本指南介绍如何在TensorFlow中编程。在使用本指南之前,请安装TensorFlow。为了充分利用本指南,您应该了解以下内容:
- 如何使用Python编程。
- 了解什么是数组。
- 理想的条件,了解机器学习。但是,如果您对机器学习知之甚少,那么这仍然可以是您应该阅读的一本指南。
TensorFlow提供了多个API,其中最底层的API ———— TensorFlow核心 – 为您提供完整的编程控制。TensorFlow Core适用于机器学习研究人员和其他需要对模型进行精细控制的开发者。更高层次的API建立在TensorFlow核心之上。这些更高级别的API通常比TensorFlow Core更容易学习和使用。另外,更高级别的API使得不同用户之间的重复任务更容易和更一致。像tf.estimator这样的high-level API可以帮助您管理数据集,评估,训练和推理。
本指南从TensorFlow Core教程开始。稍后,我们演示如何在tf.estimator中实现相同的模型。了解TensorFlow核心原则将给你一个很好的思维模型,即当你使用更紧凑的更高级别的API时,知道模型内部工作是如何工作的。
张量
TensorFlow中的数据中心单位是张量。一个张量由一组任意维数的原始值组成。张量的秩(rank)是它的维数。这里是一些张量的例子:
3 # a rank 0 tensor; a scalar with shape []
[1., 2., 3.] # a rank 1 tensor; a vector with shape [3]
[[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix with shape [2, 3]
[[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor with shape [2, 1, 3]
TensorFlow Core教程
导入Tensorflow
TensorFlow程序的规范导入语句如下所示:
import tensorflow as tf
这使得Python可以访问所有TensorFlow的类,方法和符号。大多数文档假定您已经完成了这个工作。
计算图
你可能会想到TensorFlow核心程序由两个独立的部分组成:
- 构建计算图。
- 运行计算图。
一个计算图是一系列排列成节点图的TensorFlow操作。下面我们来构建一个简单的计算图。每个节点将零个或多个张量作为输入,并产生一个张量作为输出。一种类型的节点是一个常量,像所有的TensorFlow常量一样,它不需要输入,并输出一个内部存储的值。我们可以创建两个浮点数张量node1和node2如下:
node1 = tf.constant(3.0, dtype=tf.float32)
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2)
最后的打印语句产生
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
请注意,打印节点不会输出值3.0和4.0,这跟你想的可能不太一样。相反,它们是在评估时分别产生3.0和4.0的节点。为了实际评估节点,我们必须在一个Session(会话)内部运行计算图。会话封装了TensorFlow运行时的控制和状态。
以下代码创建一个Session对象,然后调用它的run方法运行足够的计算图来评估node1和node2。通过在会话中运行计算图如下:
sess = tf.Session()
print(sess.run([node1, node2]))
我们看到了3.0和4.0的预期值:
[3.0, 4.0]
我们可以通过组合具有操作的Tensor节点(操作也是节点)来构建更复杂的计算。例如,我们可以求和我们的两个常量节点,并产生一个新的图形如下:
from __future__ import print_function
node3 = tf.add(node1, node2)
print("node3:", node3)
print("sess.run(node3):", sess.run(node3))
最后两个打印语句产生
node3: Tensor("Add:0", shape=(), dtype=float32)
sess.run(node3): 7.0
TensorFlow提供了一个名为TensorBoard的实用程序,可以显示计算图的图片。下面是一个屏幕截图,展示了TensorBoard如何将图形可视化:
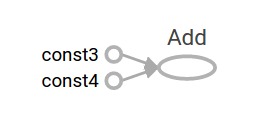
就目前来看,这张图并不特别有趣,因为它总是会产生一个不变的结果。图形可以参数化来接受外部输入,称为占位符。一个占位符是稍后提供特定值的声明。
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + provides a shortcut for tf.add(a, b)
前面的三行有点像一个函数或lambda,我们在其中定义两个输入参数(a和b),然后对它们进行操作。我们可以通过使用feed_dict参数来给run方法传入多个值,从而评估计算图:
print(sess.run(adder_node, {a: 3, b: 4.5}))
print(sess.run(adder_node, {a: [1, 3], b: [2, 4]}))
输出结果
7.5
[ 3. 7.]
