PySpark DataFrame 的 randomSplit(~) 方法使用伯努利采样将 PySpark DataFrame 随机拆分为更小的 DataFrames 列表。
randomSplit的参数
1.weights | list 共 numbers
指定分割分布的权重列表。例如,设置[0.8,0.2]将使用以下逻辑将PySpark DataFrame拆分为2个较小的DataFrames:
-
为原始 DataFrame 的每一行生成一个 0 到 1 之间的随机数。
-
我们设定了 2 个接受范围:
-
如果随机数在0到0.8之间,那么该行将被放置在第一个sub-DataFrame
-
如果随机数在0.8和1.0之间,则该行将被放置在第二个sub-DataFrame中
-
下图显示了如何执行拆分:
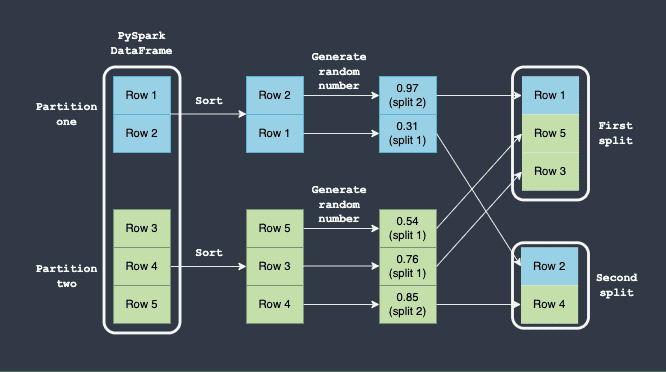
在此,请注意以下事项:
-
我们假设 PySpark DataFrame 有两个分区(蓝色和绿色)。
-
首先根据每个分区中的某些列值对行进行本地排序。这种排序保证只要每个分区中存在相同的行(无论它们的顺序如何),我们总是会得到相同的确定性顺序。
-
对于每一行,都会生成一个 0 到 1 之间的随机数。
-
第一次分割的接受范围是
0到0.8。生成的随机数在0和0.8之间的任何行都将被放置在第一个分割中。 -
第二次分割的接受范围是
0.8到1.0。生成的随机数在0.8和1.0之间的任何行都将被放置在第二个分割中。
这里重要的是,永远不能保证第一个 DataFrame 将拥有 80% 的行,而第二个 DataFrame 将拥有 20%。例如,假设为每行生成的随机数落在 0 和 0.8 之间 - 这意味着没有任何行最终会出现在第二个 DataFrame 分割中:
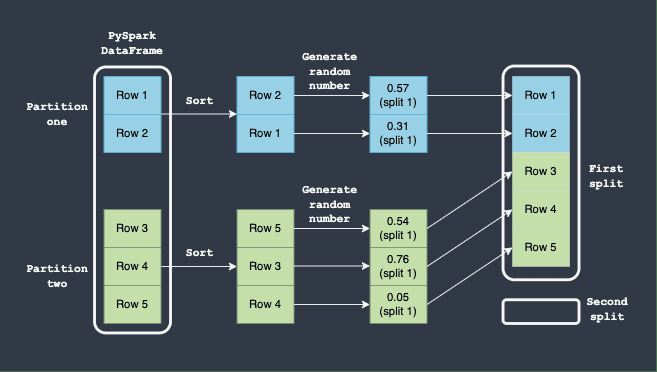
平均而言,我们应该预期第一个 DataFrame 将拥有 80% 的行,而第二个 DataFrame 将拥有 20% 的行,但实际的分割可能会非常不同。
注意
如果这些值加起来不等于 1,那么它们将被标准化。
2. seed | int | optional
使用相同的种子调用该函数将始终生成相同的结果。对此有一个警告,我们稍后会看到。
randomSplit的返回值
PySpark 数据帧的列表。
例子
考虑以下PySpark DataFrame:
df = spark.createDataFrame([["Alex", 20], ["Bob", 30], ["Cathy", 40], ["Dave", 40]], ["name", "age"])
df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 30|
|Cathy| 40|
| Dave| 40|
+-----+---+将 PySpark 数据帧随机拆分为更小的 DataFrames
将此 PySpark DataFrame 随机拆分为 2 sub-DataFrames,行拆分为 75-25:
list_dfs = df.randomSplit([0.75,0.25], seed=24)
for _df in list_dfs:
_df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
|Cathy| 40|
+-----+---+
+----+---+
|name|age|
+----+---+
| Bob| 30|
|Dave| 40|
+----+---+尽管我们预计第一个 DataFrame 包含 3 行,而第二个 DataFrame 包含 1 行,但我们看到分割是 50-50。这是因为,如上所述,randomSplit(~) 基于伯努利采样。
种子参数的怪癖
seed 参数用于再现性。例如,考虑以下PySpark DataFrame:
df = spark.createDataFrame([["Alex", 20], ["Bob", 30], ["Cathy", 40], ["Dave", 40]], ["name", "age"])
df
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 30|
|Cathy| 40|
| Dave| 40|
+-----+---+鉴于 PySpark DataFrame 以完全相同的方式分区,使用相同的种子运行 randomSplit(~) 方法将保证相同的分割:
list_dfs = df.randomSplit([0.75,0.25], seed=24)
for _df in list_dfs:
_df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
|Cathy| 40|
+-----+---+
+----+---+
|name|age|
+----+---+
| Bob| 30|
|Dave| 40|
