下面是章节优化的目录(参见全文目录)
数学描述
梯度下降
解决这类函数 minw∈Rdf(w) 优化问题的最简单方法是 梯度下降(gradient descent)。这样的一阶优化方法(包括梯度下降和随机梯度下降)非常适合大规模分布式计算。
梯度下降法旨在下降最快的方向进行迭代从而找到局部最小值。这个最快的方向是函数当前点的负导数(也叫梯度)。如果目标函数f对所有参数不可导,但具有凸函数性质,那么可以使用次梯度(次梯度是梯度的一种自然泛化)来扮演下降方向的角色。不管哪种情况,计算函数f的梯度或者次梯度开销都比较大——因为需要遍历整个数据集,从而计算所有损失项的贡献。
随机梯度下降 (SGD)
求和形式的目标函数f的优化问题特别适合使用随机梯度下降法(SGD)求解。通常在有监督机器学习中使用的优化公式:
 这个公式看起来很自然,因为损失的计算方式是请求每个独立数据点损失的平均值。
这个公式看起来很自然,因为损失的计算方式是请求每个独立数据点损失的平均值。
随机次梯度是在向量上做一个随机选择,从而在期望上来看,我们获得了原始目标函数的真正次梯度。具体方法是:一致性随机抽样一个数据点i∈[1..n] ,我们可以通过下面式子获得目标函数(1)中的次梯度:
 其中
其中 L′w,i∈Rd是在第i个点处,损失函数的次梯度,也就是说,
![]() 另外,
另外,R′w 是正则化R(w)的次梯度,
![]() 并且,
并且,R′w 不依赖于随机选择的样本点。显然,在随机选择的点i∈[1..n]上,我们获得了f′w,i,它是原始目标函数f的次梯度,亦即:
![]() 有了梯度公式之后,SGD就可以简单地按负随机次梯度
有了梯度公式之后,SGD就可以简单地按负随机次梯度f′w,i的方向前进就可以了,即:
![]()
Step-size(步长). 参数γ就是步长(Step-size)。在默认实现中,步长迭代次数平方根的增大而减小:γ = s / sqrt(t),其中s是输入参数stepSize,t是表示的是第t次迭代。注意SGD最好步长的选择实际上比较微妙,是个热门研究课题。
Gradients(梯度). MLlib中实现的机器学习方法的梯度列表可以在章节分类和回归[Classification and regression]看到。
Proximal Updates(近似更新). 作为在前进方向上使用正则化梯度 R′(w) 的另一种选择,一种通过使用近似操作的改进更新方法可以应用于某些场景。对于L1正则化,近似操作是软阈值法(soft thresholding)[signum(w) * max(0.0, abs(w) – shrinkageVal) ],这个在 L1Updater中实现,这种方法可以是产生的w具有更好的稀疏性。
分布式SGD的更新机制
GradientDescent中实现的SGD对样本数据使用了一种简单的分布式抽样。回想一下公式(1)的优化问题,其中的损失函数部分为:
![]()
miniBatchFraction来指定使用部分数据替代使用全部数据。在这个子集上的平均梯度如下: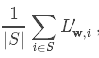
因为自己是随机抽样的,所以这是个随机梯度。其中S是抽样的自己,大小|S|=miniBatchFraction ×n。在每一轮迭代中,RDD上的抽样以及对每个worker机器部分结果的求和计算都由标砖spark程序完成。
如果将miniBatchFraction置为1,那么每一轮迭代中都使用准确梯度下降。这种情况下,在前进方向上就没有了随机性和差异。另外一种极端情况下,如果minBatchFraction设置得太小,比如只有一个点被抽样出来,也就是|S|= miniBatchFraction×n=1,那么算法就变成了标准的SGD。这种情况下,前进方向取决于数据点的一致性随机抽样。
有限内存BFGS (L-BFGS)
L-BFGS 是拟牛顿法家族的一员,用来解决函数 minw∈Rdf(w) 的优化问题。L-BFGS算法对目标函数做局部近似,它不需要求目标函数第二部分的导数来构造Hession矩阵。Hessian矩阵通过上一步的梯度来估值,因而使用牛顿法计算Hession矩阵没有垂直扩展问题(训练特征的数量)。所以,L-BFGS比其他一阶优化方法收敛更快。
补充:
牛顿法收敛速度快,但是计算过程中需要计算目标函数的二阶偏导数,难度较大;目标函数的Hessian矩阵无法保持正定,从而令牛顿法失效。
为了解决这两个问题,人们提出了拟牛顿法,即“模拟”牛顿法的改进型算法。基本思想是不用二阶偏导数而构造出可以近似Hessian矩阵的逆的正定对称阵,从而在“拟牛顿”的条件下优化目标函数。Hessian阵的构造方法的不同决定了不同的拟牛顿法。
选择优化方法
线性方法 会在内部使用优化算法,MLlib中的部分线性方法支持SGD和L-BFGS。不同的优化方法会有不同的收敛速度保障,这依赖于目标函数的特点,这里不讨论这个问题。通常,如果L-BFGS是可用的,为了更快的收敛(更少的迭代),建议使用L-BFGS而不是SGD。
MLlib中的实现
梯度下降和随机梯度下降
梯度下降包括随机梯度下降(SGD)作为MLlib中的底层原语,各种ML算法都会用到,可以参考:线性方法 章节中的例子。
SGD类GradientDescent 有下列参数:
Gradient 计算待优化函数随机梯度的类。也就是给定单个训练样本以及当前的参数值,计算随机梯度。MLlib包含了常用损失函数的梯度类,这些损失函数可以是:hinge, logistic, least-squares等。梯度类的输入是训练样本,样本标记以及当前的参数。Updater实际执行梯度下降步骤的类。也就是给定损失部分的梯度,在每轮迭代中更新权值。Updater也负责正则化部分的更新。MLlib中的更新可以支持:不做正则化,L1正则化,L2正则化。stepSize梯度下降的初始步长。Updater在第t步使用的步长是stepSize/sqrt(t)。numIterations迭代次数。regParam使用L1或L2时的正则化参数。miniBatchFraction 每轮迭代中抽取的用于梯度计算的数据比例。- 抽样也需要遍历整个RDD,所以减小miniBatchFraction不一定会大幅提升优化速度。如果梯度计算开销很大时,使用抽样的方法计算梯度会有可观的性能提升。
