下面是章节基础统计的目录(其他内容参见全文目录)
- 汇总统计(Summary statistics)
- 相关系数(Correlations)
- 分层抽样(Stratified sampling)
- 假设检验(Hypothesis testing)
- 随机数据生成(Random data generation)
汇总统计(Summary statistics)
使用Statistics中的colStats方法,我们可以对RDD[Vector]做列汇总统计。
在Python中,colStats() 返回MultivariateStatisticalSummary的实例,它包括按列计算的最大值、最小值、平均值、方差、非0值数量以及总数。
from pyspark.mllib.stat import Statistics
sc = ... # SparkContext
mat = ... # an RDD of Vectors
# Compute column summary statistics.
summary = Statistics.colStats(mat)
print summary.mean()
print summary.variance()
print summary.numNonzeros()相关系数(Correlations)
计算两个序列的相关性是统计中的一个常用操作。MLlib为计算多种序列之间的相关性提供了足够的灵活度。当前支持的关联计算方法是Pearson和Spearman相关系数。
注:Pearson相关系数表达的是两个数值变量的线性相关性, 它一般适用于正态分布。其取值范围是[-1, 1], 当取值为0表示不相关,取值为(0~-1]表示负相关,取值为(0, 1]表示正相关。例如有趣的实验:人的收入和看电视时长相关性调查,就可以使用Pearson相关系数来度量。其常用的计算公式为:
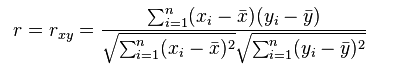
其中, xi/yi是变量值,n是样本数量。带上划线的x, y分别是所有xi和yi的均值。
Spearman相关系数也用来表达两个变量的相关性,但是它没有Pearson相关系数对变量的分布要求那么严格,另外Spearman相关系数可以更好地用于测度变量的排序关系。例如:Pearson适用于衡量一个班级语文成绩和数学成绩的关系,Spearman适用于衡量语文成绩排名和数学成绩排名的关系。Spearman相关系数可以认为是等级变量之间的相关系数。其计算公式为:
![]()
类 Statistics 提供了计算序列之间相关性的计算方法。依赖于输入的类型,两个RDD[Double]或者一个RDD[Vector],输出分别是Double或者相关性矩阵。
from pyspark.mllib.stat import Statistics
sc = ... # SparkContext
seriesX = ... # a series
seriesY = ... # must have the same number of partitions and cardinality as seriesX
# Compute the correlation using Pearson's method. Enter "spearman" for Spearman's method. If a
# method is not specified, Pearson's method will be used by default.
print Statistics.corr(seriesX, seriesY, method="pearson")
data = ... # an RDD of Vectors
# calculate the correlation matrix using Pearson's method. Use "spearman" for Spearman's method.
# If a method is not specified, Pearson's method will be used by default.
print Statistics.corr(data, method="pearson")
分层抽样(Stratified sampling)
跟其他的统计方法不一样,MLlib中的分层抽样方法:sampleByKey和sampleByKeyExact,可以在包含key-value对的RDD上执行。对分层抽样来说,key可以认为是标签而value是特定的属性。例如,key可以是男人、女人或者文档ID,相应的values就是人群中人的年龄序列或者文档中的单词序列。方法sampleByKey会像抛硬币一样去判断每个实例是否被抽出,因此需要遍历一次数据,并且需要提供一个期望的样本大小。sampleByKeyExact比sampleByKey的每层简单随机抽样需要更多的资源,但是在抽样大小上有99.99%的准确度。不过sampleByKeyExact目前在python中不支持。
sampleByKey()允许用户抽取大约 ⌈fk⋅nk⌉∀k∈K 个样本,其中fk是希望对k(键)抽取的比例,nk是k(键)中的key-value对数量,K是key(键)集合。
sc = ... # SparkContext
fractions = {"a": 0.2, "b": 0.1, "c": 0.2, ...}
data = ... # an RDD of any key(a/b/c...) value pairs
fractions = ... # specify the exact fraction desired from each key as a dictionary
approxSample = data.sampleByKey(False, fractions);假设检验(Hypothesis testing)
假设检验是一个强大的统计工具,它可以用来判断一个事件是否有显剧的统计特征,以及这个事件是不是偶然发生的。MLlib当前支持用于判断拟合度或者独立性的Pearson卡方(chi-squared ( χ2) )检验。不同的输入类型决定了是做拟合度检验还是独立性检验。拟合度检验要求输入为Vector, 独立性检验要求输入是Matrix。
MLlib也支持输入类型是RDD[LabeledPoint]时,通过卡方独立性检验做特征选择。
类 Statistics 提供了进行Pearson卡方检验的方法。下面的例子展示了怎样运行和解释假设检验。
from pyspark import SparkContext
from pyspark.mllib.linalg import Vectors, Matrices
from pyspark.mllib.regresssion import LabeledPoint
from pyspark.mllib.stat import Statistics
sc = SparkContext()
vec = Vectors.dense(...) # a vector composed of the frequencies of events
# compute the goodness of fit. If a second vector to test against is not supplied as a parameter,
# the test runs against a uniform distribution.
goodnessOfFitTestResult = Statistics.chiSqTest(vec)
print goodnessOfFitTestResult # summary of the test including the p-value, degrees of freedom,
# test statistic, the method used, and the null hypothesis.
mat = Matrices.dense(...) # a contingency matrix
# conduct Pearson's independence test on the input contingency matrix
independenceTestResult = Statistics.chiSqTest(mat)
print independenceTestResult # summary of the test including the p-value, degrees of freedom...
obs = sc.parallelize(...) # LabeledPoint(feature, label) .
# The contingency table is constructed from an RDD of LabeledPoint and used to conduct
# the independence test. Returns an array containing the ChiSquaredTestResult for every feature
# against the label.
featureTestResults = Statistics.chiSqTest(obs)
for i, result in enumerate(featureTestResults):
print "Column $d:" % (i + 1)
print result随机数据生成(Random data generation)
随机数据生成在随机算法、原型开发、性能测试中比较有用。MLlib支持生成的随机的RDD[(int, int, double)],数据服从下列分别:均匀分布、标准正态分布、泊松分布。
类RandomRDDs 提供了工厂方法来生成随机的RDD[double]或者RDD[vector]。下面的代码中,生成了一个RDD[double], 它服从标准正态分布,然后转成了N(1, 4)分布。
from pyspark.mllib.random import RandomRDDs
sc = ... # SparkContext
# Generate a random double RDD that contains 1 million i.i.d. values drawn from the
# standard normal distribution `N(0, 1)`, evenly distributed in 10 partitions.
u = RandomRDDs.uniformRDD(sc, 1000000L, 10)
# Apply a transform to get a random double RDD following `N(1, 4)`.
v = u.map(lambda x: 1.0 + 2.0 * x)参考:
[1] http://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient
[2] http://zh.wikipedia.org/wiki/%E6%96%AF%E7%9A%AE%E5%B0%94%E6%9B%BC%E7%AD%89%E7%BA%A7%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0