我正使用TensorFlow来训练一个神经网络。我初始化GradientDescentOptimizer的方式如下:
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
mse = tf.reduce_mean(tf.square(out - out_))
train_step = tf.train.GradientDescentOptimizer(0.3).minimize(mse)
问题是我不知道如何为学习速率或衰减值设置更新规则。
如何在这里使用自适应学习率呢?
最佳解决办法
首先,tf.train.GradientDescentOptimizer旨在对所有步骤中的所有变量使用恒定的学习率。 TensorFlow还提供现成的自适应优化器,包括tf.train.AdagradOptimizer和tf.train.AdamOptimizer,这些可以作为随时可用的替代品。
但是,如果要通过其他普通渐变下降控制学习速率,则可以利用以下事实:tf.train.GradientDescentOptimizer构造函数的learning_rate参数可以是Tensor对象。这允许您在每个步骤中为学习速率计算不同的值,例如:
learning_rate = tf.placeholder(tf.float32, shape=[])
# ...
train_step = tf.train.GradientDescentOptimizer(
learning_rate=learning_rate).minimize(mse)
sess = tf.Session()
# Feed different values for learning rate to each training step.
sess.run(train_step, feed_dict={learning_rate: 0.1})
sess.run(train_step, feed_dict={learning_rate: 0.1})
sess.run(train_step, feed_dict={learning_rate: 0.01})
sess.run(train_step, feed_dict={learning_rate: 0.01})
或者,您可以创建一个标量tf.Variable来保存学习率,并在每次要更改学习率时进行分配。
次佳解决办法
Tensorflow提供了一种自动将指数衰减应用于学习速率张量的操作:tf.train.exponential_decay。有关正在使用的示例,请参阅this line in the MNIST convolutional model example。然后使用前文中的建议将此变量作为learning_rate参数提供给您的优化器。
要看的关键部分是:
# Optimizer: set up a variable that's incremented once per batch and
# controls the learning rate decay.
batch = tf.Variable(0)
learning_rate = tf.train.exponential_decay(
0.01, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
