scipy.stats.kurtosis(array, axis=0, fisher=True, bias=True)函数计算数据集的峰度(Fisher或Pearson)。它是第四个中心矩除以方差的平方。它是“tailedness”的量度,即real-valued随机变量的概率分布形状的描述符。简而言之,这可以说是衡量粗尾与正态分布相比的一种方法。
其公式-
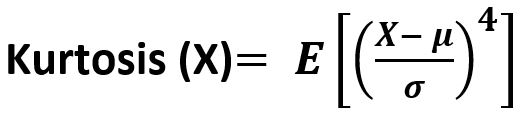
参数:
array : 具有元素的输入数组或对象。
axis : 将测量峰度值的轴。默认情况下,轴= 0。
fisher : 布尔如果为True,则使用Fisher定义(正常为0.0);否则,如果设置为False,则使用Pearson的定义(标准3.0)。
bias : 布尔如果设置为False,则针对统计偏差对计算进行校正。
返回值:数据集的正态分布的峰度值。
代码1:
# Graph using numpy.linspace()
# finding kurtosis
from scipy.stats import kurtosis
import numpy as np
import pylab as p
x1 = np.linspace( -5, 5, 1000 )
y1 = 1./(np.sqrt(2.*np.pi)) * np.exp( -.5*(x1)**2 )
p.plot(x1, y1, '*')
print( '\nKurtosis for normal distribution :', kurtosis(y1))
print( '\nKurtosis for normal distribution :',
kurtosis(y1, fisher = False))
print( '\nKurtosis for normal distribution :',
kurtosis(y1, fisher = True))输出:
Kurtosis for normal distribution : -0.3073930877422071 Kurtosis for normal distribution : 2.692606912257793 Kurtosis for normal distribution : -0.3073930877422071
相关用法
- Python Scipy stats.sem()用法及代码示例
- Python Scipy stats.mean()用法及代码示例
- Python Scipy stats.relfreq()用法及代码示例
- Python Scipy stats.tvar()用法及代码示例
- Python Scipy stats.nanstd()用法及代码示例
- Python Scipy stats.gmean()用法及代码示例
- Python Scipy stats.trimboth()用法及代码示例
- Python Scipy stats.bayes_mvs()用法及代码示例
- Python Scipy stats.scoreatpercentile()用法及代码示例
- Python Scipy stats.nanmean()用法及代码示例
- Python Scipy stats.moment()用法及代码示例
- Python Scipy stats.trim1()用法及代码示例
- Python Scipy stats.kurtosistest()用法及代码示例
注:本文由纯净天空筛选整理自vishal3096大神的英文原创作品 scipy stats.kurtosis() function | Python。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。