Tidy 总结了有关模型组件的信息。模型组件可能是回归中的单个项、单个假设、聚类或类。 tidy 所认为的模型组件的确切含义因模型而异,但通常是不言而喻的。如果模型具有多种不同类型的组件,您将需要指定要返回哪些组件。
参数
- x
-
从
glmnet::glmnet()返回的glmnet对象。 - return_zeros
-
逻辑指示结果中是否应包含值为 0 0 的系数。默认为
FALSE。 - ...
-
附加参数。不曾用过。仅需要匹配通用签名。注意:拼写错误的参数将被吸收到
...中,并被忽略。如果拼写错误的参数有默认值,则将使用默认值。例如,如果您传递conf.lvel = 0.9,所有计算将使用conf.level = 0.95进行。这里有两个异常:
细节
请注意,虽然这种 GLM 表示比默认结构更容易绘制和组合,但它也更memory-intensive。请勿用于大型稀疏矩阵。
尽管模型产生了预测,但尚未提供 augment 方法,因为输入数据不整齐(它是一个可能非常宽的矩阵),因此将预测与它相结合是不合逻辑的。此外,预测只有在选择特定的 lambda 时才有意义。
也可以看看
其他 glmnet 整理器:glance.cv.glmnet()、glance.glmnet()、tidy.cv.glmnet()
值
带有列的 tibble::tibble():
- dev.ratio
-
每个 lambda 值处解释的零偏差分数。
- estimate
-
回归项的估计值。
- lambda
-
惩罚参数 lambda 的值。
- step
-
使用了 lambda 选择的哪一步。
- term
-
回归项的名称。
例子
# load libraries for models and data
library(glmnet)
set.seed(2014)
x <- matrix(rnorm(100 * 20), 100, 20)
y <- rnorm(100)
fit1 <- glmnet(x, y)
# summarize model fit with tidiers + visualization
tidy(fit1)
#> # A tibble: 1,086 × 5
#> term step estimate lambda dev.ratio
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1 -0.207 0.152 0
#> 2 (Intercept) 2 -0.208 0.139 0.00464
#> 3 (Intercept) 3 -0.209 0.127 0.0111
