本文簡要介紹 python 語言中 scipy.stats.dunnett 的用法。
用法:
scipy.stats.dunnett(*samples, control, alternative='two-sided', random_state=None)#Dunnett 檢驗:將平均值與對照組進行多重比較。
這是 Dunnett 原始 single-step 測試的實現,如 [1] 中所述。
- sample1, sample2, …: 一維數組
每個實驗組的樣本測量值。
- control: 一維數組
對照組的樣本測量值。
- alternative: {‘雙麵’,‘less’, ‘greater’},可選
定義備擇假設。
原假設是樣本和對照的分布均值相等。可以使用以下替代假設(默認為“雙麵”):
“雙麵”:樣本和對照的分布均值不相等。
‘less’:樣本基礎分布的均值小於對照基礎分布的均值。
‘greater’:樣本基礎分布的均值大於控件基礎分布的均值。
- random_state: {無,整數,
numpy.random.Generator},可選 如果random_state是 int 或 None,一個新的
numpy.random.Generator是使用創建的np.random.default_rng(random_state).如果random_state已經是一個Generator實例,然後使用提供的實例。隨機數生成器用於控製 multivariate-t 分布的隨機 Quasi-Monte 卡羅積分。
- res:
DunnettResult 包含屬性的對象:
- 統計 浮點數數組
每次比較的測試的計算統計量。索引
i處的元素是組i與對照組之間比較的統計數據。- p值 浮點數數組
每次比較的檢驗的計算 p 值。索引
i處的元素是組i與對照之間比較的 p 值。
以及以下方法:
- confidence_interval(confidence_level=0.95):
計算對照組平均值的差異+-津貼。
- res:
參數 ::
返回 ::
注意:
與 independent-sample t-test 一樣,Dunnett 檢驗 [1] 用於推斷樣本的分布均值。然而,當在固定顯著性水平下執行多個t-tests時,“family-wise錯誤率”(在至少一次檢驗中錯誤拒絕零假設的概率)將超過顯著性水平。 Dunnett 的測試旨在執行多重比較,同時控製 family-wise 錯誤率。
鄧尼特檢驗將多個實驗組的平均值與單個對照組的平均值進行比較。 Tukey 的誠實顯著差異測試是另一個控製 family-wise 錯誤率的 multiple-comparison 測試,但是scipy.stats.tukey_hsd施行全部組間的兩兩比較。當不需要實驗組之間的成對比較時,鄧尼特檢驗因其較高的功效而更可取。
該測試的使用依賴於幾個假設。
觀察在組內和組間是獨立的。
每組內的觀察值呈正態分布。
從中抽取樣本的分布具有相同的有限方差。
參考:
[1] (1,2,3)查爾斯·W·鄧尼特。 “將幾種治療方法與對照進行比較的多重比較程序。”美國統計協會雜誌,50:272, 1096-1121,DOI:10.1080/01621459.1955.10501294,1955 年。
例子:
在[1]中,研究了藥物對三組動物血細胞計數測量的影響。
下表總結了實驗結果,其中兩組接受不同的藥物,一組作為對照。記錄血細胞計數(每立方毫米數百萬個細胞):
>>> import numpy as np >>> control = np.array([7.40, 8.50, 7.20, 8.24, 9.84, 8.32]) >>> drug_a = np.array([9.76, 8.80, 7.68, 9.36]) >>> drug_b = np.array([12.80, 9.68, 12.16, 9.20, 10.55])我們想看看任何組之間的方法是否有顯著差異。首先,目視檢查盒須圖。
>>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(1, 1) >>> ax.boxplot([control, drug_a, drug_b]) >>> ax.set_xticklabels(["Control", "Drug A", "Drug B"]) >>> ax.set_ylabel("mean") >>> plt.show()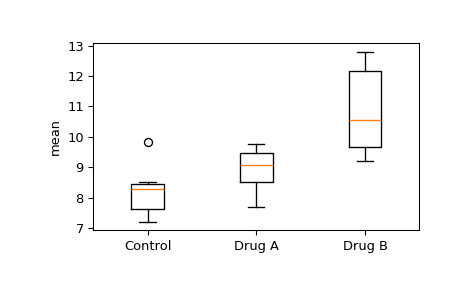
注意藥物 A 組和對照組的重疊四分位數範圍以及藥物 B 組和對照組之間的明顯分離。
接下來,我們將使用 Dunnett 檢驗來評估組均值之間的差異是否顯著,同時控製 family-wise 錯誤率:做出任何錯誤發現的概率。令零假設為實驗組與對照組具有相同的均值,而替代假設為實驗組與對照組不具有相同的均值。我們認為 5% family-wise 錯誤率是可以接受的,因此我們選擇 0.05 作為顯著性閾值。
>>> from scipy.stats import dunnett >>> res = dunnett(drug_a, drug_b, control=control) >>> res.pvalue array([0.62004941, 0.0059035 ]) # may varyA 組與對照組之間的比較對應的 p 值超過 0.05,因此我們不拒絕該比較的原假設。然而,與 B 組和對照組之間的比較相對應的 p 值小於 0.05,因此我們認為實驗結果是反對零假設的證據,有利於替代方案:B 組的平均值與對照組不同。
相關用法
- Python SciPy stats.directional_stats用法及代碼示例
- Python SciPy stats.dirichlet_multinomial用法及代碼示例
- Python SciPy stats.dweibull用法及代碼示例
- Python SciPy stats.differential_entropy用法及代碼示例
- Python SciPy stats.dgamma用法及代碼示例
- Python SciPy stats.describe用法及代碼示例
- Python SciPy stats.dlaplace用法及代碼示例
- Python SciPy stats.dirichlet用法及代碼示例
- Python SciPy stats.anderson用法及代碼示例
- Python SciPy stats.iqr用法及代碼示例
- Python SciPy stats.genpareto用法及代碼示例
- Python SciPy stats.skewnorm用法及代碼示例
- Python SciPy stats.cosine用法及代碼示例
- Python SciPy stats.norminvgauss用法及代碼示例
- Python SciPy stats.invwishart用法及代碼示例
- Python SciPy stats.bartlett用法及代碼示例
- Python SciPy stats.levy_stable用法及代碼示例
- Python SciPy stats.page_trend_test用法及代碼示例
- Python SciPy stats.itemfreq用法及代碼示例
- Python SciPy stats.exponpow用法及代碼示例
- Python SciPy stats.gumbel_l用法及代碼示例
- Python SciPy stats.chisquare用法及代碼示例
- Python SciPy stats.semicircular用法及代碼示例
- Python SciPy stats.gzscore用法及代碼示例
- Python SciPy stats.gompertz用法及代碼示例
注:本文由純淨天空篩選整理自scipy.org大神的英文原創作品 scipy.stats.dunnett。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。