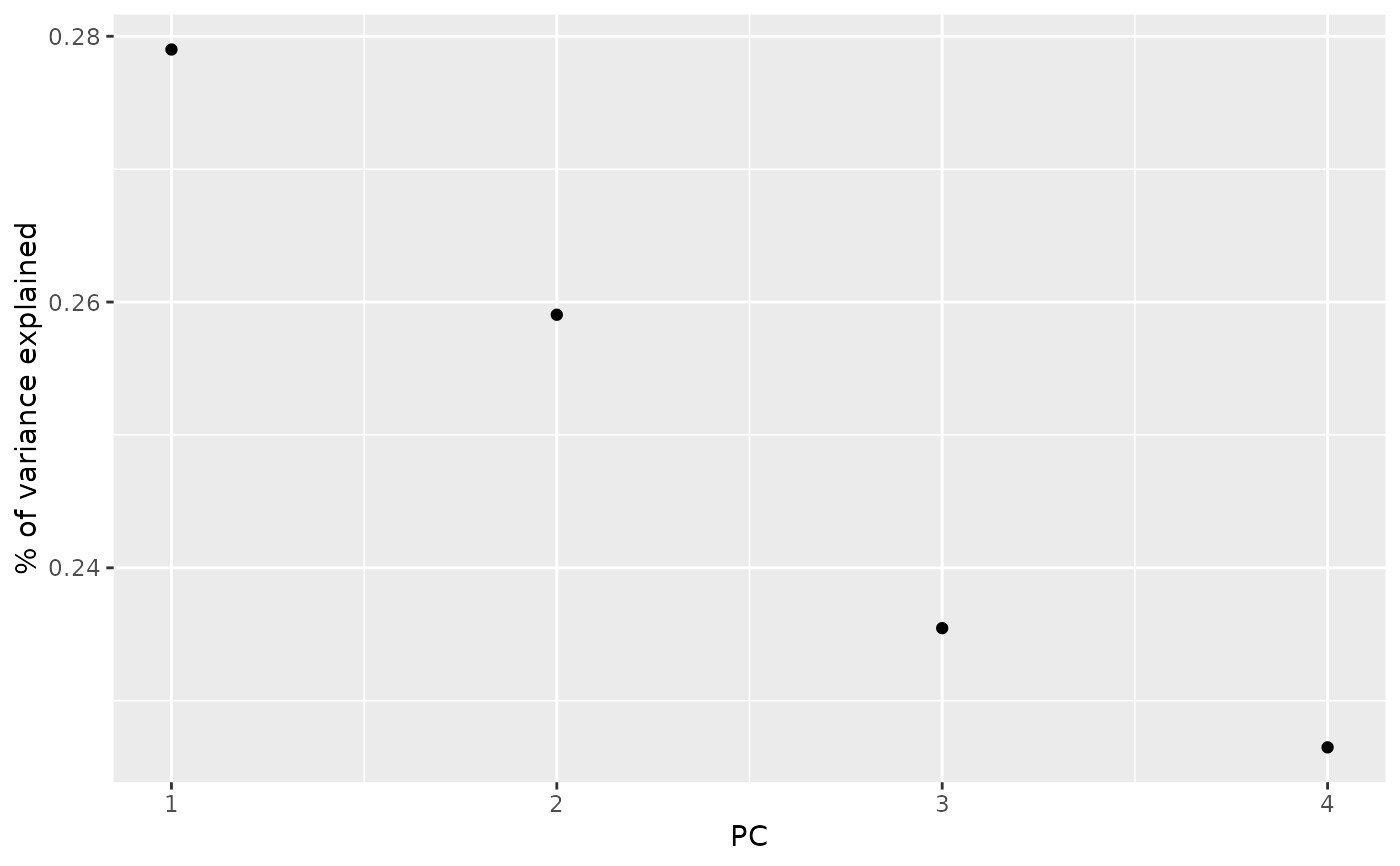
tidy_d <- tidy(s, matrix = "d")
tidy_d
#> # A tibble: 4 × 4
#> PC std.dev percent cumulative
#> <int> <dbl> <dbl> <dbl>
#> 1 1 69.5 0.279 0.279
#> 2 2 67.0 0.259 0.538
#> 3 3 63.9 0.235 0.774
#> 4 4 62.6 0.226 1
tidy_v <- tidy(s, matrix = "v")
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
tidy_v
#> # A tibble: 16 × 3
#> column PC value
#> <int> <dbl> <dbl>
#> 1 1 1 0.657
#> 2 2 1 0.409
#> 3 3 1 -0.577
#> 4 4 1 0.262
#> 5 1 2 -0.0142
#> 6 2 2 -0.650
#> 7 3 2 -0.137
#> 8 4 2 0.747
#> 9 1 3 -0.302
#> 10 2 3 -0.332
#> 11 3 3 -0.779
#> 12 4 3 -0.438
#> 13 1 4 -0.690
#> 14 2 4 0.548
#> 15 3 4 -0.205
#> 16 4 4 0.426
library(ggplot2)
library(dplyr)
ggplot(tidy_d, aes(PC, percent)) +
geom_point() +
ylab("% of variance explained")
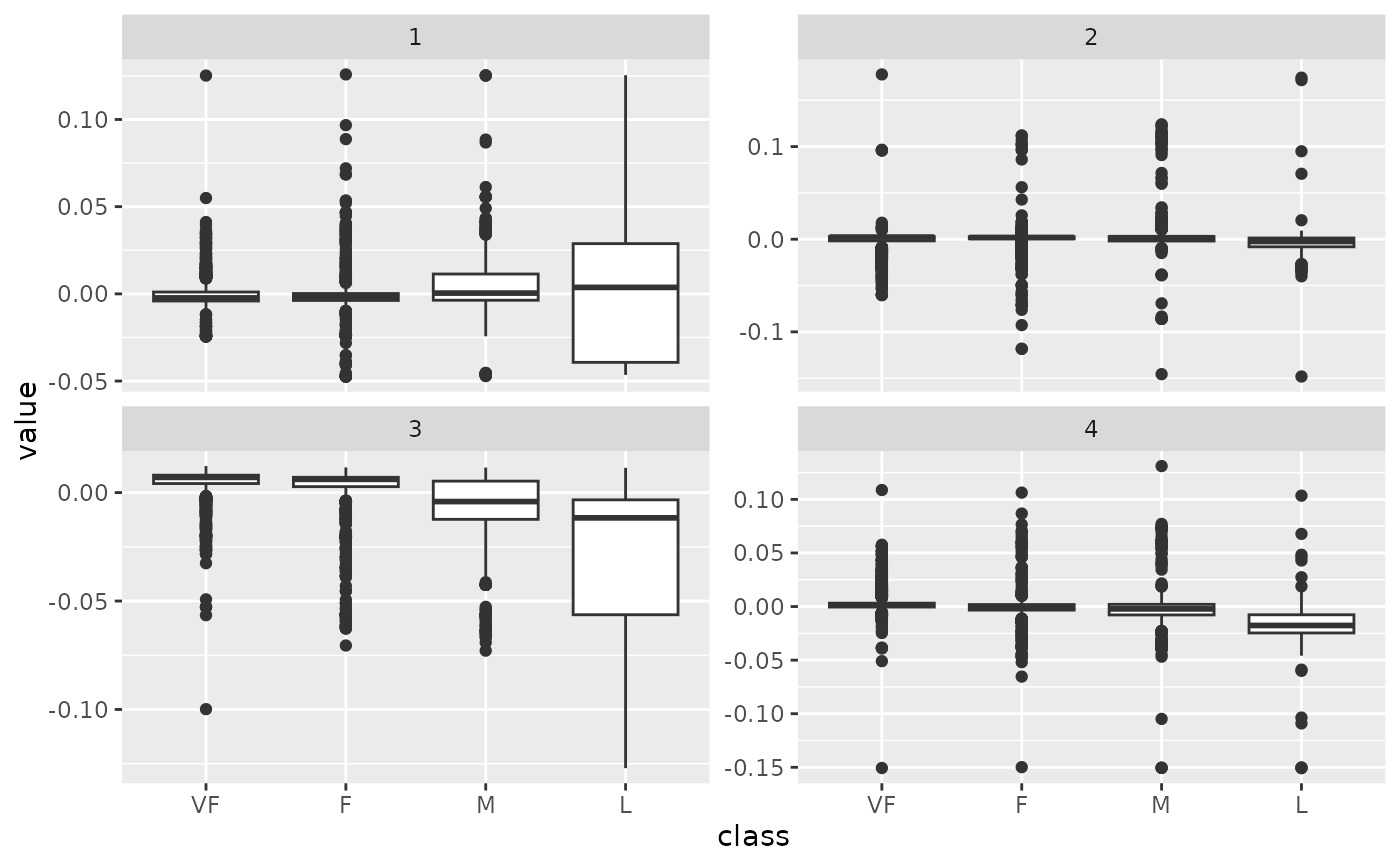
 tidy_u %>%
mutate(class = hpc_data$class[row]) %>%
ggplot(aes(class, value)) +
geom_boxplot() +
facet_wrap(~PC, scale = "free_y")
tidy_u %>%
mutate(class = hpc_data$class[row]) %>%
ggplot(aes(class, value)) +
geom_boxplot() +
facet_wrap(~PC, scale = "free_y")
相关用法
- R broom tidy_irlba 整理伪装成列表的 a(n) irlba 对象