#> 4 (Intercept) 4 -0.210 0.115 0.0165
#> 5 (Intercept) 5 -0.210 0.105 0.0240
#> 6 (Intercept) 6 -0.210 0.0957 0.0321
#> 7 (Intercept) 7 -0.210 0.0872 0.0412
#> 8 (Intercept) 8 -0.210 0.0795 0.0497
#> 9 (Intercept) 9 -0.209 0.0724 0.0593
#> 10 (Intercept) 10 -0.208 0.0660 0.0682
#> # ℹ 1,076 more rows
glance(fit1)
#> # A tibble: 1 × 3
#> nulldev npasses nobs
#> <dbl> <int> <int>
#> 1 104. 255 100
library(dplyr)
library(ggplot2)
tidied <- tidy(fit1) %>% filter(term != "(Intercept)")
ggplot(tidied, aes(step, estimate, group = term)) +
geom_line()
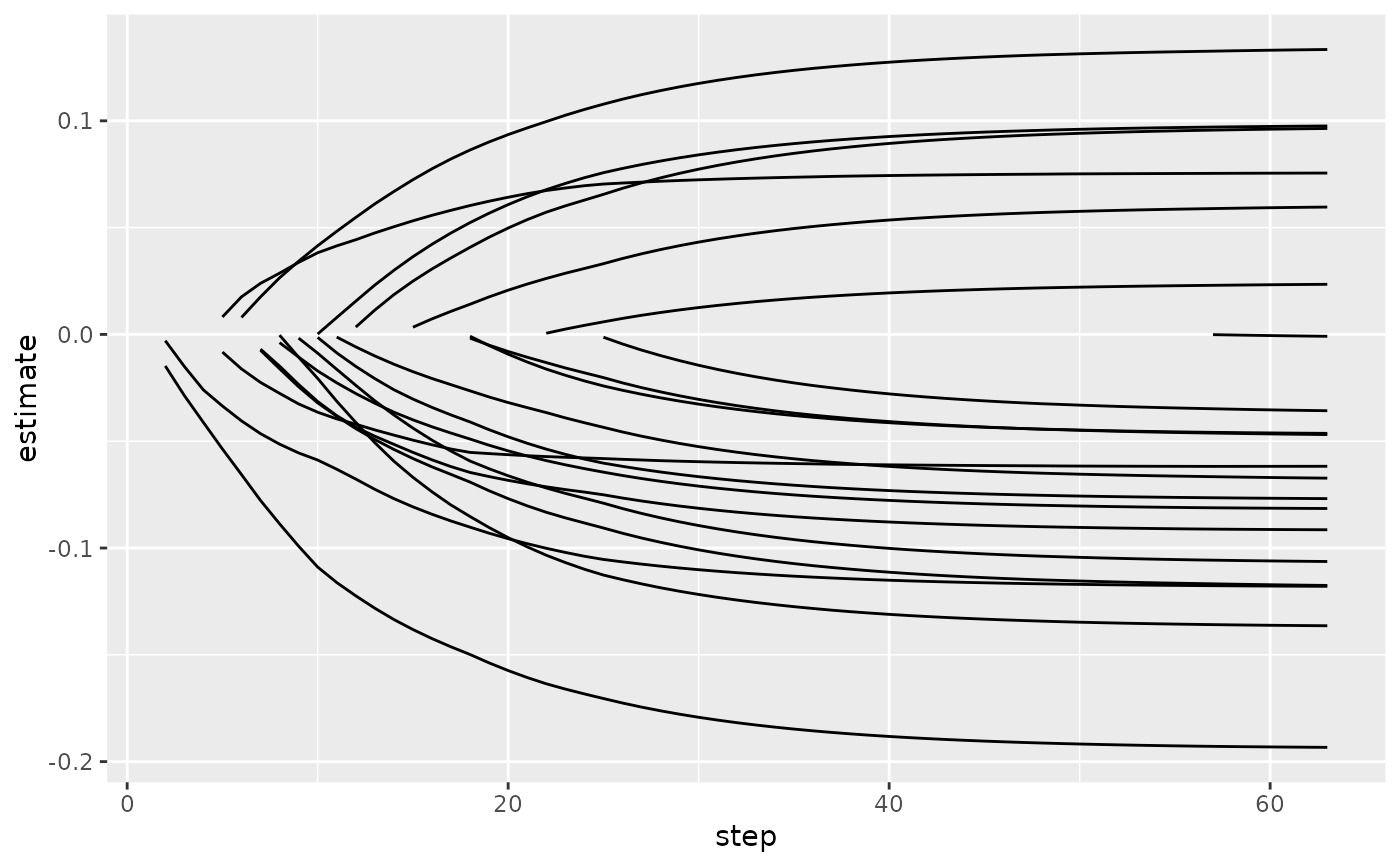 ggplot(tidied, aes(lambda, estimate, group = term)) +
geom_line() +
scale_x_log10()
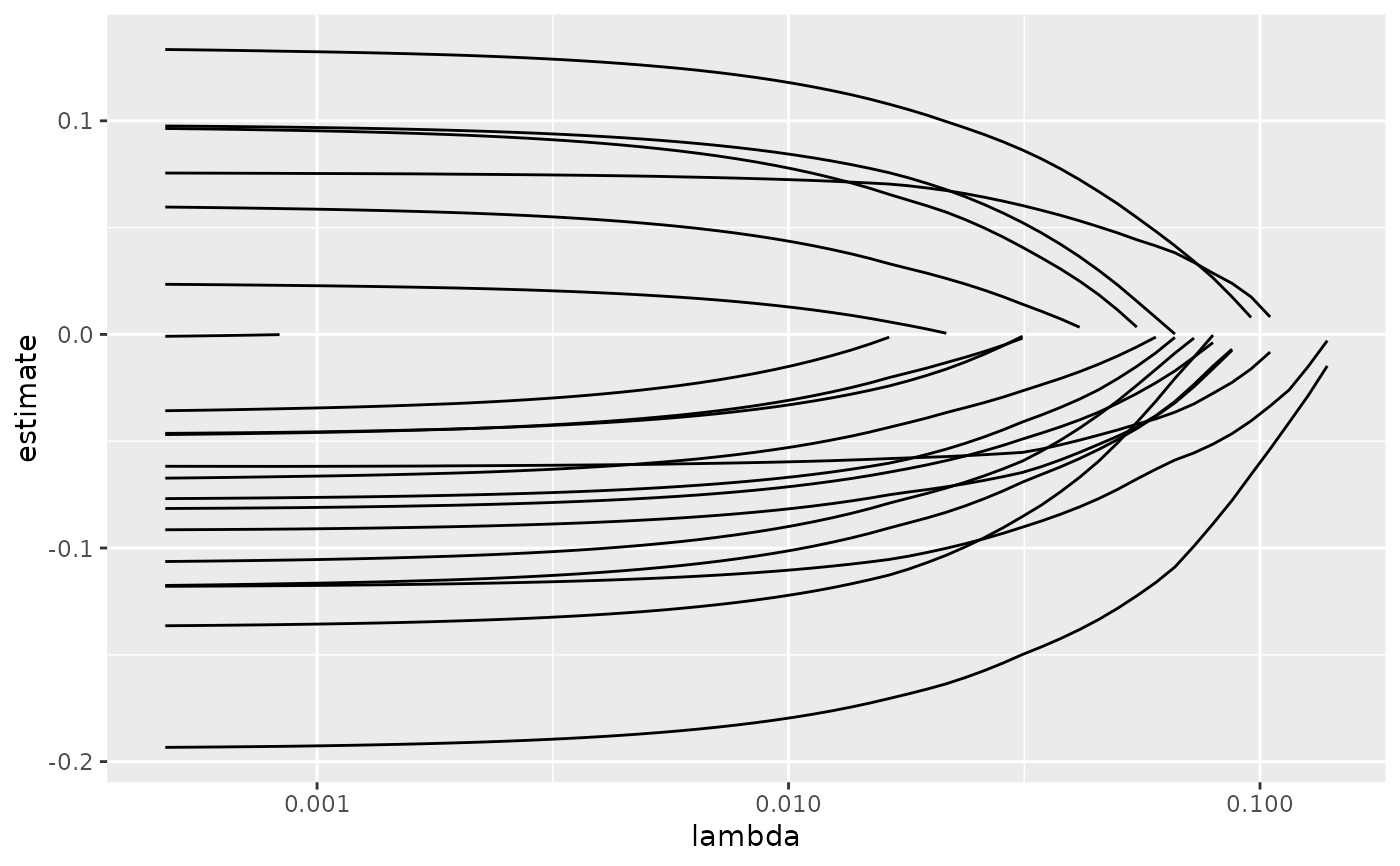
ggplot(tidied, aes(lambda, estimate, group = term)) +
geom_line() +
scale_x_log10()
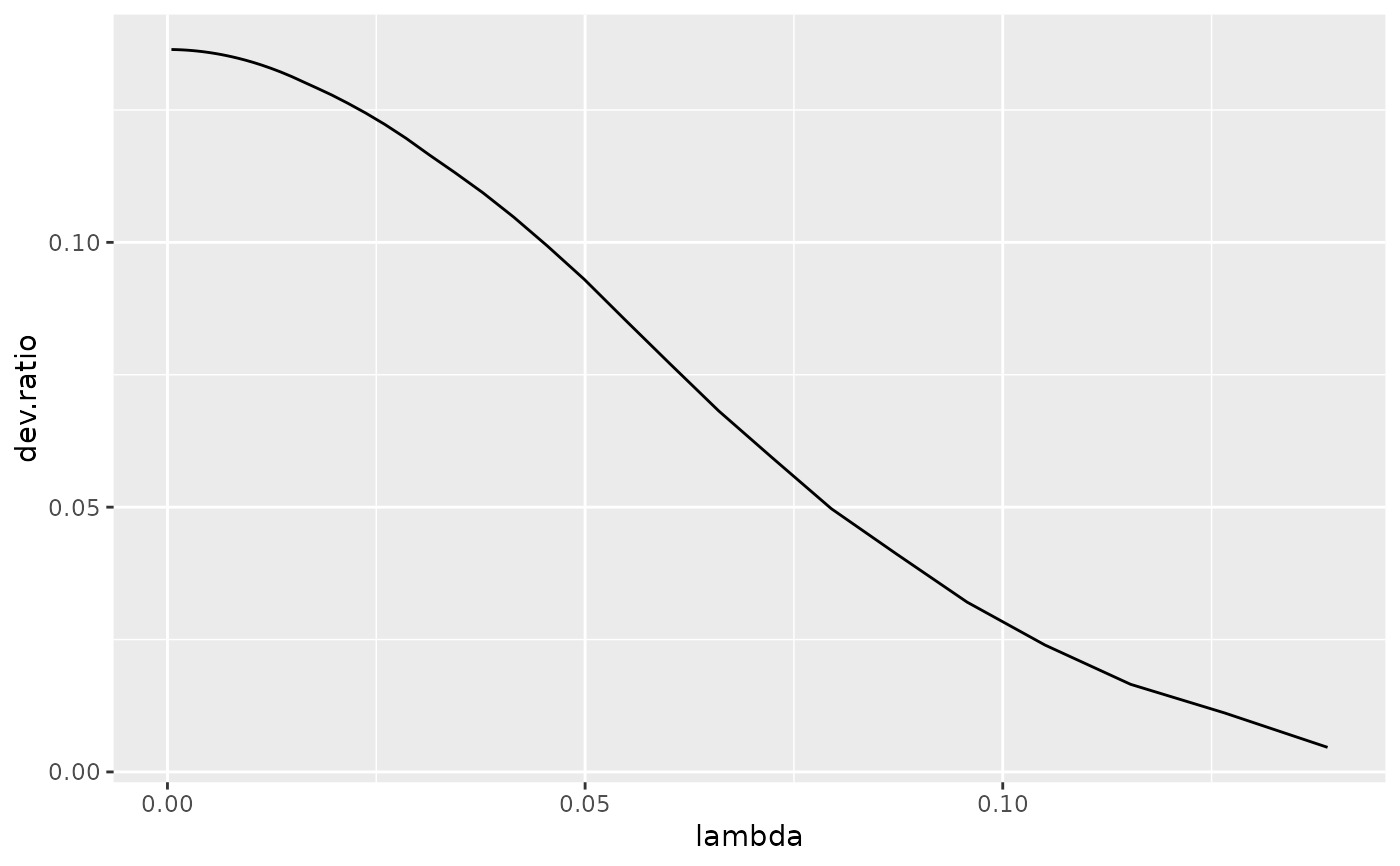
 ggplot(tidied, aes(lambda, dev.ratio)) +
geom_line()
ggplot(tidied, aes(lambda, dev.ratio)) +
geom_line()
 # works for other types of regressions as well, such as logistic
g2 <- sample(1:2, 100, replace = TRUE)
fit2 <- glmnet(x, g2, family = "binomial")
tidy(fit2)
#> # A tibble: 947 × 5