L-BFGS
L-BFGS当前只是MLlib中的底层优化原语。如果需要在不同的机器学习算法(例如线性回归、逻辑回归)使用L-BFGS,需要自己传入目标函数的梯度以及Updater,这个跟直接使用LogisticRegressionWithSGD的API不一样。下一个版本会发布L-BFGS比较完备的优化功能。
L1Updater使用的L1正则化当前在L-BFGS中不可用,因为L1Updater中的软阈值(soft-thresholding)是为梯度下降设计的。参见开发者注意事项。
L-BFGS方法LBFGS.runLBFGS有下列参数:
Gradient计算待优化函数随机梯度的类。也就是给定单个训练样本以及当前的参数值,计算随机梯度。MLlib包含了常用损失函数的梯度类,这些损失函数可以是:hinge, logistic, least-squares等。梯度类的输入是训练样本,样本标记以及当前的参数。Updater为L-BFGS计算损失函数和正则化梯度的类。目前支持无正则化和L2正则化。numCorrections用在L-BFGS更新中的修正次数。推荐10。maxNumIterations 最大迭代次数。regParam正则化参数。convergenceTol收敛阈值。这个值必须是非负的。值越小越严格,通常会导致更多的迭代次数。在Breeze LBFGS中这个值涉及到平均提升和梯度范数。
该函数的返回值是二个元素的元组。第一个元素是包含每个特征权值的列矩阵,第二个元素是包含每次迭代损失的数组。
下面是用来训练二分逻辑会就的例子(Scala),使用了L2正则化以及L-BFGS优化器。
import org.apache.spark.SparkContext
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.mllib.classification.LogisticRegressionModel
import org.apache.spark.mllib.optimization.{LBFGS, LogisticGradient, SquaredL2Updater}
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
val numFeatures = data.take(1)(0).features.size
// Split data into training (60%) and test (40%).
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
// Append 1 into the training data as intercept.
val training = splits(0).map(x => (x.label, MLUtils.appendBias(x.features))).cache()
val test = splits(1)
// Run training algorithm to build the model
val numCorrections = 10
val convergenceTol = 1e-4
val maxNumIterations = 20
val regParam = 0.1
val initialWeightsWithIntercept = Vectors.dense(new Array[Double](numFeatures + 1))
val (weightsWithIntercept, loss) = LBFGS.runLBFGS(
training,
new LogisticGradient(),
new SquaredL2Updater(),
numCorrections,
convergenceTol,
maxNumIterations,
regParam,
initialWeightsWithIntercept)
val model = new LogisticRegressionModel(
Vectors.dense(weightsWithIntercept.toArray.slice(0, weightsWithIntercept.size - 1)),
weightsWithIntercept(weightsWithIntercept.size - 1))
// Clear the default threshold.
model.clearThreshold()
// Compute raw scores on the test set.
val scoreAndLabels = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
// Get evaluation metrics.
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Loss of each step in training process")
loss.foreach(println)
println("Area under ROC = " + auROC)开发者注意事项
因为Hessian矩阵是通过对之前梯度的评估值来近似构建的,所以目标函数在优化过程中不能修改。也就是说,使用miniBatch的随机L-BFGS不能天然正常工作,因此,在有更好的解决方案之前我们不提供随机L-BFGS这个功能。
Updater原来只是是为梯度下降计算设计的类。然而,我们可以将损失函数和正则化的梯度计算用于L-BFGS,不过要忽略掉只针对梯度将下降部分的逻辑(例如:自适应步长功能)。We will refactorize this into regularizer to replace updater to separate the logic between regularization and step update later.
参考:
[1] http://blog.sina.com.cn/s/blog_5f234d47010162f7.html