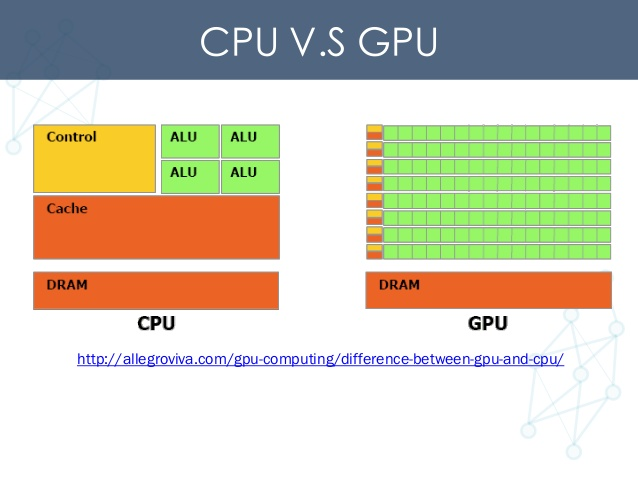
我在共享计算资源的环境中工作,也就是说,我们有几台服务器机器都配备了几个Nvidia Titan X GPU。
对于小到中等尺寸的模型,Titan X的12GB通常足以让2-3人在同一GPU上同时进行训练。如果模型足够小,以至于单个模型不能充分利用Titan X的所有计算单元,那么实际上可以导致某种加速(相比串行多个训练任务来说)。即使在GPU的并发访问确实减慢了单个训练时间的情况下,同时在GPU上拥有多个用户运行的灵活性仍然不错。
TensorFlow的问题在于,默认情况下,它会在GPU启动时为其分配全部可用内存。即使对于一个小型的2层神经网络,我也看到Titan X的12 GB用完了。
有没有办法让TensorFlow只分配4GB的GPU内存,如果知道这个数量对于给定的模型是足够的?

最佳解决办法
通过将tf.GPUOptions作为可选config参数的一部分传递来构造tf.Session时,可以设置要分配的GPU内存部分:
# Assume that you have 12GB of GPU memory and want to allocate ~4GB:
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
per_process_gpu_memory_fraction充当同一机器上每个GPU上的进程将使用的GPU内存数量的硬上限。目前,这个比例被统一应用到同一台机器上的所有GPU上;没有办法在per-GPU的基础上进行设置。
次佳解决办法
config = tf.ConfigProto()
config.gpu_options.allow_growth=True
sess = tf.Session(config=config)
https://github.com/tensorflow/tensorflow/issues/1578