Broom 整理了許多列表,這些列表實際上是沒有類屬性的 S3 對象。例如, stats::optim() 、 svd() 和 interp::interp() 產生一致的輸出,但由於它們沒有類屬性,因此無法由 S3 調度處理。
這些函數查看列表的元素並確定是否有適當的整理方法可應用於該列表。這些整理器作為 tidy_<function> 或 glance_<function> 形式的函數實現,並且不會導出(但它們已記錄在案!)。
如果找不到合適的整理方法,它們會拋出錯誤。
參數
- x
-
base::svd()返回的組件u、d、v的列表。 - matrix
-
指定應整理 PCA 的哪個組件的字符。
-
"u"、"samples"、"scores"或"x":返回有關從原始空間到主成分空間的映射的信息。 -
"v"、"rotation"、"loadings"或"variables":將有關從主成分空間映射回原始空間的信息返回。 -
"d"、"eigenvalues"或"pcs":返回有關特征值的信息。
-
- ...
-
附加參數。不曾用過。僅需要匹配通用簽名。注意:拚寫錯誤的參數將被吸收到
...中,並被忽略。如果拚寫錯誤的參數有默認值,則將使用默認值。例如,如果您傳遞conf.lvel = 0.9,所有計算將使用conf.level = 0.95進行。這裏有兩個異常:
值
tibble::tibble,其列取決於正在整理的 PCA 的組件。
如果 matrix 是 "u" 、 "samples" 、 "scores" 或 "x" ,整理輸出中的每一行對應於 PCA 空間中的原始數據。這些列是:
row-
原始觀察的 ID(即原始數據中的行名稱)。
PC-
表示主成分的整數。
value-
該特定主成分的觀察分數。即 PCA 空間中觀測的位置。
如果 matrix 是 "v" 、 "rotation" 、 "loadings" 或 "variables" ,則整理輸出中的每一行對應於原始空間中主成分的信息。這些列是:
row-
執行 PCA 的數據集的變量標簽(列名)。
PC-
指示主成分的整數向量。
value-
指定主成分上的特征向量(軸得分)值。
如果 matrix 是 "d" 、 "eigenvalues" 或 "pcs" ,則列為:
PC-
指示主成分的整數向量。
std.dev-
此 PC 解釋的標準偏差。
percent-
該分量解釋的變異分數(0 到 1 之間的數值)。
cumulative-
由主要成分解釋的累積變異分數,直至該成分(0 到 1 之間的數值)。
細節
有關如何解釋各種整理矩陣的信息,請參閱 https://stats.stackexchange.com/questions/134282/relationship-between-svd-and-pca-how-to-use-svd-to-perform-pca。請注意,SVD 僅相當於中心數據上的 PCA。
也可以看看
其他 svd 整理器:augment.prcomp()、tidy.prcomp()、tidy_irlba()
其他列表整理器: glance_optim() 、 list_tidiers 、 tidy_irlba() 、 tidy_optim() 、 tidy_xyz()