在TensorBoard中,图形如下所示:
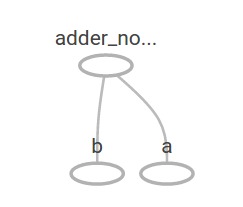
我们可以通过添加另一个操作来使计算图更加复杂。例如,
add_and_triple = adder_node * 3.
print(sess.run(add_and_triple, {a: 3, b: 4.5}))
产生输出
22.5
在TensorBoard中,上面的计算图如下所示:
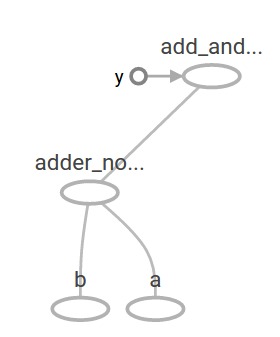
在机器学习中,我们通常需要一个可以进行任意输入的模型,比如上面的模型。为了使模型可训练,我们需要能够修改图形以获得具有相同输入的新输出。变量允许我们将可训练参数添加到图形中。变量可以通过一个类型和初始值构造:
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b
当你调用tf.constant时,常量被初始化,他们的值永远不会改变。相比之下,变量在调用时不会被初始化tf.Variable。要初始化TensorFlow程序中的所有变量,您必须显式调用一个特殊的操作,如下所示:
init = tf.global_variables_initializer()
sess.run(init)
意识到这一点很重要:init是初始化所有全局变量的TensorFlow sub-graph句柄。直到我们调用sess.run,这些变量是未初始化的。
因为x是一个占位符,我们可以同时对几个值x评估linear_model,如下:
print(sess.run(linear_model, {x: [1, 2, 3, 4]}))
产生输出
[ 0. 0.30000001 0.60000002 0.90000004]
我们已经创建了一个模型,但我们不知道它的好坏。为了在训练数据上评估模型,我们需要一个y占位符提供所需的值,并且我们需要编写一个损失函数。
损失函数用于衡量当前模型距离提供的数据有多远。我们将使用线性回归的标准损失模型,它将当前模型和提供的数据之间的差值的平方相加。linear_model - y创建一个向量,其中每个元素是相应示例的错误增量。我们调用tf.square来对这个错误求平方。然后,我们求和所有的平方误差,从而创建一个抽象所有样本误差的标量tf.reduce_sum:
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y)
loss = tf.reduce_sum(squared_deltas)
print(sess.run(loss, {x: [1, 2, 3, 4], y: [0, -1, -2, -3]}))
产生损失值
23.66
我们可以通过重新赋值来手动改进W和b到-1和1的完美值。一个变量被初始化为提供的值tf.Variable但可以使用类似的操作进行更改tf.assign。例如,W=-1和b=1是我们模型的最佳参数。我们可以改变W和b因此:
fixW = tf.assign(W, [-1.])
fixb = tf.assign(b, [1.])
sess.run([fixW, fixb])
print(sess.run(loss, {x: [1, 2, 3, 4], y: [0, -1, -2, -3]}))
最后的print显示现在的损失是零。
0.0
我们猜到了W和b的完美值,但是机器学习的重点是自动找到正确的模型参数。我们将在下一节展示如何完成这个目标。
tf.train API
机器学习的完整讨论超出了本教程的范围。TensorFlow提供了优化器用于缓慢地改变每个变量以使损失函数最小化。最简单的优化器是梯度下降。它根据相对于该变量的损失导数的大小来修改每个变量。一般来说,手动计算符号导数是非常繁琐的,而且容易出错。因此,TensorFlow可以自动生成导数,仅使用该函数对模型进行描述tf.gradients。为了简单起见,优化器通常会为您执行此操作。例如,
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
sess.run(init) # reset values to incorrect defaults.