#> term step estimate lambda dev.ratio
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1 0.282 0.0906 -1.62e-15
#> 2 (Intercept) 2 0.281 0.0826 6.28e- 3
#> 3 (Intercept) 3 0.279 0.0753 1.55e- 2
#> 4 (Intercept) 4 0.277 0.0686 2.48e- 2
#> 5 (Intercept) 5 0.284 0.0625 4.17e- 2
#> 6 (Intercept) 6 0.293 0.0569 5.79e- 2
#> 7 (Intercept) 7 0.303 0.0519 7.39e- 2
#> 8 (Intercept) 8 0.314 0.0473 8.94e- 2
#> 9 (Intercept) 9 0.325 0.0431 1.03e- 1
#> 10 (Intercept) 10 0.336 0.0392 1.14e- 1
#> # ℹ 937 more rows
# works for other types of regressions as well, such as logistic
g2 <- sample(1:2, 100, replace = TRUE)
fit2 <- glmnet(x, g2, family = "binomial")
tidy(fit2)
#> # A tibble: 947 × 5
#> term step estimate lambda dev.ratio
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 1 0.282 0.0906 -1.62e-15
#> 2 (Intercept) 2 0.281 0.0826 6.28e- 3
#> 3 (Intercept) 3 0.279 0.0753 1.55e- 2
#> 4 (Intercept) 4 0.277 0.0686 2.48e- 2
#> 5 (Intercept) 5 0.284 0.0625 4.17e- 2
#> 6 (Intercept) 6 0.293 0.0569 5.79e- 2
#> 7 (Intercept) 7 0.303 0.0519 7.39e- 2
#> 8 (Intercept) 8 0.314 0.0473 8.94e- 2
#> 9 (Intercept) 9 0.325 0.0431 1.03e- 1
#> 10 (Intercept) 10 0.336 0.0392 1.14e- 1