例子
library(modeldata)
data(hpc_data)
mat <- scale(as.matrix(hpc_data[, 2:5]))
s <- svd(mat)
tidy_u <- tidy(s, matrix = "u")
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
tidy_u
#> # A tibble: 17,324 × 3
#> row PC value
#> <int> <dbl> <dbl>
#> 1 1 1 0.00403
#> 2 2 1 -0.00436
#> 3 3 1 -0.00196
#> 4 4 1 -0.00444
#> 5 5 1 -0.00437
#> 6 6 1 -0.00437
#> 7 7 1 -0.00431
#> 8 8 1 -0.00436
#> 9 9 1 -0.00434
#> 10 10 1 -0.00440
#> # ℹ 17,314 more rows
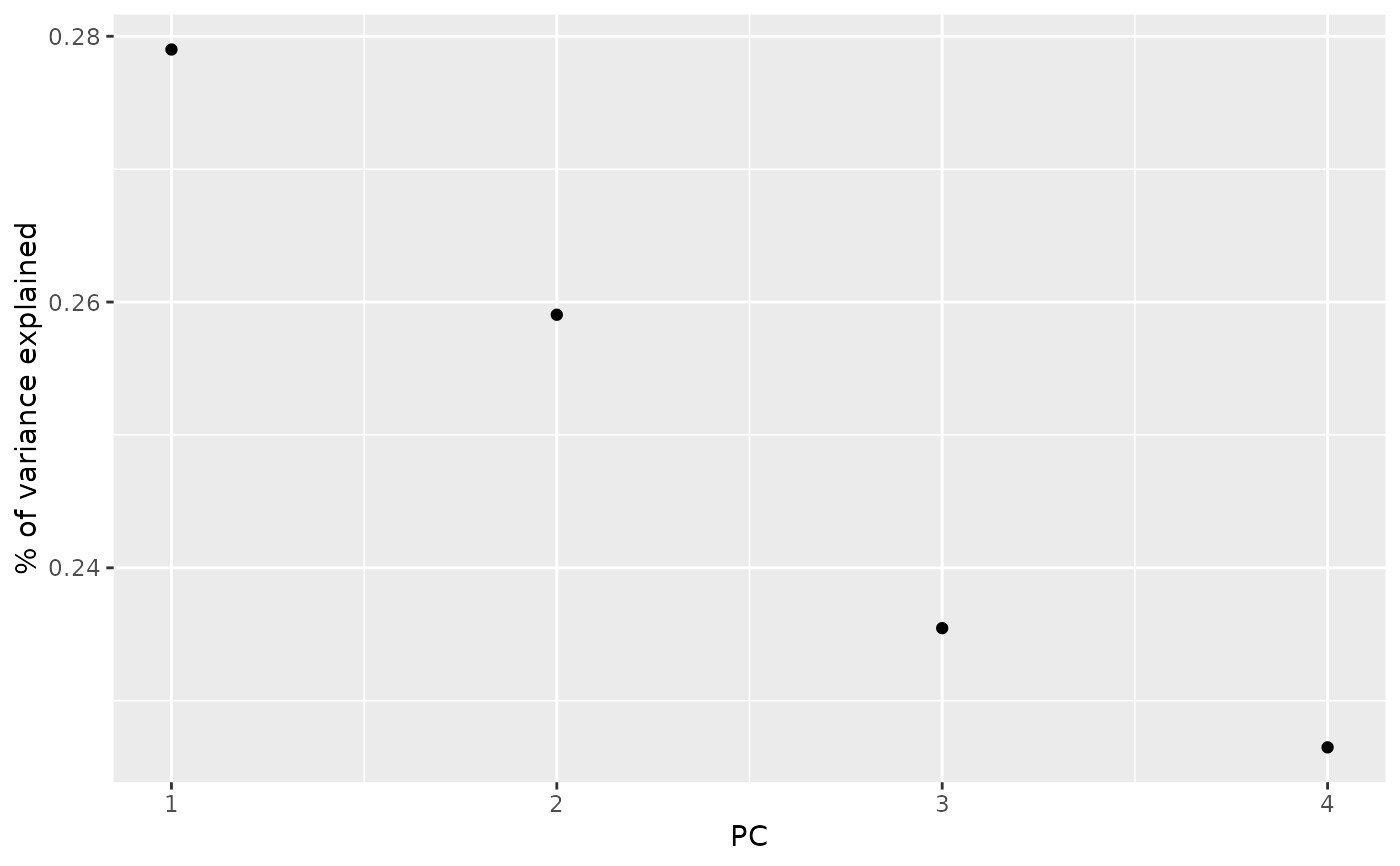
tidy_d <- tidy(s, matrix = "d")
tidy_d
#> # A tibble: 4 × 4
#> PC std.dev percent cumulative
#> <int> <dbl> <dbl> <dbl>
#> 1 1 69.5 0.279 0.279
#> 2 2 67.0 0.259 0.538
#> 3 3 63.9 0.235 0.774
#> 4 4 62.6 0.226 1
tidy_v <- tidy(s, matrix = "v")
#> New names:
#> • `` -> `...1`
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
tidy_v
#> # A tibble: 16 × 3
#> column PC value
#> <int> <dbl> <dbl>
#> 1 1 1 0.657
#> 2 2 1 0.409
#> 3 3 1 -0.577
#> 4 4 1 0.262
#> 5 1 2 -0.0142
#> 6 2 2 -0.650
#> 7 3 2 -0.137
#> 8 4 2 0.747
#> 9 1 3 -0.302
#> 10 2 3 -0.332
#> 11 3 3 -0.779
#> 12 4 3 -0.438
#> 13 1 4 -0.690
#> 14 2 4 0.548
#> 15 3 4 -0.205
#> 16 4 4 0.426
library(ggplot2)
library(dplyr)
ggplot(tidy_d, aes(PC, percent)) +
geom_point() +
ylab("% of variance explained")
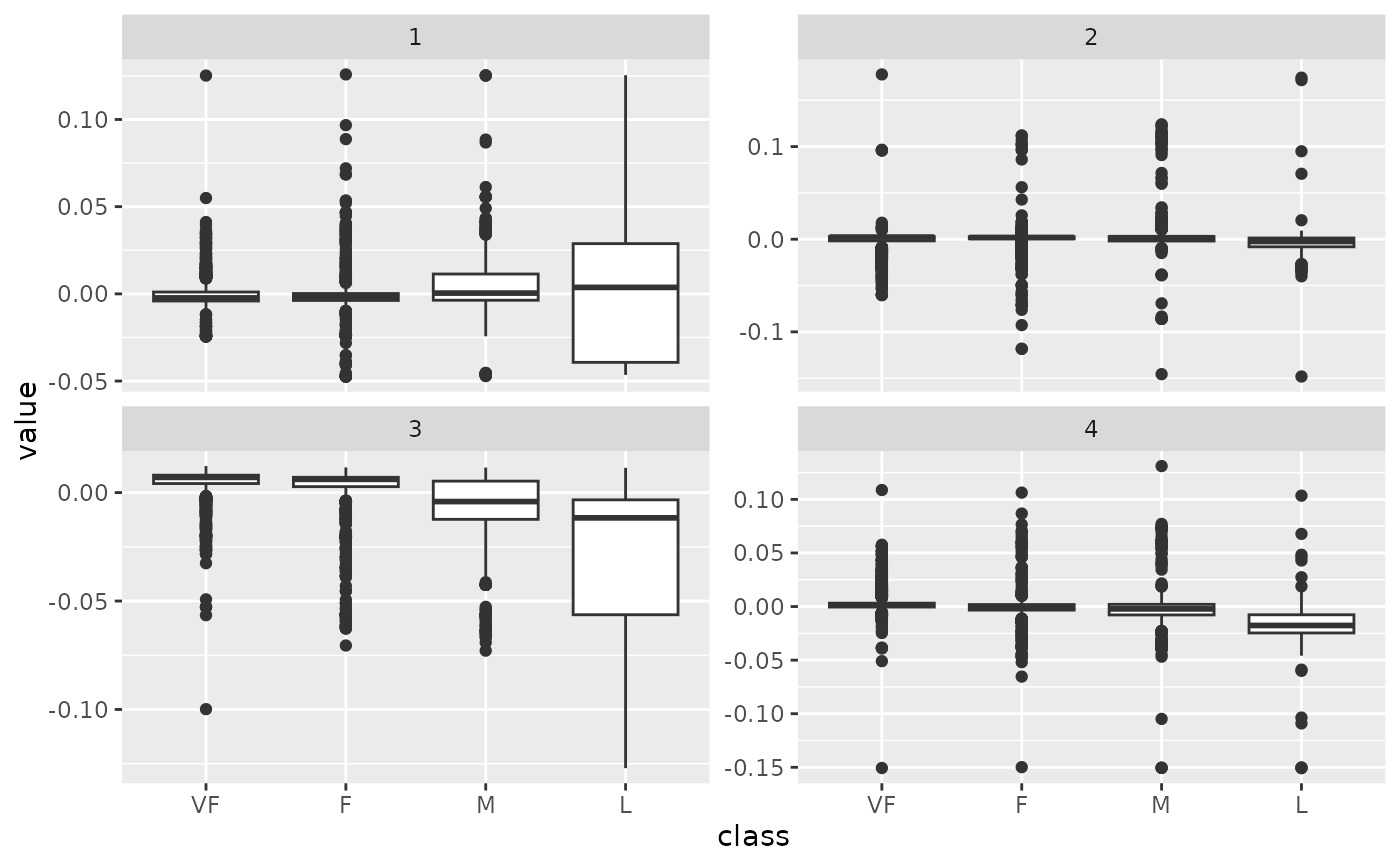
 tidy_u %>%