for i in range(1000):
sess.run(train, {x: [1, 2, 3, 4], y: [0, -1, -2, -3]})
print(sess.run([W, b]))
产生最终的模型参数:
[array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]
现在我们已经完成了机器学习!虽然这个简单的线性回归模型不需要太多的TensorFlow核心代码,但是更复杂的模型和方法将数据提供给模型需要更多的代码。因此,TensorFlow为常见的模式,结构和功能提供更高层次的抽象。我们将在下一节学习如何使用这些抽象。
完整的程序
完成的可训练线性回归模型如下所示:
import tensorflow as tf
# Model parameters
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
# Model input and output
x = tf.placeholder(tf.float32)
linear_model = W*x + b
y = tf.placeholder(tf.float32)
# loss
loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares
# optimizer
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
# training data
x_train = [1, 2, 3, 4]
y_train = [0, -1, -2, -3]
# training loop
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init) # reset values to wrong
for i in range(1000):
sess.run(train, {x: x_train, y: y_train})
# evaluate training accuracy
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
运行时产生
W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11
请注意,损失是非常小的数字(非常接近零)。如果你运行这个程序,你的损失可能与上述损失不完全一样,因为模型是用伪随机值初始化的。
这个更复杂的程序仍然可以在TensorBoard中可视化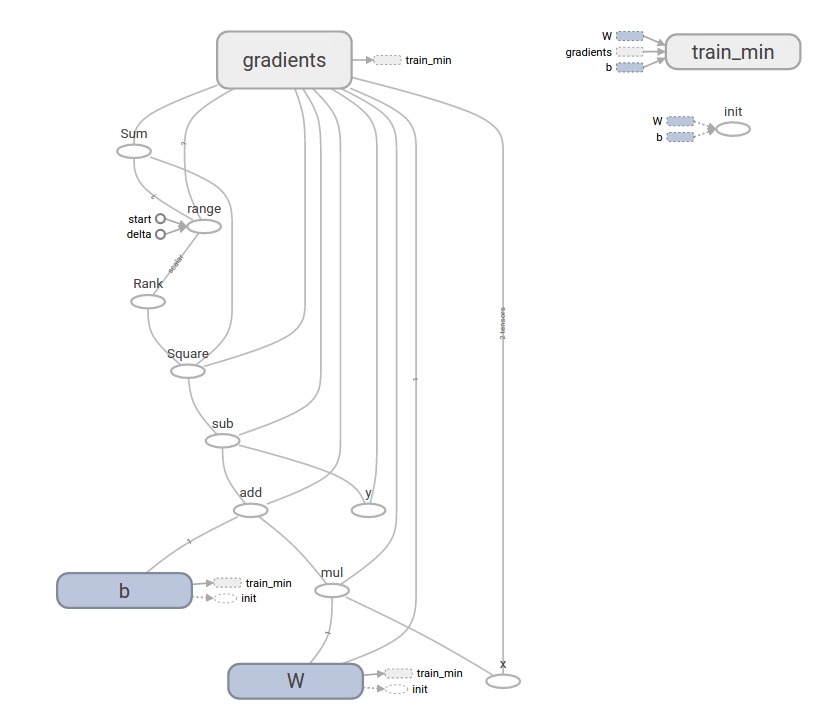
tf.estimator
tf.estimator是一个high-level TensorFlow库,简化了机器学习的机制,包括以下内容:
- 运行训练循环
- 运行评估循环
- 管理数据集
tf.estimator定义了许多常见的模型。
基本用法
注意使用tf.estimator,线性回归程序变得简单多了:
# NumPy is often used to load, manipulate and preprocess data.
import numpy as np
import tensorflow as tf
# Declare list of features. We only have one numeric feature. There are many
# other types of columns that are more complicated and useful.
feature_columns = [tf.feature_column.numeric_column("x", shape=[1])]
# An estimator is the front end to invoke training (fitting) and evaluation
# (inference). There are many predefined types like linear regression,
# linear classification, and many neural network classifiers and regressors.
# The following code provides an estimator that does linear regression.
estimator = tf.estimator.LinearRegressor(feature_columns=feature_columns)
# TensorFlow provides many helper methods to read and set up data sets.
# Here we use two data sets: one for training and one for evaluation
# We have to tell the function how many batches
# of data (num_epochs) we want and how big each batch should be.
x_train = np.array([1., 2., 3., 4.])
