PySpark DataFrame 的 randomSplit(~) 方法使用伯努利采樣將 PySpark DataFrame 隨機拆分為更小的 DataFrames 列表。
randomSplit的參數
1.weights | list 共 numbers
指定分割分布的權重列表。例如,設置[0.8,0.2]將使用以下邏輯將PySpark DataFrame拆分為2個較小的DataFrames:
-
為原始 DataFrame 的每一行生成一個 0 到 1 之間的隨機數。
-
我們設定了 2 個接受範圍:
-
如果隨機數在0到0.8之間,那麽該行將被放置在第一個sub-DataFrame
-
如果隨機數在0.8和1.0之間,則該行將被放置在第二個sub-DataFrame中
-
下圖顯示了如何執行拆分:
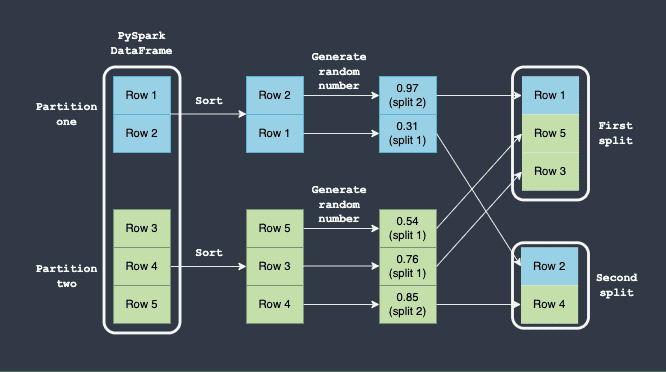
在此,請注意以下事項:
-
我們假設 PySpark DataFrame 有兩個分區(藍色和綠色)。
-
首先根據每個分區中的某些列值對行進行本地排序。這種排序保證隻要每個分區中存在相同的行(無論它們的順序如何),我們總是會得到相同的確定性順序。
-
對於每一行,都會生成一個 0 到 1 之間的隨機數。
-
第一次分割的接受範圍是
0到0.8。生成的隨機數在0和0.8之間的任何行都將被放置在第一個分割中。 -
第二次分割的接受範圍是
0.8到1.0。生成的隨機數在0.8和1.0之間的任何行都將被放置在第二個分割中。
這裏重要的是,永遠不能保證第一個 DataFrame 將擁有 80% 的行,而第二個 DataFrame 將擁有 20%。例如,假設為每行生成的隨機數落在 0 和 0.8 之間 - 這意味著沒有任何行最終會出現在第二個 DataFrame 分割中:
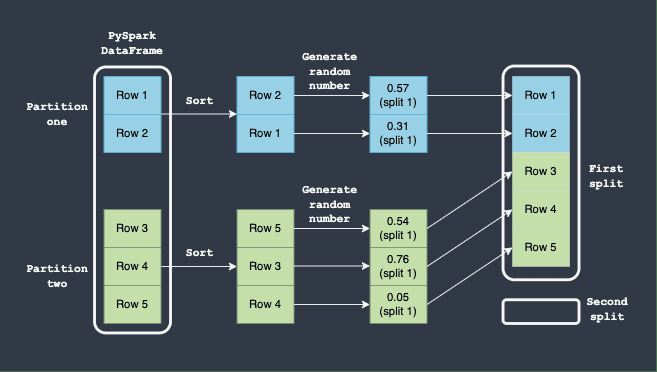
平均而言,我們應該預期第一個 DataFrame 將擁有 80% 的行,而第二個 DataFrame 將擁有 20% 的行,但實際的分割可能會非常不同。
注意
如果這些值加起來不等於 1,那麽它們將被標準化。
2. seed | int | optional
使用相同的種子調用該函數將始終生成相同的結果。對此有一個警告,我們稍後會看到。
randomSplit的返回值
PySpark 數據幀的列表。
例子
考慮以下PySpark DataFrame:
df = spark.createDataFrame([["Alex", 20], ["Bob", 30], ["Cathy", 40], ["Dave", 40]], ["name", "age"])
df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 30|
|Cathy| 40|
| Dave| 40|
+-----+---+將 PySpark 數據幀隨機拆分為更小的 DataFrames
將此 PySpark DataFrame 隨機拆分為 2 sub-DataFrames,行拆分為 75-25:
list_dfs = df.randomSplit([0.75,0.25], seed=24)
for _df in list_dfs:
_df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
|Cathy| 40|
+-----+---+
+----+---+
|name|age|
+----+---+
| Bob| 30|
|Dave| 40|
+----+---+盡管我們預計第一個 DataFrame 包含 3 行,而第二個 DataFrame 包含 1 行,但我們看到分割是 50-50。這是因為,如上所述,randomSplit(~) 基於伯努利采樣。
種子參數的怪癖
seed 參數用於再現性。例如,考慮以下PySpark DataFrame:
df = spark.createDataFrame([["Alex", 20], ["Bob", 30], ["Cathy", 40], ["Dave", 40]], ["name", "age"])
df
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 30|
|Cathy| 40|
| Dave| 40|
+-----+---+鑒於 PySpark DataFrame 以完全相同的方式分區,使用相同的種子運行 randomSplit(~) 方法將保證相同的分割:
list_dfs = df.randomSplit([0.75,0.25], seed=24)
for _df in list_dfs:
_df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
|Cathy| 40|
+-----+---+
+----+---+
|name|age|
+----+---+
| Bob| 30|
|Dave| 40|