train_size, # Decay step.
0.95, # Decay rate.
staircase=True)
# Use simple momentum for the optimization.
optimizer = tf.train.MomentumOptimizer(learning_rate,
0.9).minimize(loss,
global_step=batch)
注意最小化global_step=batch参数。这会告诉优化器在每次训练时都会帮助您增加’batch’参数。
第三种解决办法
梯度下降算法使您可以在during the initialization中提供的恒定的学习速率。可以通过前文所示的方式传递各种学习速率。
但是,也可以使用more advanced optimizers,它具有更快的收敛速度并适应这种情况。
根据我的理解,这里是一个简短的解释:
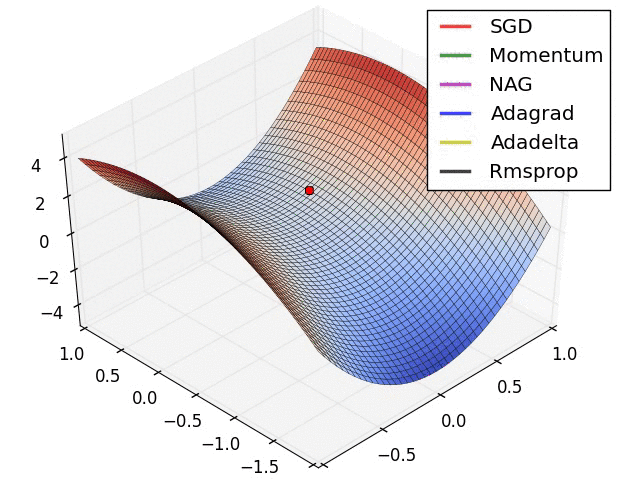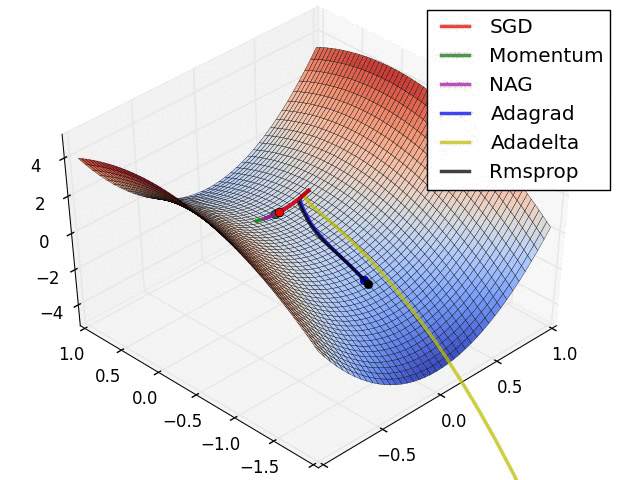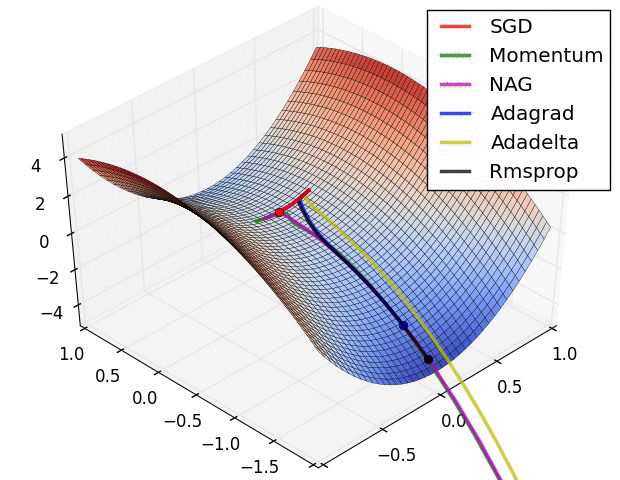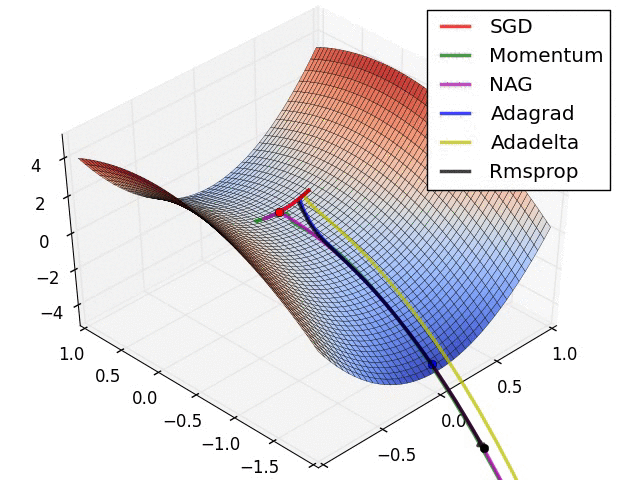
- 动量(momentum)helps SGD沿相关方向导航,并减弱无关的振荡。它只是将上一步骤的一部分方向添加到当前步骤。这可以在正确的方向上实现放大速度,并减少错误方向的振荡。该分数通常在(0,1)范围内。使用自适应动量也是有意义的。在学习开始时,一个大的动量只会阻碍你的进步,所以使用类似0.01的数值很有意义,一旦所有的高梯度消失,你可以使用更大的动量。动量也有一个问题:当我们非常接近目标时,我们在大多数情况下的动量非常高,而且它不知道它应该放慢速度。这可能导致它错过或在最低点附近振荡
- 内斯特洛夫加速梯度(nesterov accelerated gradient, NAG)通过开始减速提前克服了这个问题。在动量中,我们首先计算梯度,然后通过先前的任何动量放大该方向的跳跃。 NAG做的是同样的事情,但是按照另一种顺序:首先我们根据存储的信息做出一个大的跳跃,然后我们计算梯度并进行一个小的修正。这个看似不相关的变化给了显著的实际加速。
- AdaGrad或自适应梯度允许学习速率根据参数进行调整。它对不频繁的参数执行更大的更新,对频繁的参数执行更小的更新。正因为如此,它非常适合稀疏数据(NLP或图像识别)。另一个优点是它基本上不需要调整学习速度。每个参数都有其自己的学习速率,并且由于算法的特性,学习速率是单调递减的。这导致了最大的问题:在某个时间点,学习率很低,系统停止学习
- AdaDelta解决了AdaGrad中单调降低学习率的问题。在AdaGrad中,学习率大致被计算为除以平方根之和。在每个阶段,您都会在总和中再加一个平方根,这会导致分母不断下降。在AdaDelta中,不是将所有过去的平方根相加,而是使用允许总和减少的滑动窗口。 RMSprop与AdaDelta非常相似
- Adam或自适应动量是一种类似于AdaDelta的算法。但除了存储每个参数的学习率外,它还分别存储每个参数的动量变化A few visualizations:

参考资料