y_train = np.array([0., -1., -2., -3.])
x_eval = np.array([2., 5., 8., 1.])
y_eval = np.array([-1.01, -4.1, -7, 0.])
input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=4, num_epochs=None, shuffle=True)
train_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=4, num_epochs=1000, shuffle=False)
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_eval}, y_eval, batch_size=4, num_epochs=1000, shuffle=False)
# We can invoke 1000 training steps by invoking the method and passing the
# training data set.
estimator.train(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did.
train_metrics = estimator.evaluate(input_fn=train_input_fn)
eval_metrics = estimator.evaluate(input_fn=eval_input_fn)
print("train metrics: %r"% train_metrics)
print("eval metrics: %r"% eval_metrics)
运行时,会产生类似的东西
train metrics: {'average_loss': 1.4833182e-08, 'global_step': 1000, 'loss': 5.9332727e-08}
eval metrics: {'average_loss': 0.0025353201, 'global_step': 1000, 'loss': 0.01014128}
请注意我们的评估数据是如何有更高的损失,但仍然接近于零。这意味着我们正在正确地学习。
自定义模型
tf.estimator不会将您锁定在预定义的模型中。假设我们想创建一个没有内置到TensorFlow中的自定义模型。我们仍然可以保留tf.estimator的数据集,feeding,训练等的高层次抽象。下面我们将展示如何实现我们自己的等效模型————LinearRegressor使用我们对低级别TensorFlow API的知识。
定义一个适用的自定义模型tf.estimator,我们需要使用tf.estimator.Estimator。tf.estimator.LinearRegressor实际上是tf.estimator.Estimator的子类,而不是sub-classingEstimator,我们只是提供Estimator一个功能model_fn这告诉tf.estimator如何评估预测效果、训练步骤以及损失。代码如下:
import numpy as np
import tensorflow as tf
# Declare list of features, we only have one real-valued feature
def model_fn(features, labels, mode):
# Build a linear model and predict values
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# Loss sub-graph
loss = tf.reduce_sum(tf.square(y - labels))
# Training sub-graph
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# EstimatorSpec connects subgraphs we built to the
# appropriate functionality.
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=y,
loss=loss,
train_op=train)
estimator = tf.estimator.Estimator(model_fn=model_fn)
# define our data sets
x_train = np.array([1., 2., 3., 4.])
y_train = np.array([0., -1., -2., -3.])
x_eval = np.array([2., 5., 8., 1.])
y_eval = np.array([-1.01, -4.1, -7., 0.])
input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=4, num_epochs=None, shuffle=True)
train_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=4, num_epochs=1000, shuffle=False)
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_eval}, y_eval, batch_size=4, num_epochs=1000, shuffle=False)
# train
estimator.train(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did.
train_metrics = estimator.evaluate(input_fn=train_input_fn)
eval_metrics = estimator.evaluate(input_fn=eval_input_fn)
print("train metrics: %r"% train_metrics)
print("eval metrics: %r"% eval_metrics)
运行时产生
train metrics: {'loss': 1.227995e-11, 'global_step': 1000}
eval metrics: {'loss': 0.01010036, 'global_step': 1000}
注意model_fn()功能与我们的低级API手动模型训练循环非常相似。
下一步
现在您已经掌握了TensorFlow的基础知识。我们还有更多的教程可供您了解更多信息。如果你是机器学习的初学者,请参阅MNIST初学者版,否则请看深度MNIST专家版。