- R broom tidy_gam_hastie 整理 a(n) Gam 对象
- R broom tidy_xyz 整理伪装成列表的 a(n) xyz 对象
- R broom tidy_optim 整理伪装成列表的 a(n) 优化对象
- R broom tidy.robustbase.glmrob 整理 a(n) glmrob 对象
- R broom tidy.acf 整理 a(n) acf 对象
- R broom tidy.robustbase.lmrob 整理 a(n) lmrob 对象
- R broom tidy.biglm 整理 a(n) biglm 对象
- R broom tidy.garch 整理 a(n) garch 对象
- R broom tidy.rq 整理 a(n) rq 对象
- R broom tidy.kmeans 整理 a(n) kmeans 对象
- R broom tidy.betamfx 整理 a(n) betamfx 对象
- R broom tidy.anova 整理 a(n) anova 对象
- R broom tidy.btergm 整理 a(n) btergm 对象
- R broom tidy.cv.glmnet 整理 a(n) cv.glmnet 对象
- R broom tidy.roc 整理 a(n) roc 对象
- R broom tidy.poLCA 整理 a(n) poLCA 对象
- R broom tidy.emmGrid 整理 a(n) emmGrid 对象
- R broom tidy.Kendall 整理 a(n) Kendall 对象
- R broom tidy.survreg 整理 a(n) survreg 对象
- R broom tidy.ergm 整理 a(n) ergm 对象
- R broom tidy.pairwise.htest 整理 a(n)pairwise.htest 对象
- R broom tidy.coeftest 整理 a(n) coeftest 对象
- R broom tidy.polr 整理 a(n) polr 对象
- R broom tidy.map 整理 a(n) Map对象
注:本文由纯净天空筛选整理自等大神的英文原创作品 Tidy a(n) svd object masquerading as list。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。