+----+---+多次運行上述操作將始終產生相同的分割,因為 PySpark DataFrame 的分區是相同的。
我們可以通過將 DataFrame 轉換為 RDD,然後使用 glom() 方法來查看 PySpark DataFrame 的行是如何分區的:
df = spark.createDataFrame([["Alex", 20], ["Bob", 30], ["Cathy", 40], ["Dave", 40]], ["name", "age"])
df.rdd.glom().collect()
[[],
[Row(name='Alex', age=20)],
[],
[Row(name='Bob', age=30)],
[],
[Row(name='Cathy', age=40)],
[],
[Row(name='Dave', age=40)]]在這裏,我們看到 PySpark DataFrame 被分為 8 個分區,但其中一半是空的。
讓我們使用 repartition(~) 更改分區:
df = df.repartition(2)
df.rdd.glom().collect()
[[Row(name='Alex', age=20),
Row(name='Bob', age=30),
Row(name='Cathy', age=40),
Row(name='Dave', age=40)],
[]]盡管 DataFrame 的內容相同,但我們現在隻有 2 個分區,而不是 8 個分區。
讓我們使用與之前相同的種子 ( 24 ) 來調用 randomSplit(~) :
list_dfs = df.randomSplit([0.75,0.25], seed=24)
for _df in list_dfs:
_df.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 30|
|Cathy| 40|
| Dave| 40|
+-----+---+
+----+---+
|name|age|
+----+---+
+----+---+請注意,即使我們使用相同的種子,我們最終也會得到不同的分裂。這證實了 seed 參數僅在底層分區相同時才保證一致的分割。您應該謹慎對待這種行為,因為分區在洗牌操作後可能會發生變化(例如 join(~) 和 groupBy(~) )。
相關用法
- Python Pandas DataFrame rank方法用法及代碼示例
- Python Pandas DataFrame radd方法用法及代碼示例
- Python Pandas DataFrame rdiv方法用法及代碼示例
- Python PySpark DataFrame repartition方法用法及代碼示例
- Python PySpark DataFrame replace方法用法及代碼示例
- Python PySpark DataFrame rdd屬性用法及代碼示例
- Python Pandas DataFrame reset_index方法用法及代碼示例
- Python Pandas DataFrame reorder_levels方法用法及代碼示例
- Python Pandas DataFrame rsub方法用法及代碼示例
- Python Pandas DataFrame round方法用法及代碼示例
- Python Pandas DataFrame resample方法用法及代碼示例
- Python Pandas DataFrame reindex方法用法及代碼示例
- Python Pandas DataFrame replace方法用法及代碼示例
- Python Pandas DataFrame rolling方法用法及代碼示例
- Python Pandas DataFrame rpow方法用法及代碼示例
- Python Pandas DataFrame rfloordiv方法用法及代碼示例
- Python Pandas DataFrame rtruediv方法用法及代碼示例
- Python Pandas DataFrame rename_axis方法用法及代碼示例
- Python Pandas DataFrame rmod方法用法及代碼示例
- Python Pandas DataFrame rmul方法用法及代碼示例
- Python Pandas DataFrame rename方法用法及代碼示例
- Python Pandas DataFrame empty屬性用法及代碼示例
- Python Pandas DataFrame pop方法用法及代碼示例
- Python Pandas DataFrame nsmallest方法用法及代碼示例
- Python Pandas DataFrame sample方法用法及代碼示例
注:本文由純淨天空篩選整理自Isshin Inada大神的英文原創作品 PySpark DataFrame | randomSplit method。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。