+----+---+多次运行上述操作将始终产生相同的分割,因为 PySpark DataFrame 的分区是相同的。
我们可以通过将 DataFrame 转换为 RDD,然后使用 glom() 方法来查看 PySpark DataFrame 的行是如何分区的:
df = spark.createDataFrame([["Alex", 20], ["Bob", 30], ["Cathy", 40], ["Dave", 40]], ["name", "age"])
df.rdd.glom().collect()
[[],
[Row(name='Alex', age=20)],
[],
[Row(name='Bob', age=30)],
[],
[Row(name='Cathy', age=40)],
[],
[Row(name='Dave', age=40)]]在这里,我们看到 PySpark DataFrame 被分为 8 个分区,但其中一半是空的。
让我们使用 repartition(~) 更改分区:
df = df.repartition(2)
df.rdd.glom().collect()
[[Row(name='Alex', age=20),
Row(name='Bob', age=30),
Row(name='Cathy', age=40),
Row(name='Dave', age=40)],
[]]尽管 DataFrame 的内容相同,但我们现在只有 2 个分区,而不是 8 个分区。
让我们使用与之前相同的种子 ( 24 ) 来调用 randomSplit(~) :
list_dfs = df.randomSplit([0.75,0.25], seed=24)
for _df in list_dfs:
_df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 30|
|Cathy| 40|
| Dave| 40|
+-----+---+
+----+---+
|name|age|
+----+---+
+----+---+请注意,即使我们使用相同的种子,我们最终也会得到不同的分裂。这证实了 seed 参数仅在底层分区相同时才保证一致的分割。您应该谨慎对待这种行为,因为分区在洗牌操作后可能会发生变化(例如 join(~) 和 groupBy(~) )。
相关用法
- Python Pandas DataFrame rank方法用法及代码示例
- Python Pandas DataFrame radd方法用法及代码示例
- Python Pandas DataFrame rdiv方法用法及代码示例
- Python PySpark DataFrame repartition方法用法及代码示例
- Python PySpark DataFrame replace方法用法及代码示例
- Python PySpark DataFrame rdd属性用法及代码示例
- Python Pandas DataFrame reset_index方法用法及代码示例
- Python Pandas DataFrame reorder_levels方法用法及代码示例
- Python Pandas DataFrame rsub方法用法及代码示例
- Python Pandas DataFrame round方法用法及代码示例
- Python Pandas DataFrame resample方法用法及代码示例
- Python Pandas DataFrame reindex方法用法及代码示例
- Python Pandas DataFrame replace方法用法及代码示例
- Python Pandas DataFrame rolling方法用法及代码示例
- Python Pandas DataFrame rpow方法用法及代码示例
- Python Pandas DataFrame rfloordiv方法用法及代码示例
- Python Pandas DataFrame rtruediv方法用法及代码示例
- Python Pandas DataFrame rename_axis方法用法及代码示例
- Python Pandas DataFrame rmod方法用法及代码示例
- Python Pandas DataFrame rmul方法用法及代码示例
- Python Pandas DataFrame rename方法用法及代码示例
- Python Pandas DataFrame empty属性用法及代码示例
- Python Pandas DataFrame pop方法用法及代码示例
- Python Pandas DataFrame nsmallest方法用法及代码示例
- Python Pandas DataFrame sample方法用法及代码示例
注:本文由纯净天空筛选整理自Isshin Inada大神的英文原创作品 PySpark DataFrame | randomSplit method。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。