本文簡要介紹 python 語言中 scipy.stats.logrank 的用法。
用法:
scipy.stats.logrank(x, y, alternative='two-sided')#通過對數秩檢驗比較兩個樣本的生存分布。
- x, y: 數組 或 CensoredData
根據經驗生存函數進行比較的樣本。
- alternative: {‘雙麵’,‘less’, ‘greater’},可選
定義備擇假設。
原假設是兩個組(例如 X 和 Y)的生存分布是相同的。
以下替代假設 [4] 可用(默認為“雙麵”):
“雙麵”:兩組的生存分布不相同。
‘less’:X組的生存受到青睞:X組的故障率函數有時小於Y組的故障率函數。
‘greater’:Y組的生存受到青睞:X組的故障率函數有時大於Y組的故障率函數。
- res: LogRankResult
包含屬性的對象:
- 統計 浮點數數組
計算的統計量(定義如下)。它的大小是大多數其他對數秩測試實現返回的大小的平方根。
- p值 浮點數數組
測試的計算 p 值。
參數 ::
返回 ::
注意:
對數秩檢驗 [1] 在兩個樣本來自同一分布的原假設下,將觀察到的事件數與預期事件數進行比較。統計數據是
其中
表示組(即,它可以采用值 或 ,或者可以省略引用組合樣本) 表示時間(事件發生的時間), 是事件發生前處於危險中的受試者數量, 是當時觀察到的事件數量。
logrank返回的statistic是許多其他實現返回的統計信息的(帶符號)平方根。在零假設下, 根據一個自由度的卡方分布漸近分布。因此, 根據標準正態分布漸近分布。使用 的優點是保留了符號信息(即觀察到的事件數量是否傾向於小於或大於原假設下的預期數量),從而允許scipy.stats.logrank提供單方麵的替代假設。參考:
[1]Mantel N.“生存數據的評估和考慮中出現的兩個新的排名順序統計數據。”癌症化療報告,50(3):163-170,PMID:5910392,1966
[2]布蘭德·奧特曼,“The logrank test”,BMJ,328:1073,DOI:10.1136/bmj.328.7447.1073,2004 年
[3]“Logrank test”,維基百科,https://en.wikipedia.org/wiki/Logrank_test
[4]布朗、馬克. “關於對數秩檢驗的方差選擇。”生物計量學 71.1 (1984):65-74。
[5]約翰·P·克萊因 (Klein) 和梅爾文·L·莫施伯格 (Melvin L. Moeschberger)。生存分析:審查和截斷數據的技術。卷。 1230.紐約:施普林格,2003年。
例子:
參考文獻[2]比較了兩種不同類型的複發性惡性膠質瘤患者的生存時間。下麵的樣本記錄了每位患者參與研究的時間(周數)。使用
scipy.stats.CensoredData類是因為數據是right-censored:未經審查的觀察結果與觀察到的死亡相對應,而審查的觀察結果與因其他原因離開研究的患者相對應。>>> from scipy import stats >>> x = stats.CensoredData( ... uncensored=[6, 13, 21, 30, 37, 38, 49, 50, ... 63, 79, 86, 98, 202, 219], ... right=[31, 47, 80, 82, 82, 149] ... ) >>> y = stats.CensoredData( ... uncensored=[10, 10, 12, 13, 14, 15, 16, 17, 18, 20, 24, 24, ... 25, 28,30, 33, 35, 37, 40, 40, 46, 48, 76, 81, ... 82, 91, 112, 181], ... right=[34, 40, 70] ... )我們可以計算並可視化兩組的經驗生存函數,如下所示。
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> ax = plt.subplot() >>> ecdf_x = stats.ecdf(x) >>> ecdf_x.sf.plot(ax, label='Astrocytoma') >>> ecdf_y = stats.ecdf(y) >>> ecdf_x.sf.plot(ax, label='Glioblastoma') >>> ax.set_xlabel('Time to death (weeks)') >>> ax.set_ylabel('Empirical SF') >>> plt.legend() >>> plt.show()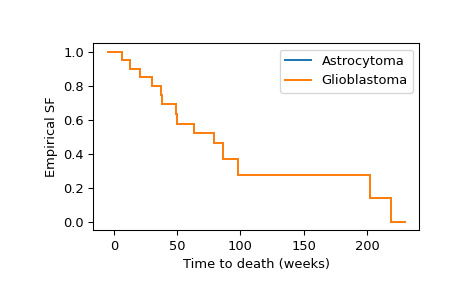
對經驗生存函數的目視檢查表明,兩組之間的生存時間往往不同。為了正式評估差異在 1% 水平上是否顯著,我們使用對數秩檢驗。
>>> res = stats.logrank(x=x, y=y) >>> res.statistic -2.73799... >>> res.pvalue 0.00618...p 值小於 1%,因此我們可以將這些數據視為反對原假設的證據,支持兩個生存函數之間存在差異的替代方案。
相關用法
- Python SciPy stats.lognorm用法及代碼示例
- Python SciPy stats.loglaplace用法及代碼示例
- Python SciPy stats.loguniform用法及代碼示例
- Python SciPy stats.logistic用法及代碼示例
- Python SciPy stats.logser用法及代碼示例
- Python SciPy stats.loggamma用法及代碼示例
- Python SciPy stats.lomax用法及代碼示例
- Python SciPy stats.levy_stable用法及代碼示例
- Python SciPy stats.laplace用法及代碼示例
- Python SciPy stats.levy_l用法及代碼示例
- Python SciPy stats.linregress用法及代碼示例
- Python SciPy stats.levene用法及代碼示例
- Python SciPy stats.levy用法及代碼示例
- Python SciPy stats.laplace_asymmetric用法及代碼示例
- Python SciPy stats.anderson用法及代碼示例
- Python SciPy stats.iqr用法及代碼示例
- Python SciPy stats.genpareto用法及代碼示例
- Python SciPy stats.skewnorm用法及代碼示例
- Python SciPy stats.cosine用法及代碼示例
- Python SciPy stats.norminvgauss用法及代碼示例
- Python SciPy stats.directional_stats用法及代碼示例
- Python SciPy stats.invwishart用法及代碼示例
- Python SciPy stats.bartlett用法及代碼示例
- Python SciPy stats.page_trend_test用法及代碼示例
- Python SciPy stats.itemfreq用法及代碼示例
注:本文由純淨天空篩選整理自scipy.org大神的英文原創作品 scipy.stats.logrank。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。