mutate(class = hpc_data$class[row]) %>%
ggplot(aes(class, value)) +
geom_boxplot() +
facet_wrap(~PC, scale = "free_y")
tidy_u %>%
mutate(class = hpc_data$class[row]) %>%
ggplot(aes(class, value)) +
geom_boxplot() +
facet_wrap(~PC, scale = "free_y")
相關用法
- R broom tidy_irlba 整理偽裝成列表的 a(n) irlba 對象
- R broom tidy_gam_hastie 整理 a(n) Gam 對象
- R broom tidy_xyz 整理偽裝成列表的 a(n) xyz 對象
- R broom tidy_optim 整理偽裝成列表的 a(n) 優化對象
- R broom tidy.robustbase.glmrob 整理 a(n) glmrob 對象
- R broom tidy.acf 整理 a(n) acf 對象
- R broom tidy.robustbase.lmrob 整理 a(n) lmrob 對象
- R broom tidy.biglm 整理 a(n) biglm 對象
- R broom tidy.garch 整理 a(n) garch 對象
- R broom tidy.rq 整理 a(n) rq 對象
- R broom tidy.kmeans 整理 a(n) kmeans 對象
- R broom tidy.betamfx 整理 a(n) betamfx 對象
- R broom tidy.anova 整理 a(n) anova 對象
- R broom tidy.btergm 整理 a(n) btergm 對象
- R broom tidy.cv.glmnet 整理 a(n) cv.glmnet 對象
- R broom tidy.roc 整理 a(n) roc 對象
- R broom tidy.poLCA 整理 a(n) poLCA 對象
- R broom tidy.emmGrid 整理 a(n) emmGrid 對象
- R broom tidy.Kendall 整理 a(n) Kendall 對象
- R broom tidy.survreg 整理 a(n) survreg 對象
- R broom tidy.ergm 整理 a(n) ergm 對象
- R broom tidy.pairwise.htest 整理 a(n)pairwise.htest 對象
- R broom tidy.coeftest 整理 a(n) coeftest 對象
- R broom tidy.polr 整理 a(n) polr 對象
- R broom tidy.map 整理 a(n) Map對象
注:本文由純淨天空篩選整理自等大神的英文原創作品 Tidy a(n) svd object masquerading as list。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。