#> # ℹ 937 more rows
相关用法
- R broom tidy.glmRob 整理 a(n) glmRob 对象
- R broom tidy.glht 整理 a(n) glht 对象
- R broom tidy.garch 整理 a(n) garch 对象
- R broom tidy.geeglm 整理 a(n) geeglm 对象
- R broom tidy.gam 整理 a(n) gam 对象
- R broom tidy.gmm 整理 a(n) gmm 对象
- R broom tidy.robustbase.glmrob 整理 a(n) glmrob 对象
- R broom tidy.acf 整理 a(n) acf 对象
- R broom tidy.robustbase.lmrob 整理 a(n) lmrob 对象
- R broom tidy.biglm 整理 a(n) biglm 对象
- R broom tidy.rq 整理 a(n) rq 对象
- R broom tidy.kmeans 整理 a(n) kmeans 对象
- R broom tidy.betamfx 整理 a(n) betamfx 对象
- R broom tidy.anova 整理 a(n) anova 对象
- R broom tidy.btergm 整理 a(n) btergm 对象
- R broom tidy.cv.glmnet 整理 a(n) cv.glmnet 对象
- R broom tidy.roc 整理 a(n) roc 对象
- R broom tidy.poLCA 整理 a(n) poLCA 对象
- R broom tidy.emmGrid 整理 a(n) emmGrid 对象
- R broom tidy.Kendall 整理 a(n) Kendall 对象
- R broom tidy.survreg 整理 a(n) survreg 对象
- R broom tidy.ergm 整理 a(n) ergm 对象
- R broom tidy.pairwise.htest 整理 a(n)pairwise.htest 对象
- R broom tidy.coeftest 整理 a(n) coeftest 对象
- R broom tidy.polr 整理 a(n) polr 对象
注:本文由纯净天空筛选整理自等大神的英文原创作品 Tidy a(n) glmnet object。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。