PySpark DataFrame 的 join(~) 方法使用給定的連接方法連接兩個 DataFrames。
參數
1. other | DataFrame
要連接的另一個 PySpark DataFrame。
2. on | string 或 list 或 Column | optional
要執行連接的列。
3. how | string | optional
默認情況下,how="inner" 。有關實現的聯接類型,請參閱下麵的示例。
返回值
PySpark 數據幀 (pyspark.sql.dataframe.DataFrame)。
例子
執行內連接、左連接和右連接
考慮以下PySpark DataFrame:
df1 = spark.createDataFrame([["Alex", 20], ["Bob", 24], ["Cathy", 22]], ["name", "age"])
df1.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 24|
|Cathy| 22|
+-----+---+另一個PySpark DataFrame:
df2 = spark.createDataFrame([["Alex", 250], ["Bob", 200], ["Doge", 100]], ["name", "salary"])
df2.show()
+----+------+
|name|salary|
+----+------+
|Alex| 250|
| Bob| 200|
|Doge| 100|
+----+------+內部聯接
對於內部聯接,在源 DataFrame 中具有匹配值的所有行都將出現在生成的 DataFrame 中:
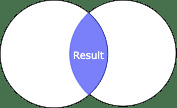
df1.join(df2, on="name", how="inner").show() # how="cross" also works
+----+---+------+
|name|age|salary|
+----+---+------+
|Alex| 20| 250|
| Bob| 24| 200|
+----+---+------+左連接和left-outer連接
對於左連接(或left-outer連接),左DataFrame中的所有行和右DataFrame中的匹配行將出現在生成的DataFrame中:
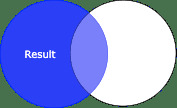
df1.join(df2, on="name", how="left").show() # how="left_outer" works
+-----+---+------+
| name|age|salary|
+-----+---+------+
| Alex| 20| 250|
| Bob| 24| 200|
|Cathy| 22| null|
+-----+---+------+右連接和right-outer連接
對於右 (right-outer) 連接,右 DataFrame 中的所有行和左 DataFrame 中的匹配行將出現在生成的 DataFrame 中:
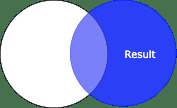
df1.join(df2, on="name", how="right").show() # how="right_outer" also works
+----+----+------+
|name| age|salary|
+----+----+------+
|Alex| 20| 250|
| Bob| 24| 200|
|Doge|null| 100|
+----+----+------+執行外連接
考慮與之前相同的 PySpark DataFrame:
df1 = spark.createDataFrame([["Alex", 20], ["Bob", 24], ["Cathy", 22]], ["name", "age"])
df1.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 24|
|Cathy| 22|
+-----+---+這是另一個PySpark DataFrame:
df2 = spark.createDataFrame([["Alex", 250], ["Bob", 200], ["Doge", 100]], ["name", "salary"])
df2.show()
+----+------+
|name|salary|
+----+------+
|Alex| 250|
| Bob| 200|
|Doge| 100|
+----+------+對於外連接,左和右 DataFrames 都會出現:

df1.join(df2, on="name", how="outer").show() # how="full" or "fullouter" also works
+-----+----+------+
| name| age|salary|
+-----+----+------+
| Alex| 20| 250|
| Bob| 24| 200|
|Cathy| 22| null|
| Doge|null| 100|
+-----+----+------+執行 left-anti 和 left-semi 連接
考慮與之前相同的 PySpark DataFrame:
df1 = spark.createDataFrame([["Alex", 20], ["Bob", 24], ["Cathy", 22]], ["name", "age"])
df1.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 24|
|Cathy| 22|
+-----+---+這是另一個 DataFrame :
df2 = spark.createDataFrame([["Alex", 250], ["Bob", 200], ["Doge", 100]], ["name", "salary"])
df2.show()
+----+------+
|name|salary|
+----+------+
|Alex| 250|
| Bob| 200|
|Doge| 100|
+----+------+左反連接
對於左反連接,左側 DataFrame 中不存在於右側 DataFrame 中的所有行都將出現在生成的 DataFrame 中:
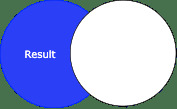
df1.join(df2, on="name", how="left_anti").show() # how="leftanti" also works
+-----+---+
| name|age|
+-----+---+
|Cathy| 22|
+-----+---+左semi-join
左 semi-join 與 left-anti 連接相反,即左 DataFrame 中存在於右 DataFrame 中的所有行都將出現在生成的 DataFrame 中:
df1.join(df2, on="name", how="left_semi").show() # how="leftsemi" also works
+----+---+
|name|age|
+----+---+
|Alex| 20|
| Bob| 24|
+----+---+對不同的列名執行連接
到目前為止,我們已經使用on參數指定了連接鍵。現在讓我們考慮連接鍵具有不同標簽的情況。假設一個DataFrame如下:
df1 = spark.createDataFrame([["Alex", 20], ["Bob", 24], ["Cathy", 22]], ["name", "age"])
df1.show()
+-----+---+
| name|age|
+-----+---+
| Alex| 20|
| Bob| 24|
|Cathy| 22|
+-----+---+假設另一個DataFrame如下:
df2 = spark.createDataFrame([["Alex", 250], ["Bob", 200], ["Doge", 100]], ["NAME", "salary"])
df2.show()
+----+------+
|NAME|salary|
+----+------+
|Alex| 250|
| Bob| 200|
|Doge| 100|
+----+------+我們可以使用 df1 的 name 和 df2 的 NAME 加入,如下所示:
cond = [df1["name"] == df2["NAME"]]
df1.join(df2, on=cond, how="inner").show()
+----+---+----+------+
|name|age|NAME|salary|
+----+---+----+------+
|Alex| 20|Alex| 250|
| Bob| 24| Bob| 200|
+----+---+----+------+在這裏,我們可以提供多個連接鍵,因為 on 接受一個列表。
相關用法
- Python Pandas DataFrame join方法用法及代碼示例
- Python Pandas DataFrame empty屬性用法及代碼示例
- Python Pandas DataFrame pop方法用法及代碼示例
- Python Pandas DataFrame nsmallest方法用法及代碼示例
- Python Pandas DataFrame sample方法用法及代碼示例
- Python Pandas DataFrame items方法用法及代碼示例
- Python Pandas DataFrame max方法用法及代碼示例
- Python Pandas DataFrame swaplevel方法用法及代碼示例
- Python Pandas DataFrame agg方法用法及代碼示例
- Python Pandas DataFrame copy方法用法及代碼示例
- Python Pandas DataFrame pow方法用法及代碼示例
- Python Pandas DataFrame insert方法用法及代碼示例
- Python Pandas DataFrame lt方法用法及代碼示例
- Python Pandas DataFrame all方法用法及代碼示例
- Python Pandas DataFrame unstack方法用法及代碼示例
- Python Pandas DataFrame mean方法用法及代碼示例
- Python PySpark DataFrame filter方法用法及代碼示例
- Python Pandas DataFrame tz_convert方法用法及代碼示例
- Python Pandas DataFrame isin方法用法及代碼示例
- Python PySpark DataFrame collect方法用法及代碼示例
- Python PySpark DataFrame intersect方法用法及代碼示例
- Python PySpark DataFrame dtypes屬性用法及代碼示例
- Python Pandas DataFrame rank方法用法及代碼示例
- Python Pandas DataFrame tail方法用法及代碼示例
- Python Pandas DataFrame transform方法用法及代碼示例
注:本文由純淨天空篩選整理自Isshin Inada大神的英文原創作品 PySpark DataFrame | join method。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。