本文簡要介紹 python 語言中 numpy.polyfit 的用法。
用法:
numpy.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)最小二乘多項式擬合。
注意
這構成了舊多項式 API 的一部分。從版本 1.4 開始,首選在
numpy.polynomial中定義的新多項式 API。可以在過渡指南中找到差異摘要。擬合多項式
p(x) = p[0] * x**deg + ... + p[deg]學位度到點(x, y).返回係數向量p最小化訂單中的平方誤差度,度-1, …0.Polynomial.fit類方法推薦用於新代碼,因為它在數值上更穩定。有關詳細信息,請參閱該方法的文檔。- x: 數組, 形狀 (M,)
M 個采樣點的 x 坐標
(x[i], y[i])。- y: 數組, 形狀 (M,) 或 (M, K)
樣本點的 y 坐標。通過傳入每列包含一個數據集的 2D-array,可以一次擬合多個共享相同 x 坐標的樣本點數據集。
- deg: int
擬合多項式的次數
- rcond: 浮點數,可選
擬合的相對條件數。相對於最大奇異值小於此的奇異值將被忽略。默認值為 len(x)*eps,其中 eps 是浮點類型的相對精度,大多數情況下約為 2e-16。
- full: 布爾型,可選
開關確定返回值的性質。當它為 False(默認值)時,僅返回係數,當還返返回自奇異值分解的 True 診斷信息時。
- w: 數組,形狀(M,),可選
重量。如果不是 None,則權重
w[i]適用於x[i]處的未平方殘差y[i] - y_hat[i]。理想情況下,選擇權重以使產品w[i]*y[i]的誤差都具有相同的方差。使用 inverse-variance 加權時,請使用w[i] = 1/sigma(y[i])。默認值為無。- cov: bool 或 str,可選
如果給定而不是False,不僅返回估計值,還返回其協方差矩陣。默認情況下,協方差按 chi2/dof 縮放,其中 dof = M - (deg + 1),即,權重被假定為不可靠,除非在相對意義上,並且所有內容都被縮放,使得減少的 chi2 是統一的。如果
cov='unscaled',與權重為 w = 1/sigma 的情況相關,已知 sigma 是對不確定性的可靠估計。
- p: ndarray,形狀(deg + 1,)或(deg + 1,K)
多項式係數,最高功率優先。如果y是二維的,係數為k-th 數據集在
p[:,k].- 殘差,排名,singular_values,rcond
這些值僅在
full == True時返回殘差 - 最小二乘擬合的殘差平方和
- rank - 縮放的 Vandermonde 的有效等級
係數矩陣
- singular_values - 縮放的 Vandermonde 的奇異值
係數矩陣
rcond - rcond 的值。
有關詳細信息,請參閱
numpy.linalg.lstsq。- V: ndarray,形狀(M,M)或(M,M,K)
僅在以下情況下出現
full == False和cov == True.多項式係數估計的協方差矩陣。該矩陣的對角線是每個係數的方差估計。如果 y 是一個二維數組,那麽k-th 數據集在V[:,:,k]
- RankWarning
最小二乘擬合中係數矩陣的秩不足。僅當
full == False時才會引發警告。可以通過以下方式關閉警告
>>> import warnings >>> warnings.simplefilter('ignore', np.RankWarning)
參數:
返回:
警告:
注意:
該解決方案使平方誤差最小化
在等式中:
x[0]**n * p[0] + ... + x[0] * p[n-1] + p[n] = y[0] x[1]**n * p[0] + ... + x[1] * p[n-1] + p[n] = y[1] ... x[k]**n * p[0] + ... + x[k] * p[n-1] + p[n] = y[k]係數p的係數矩陣是Vandermonde矩陣。
polyfit發出一個RankWarning當最小二乘擬合條件不好時。這意味著由於數值誤差,最佳擬合並未明確定義。通過降低多項式次數或替換可以改善結果x經過x-x.mean()。這rcond參數也可以設置為小於其默認值的值,但結果擬合可能是虛假的:包括來自小的奇異值的貢獻可能會給結果添加數值噪聲。請注意,當多項式的次數很大或樣本點的間隔嚴重居中時,擬合多項式係數本質上是不良條件的。在這些情況下,應始終檢查配合質量。當多項式擬合不令人滿意時,樣條曲線可能是一個不錯的選擇。
參考:
維基百科,“Curve fitting”,https://en.wikipedia.org/wiki/Curve_fitting
維基百科,“Polynomial interpolation”,https://en.wikipedia.org/wiki/Polynomial_interpolation
1:
2:
例子:
>>> import warnings >>> x = np.array([0.0, 1.0, 2.0, 3.0, 4.0, 5.0]) >>> y = np.array([0.0, 0.8, 0.9, 0.1, -0.8, -1.0]) >>> z = np.polyfit(x, y, 3) >>> z array([ 0.08703704, -0.81349206, 1.69312169, -0.03968254]) # may vary使用
poly1d對象來處理多項式很方便:>>> p = np.poly1d(z) >>> p(0.5) 0.6143849206349179 # may vary >>> p(3.5) -0.34732142857143039 # may vary >>> p(10) 22.579365079365115 # may vary高階多項式可能會劇烈振蕩:
>>> with warnings.catch_warnings(): ... warnings.simplefilter('ignore', np.RankWarning) ... p30 = np.poly1d(np.polyfit(x, y, 30)) ... >>> p30(4) -0.80000000000000204 # may vary >>> p30(5) -0.99999999999999445 # may vary >>> p30(4.5) -0.10547061179440398 # may vary示例:
>>> import matplotlib.pyplot as plt >>> xp = np.linspace(-2, 6, 100) >>> _ = plt.plot(x, y, '.', xp, p(xp), '-', xp, p30(xp), '--') >>> plt.ylim(-2,2) (-2, 2) >>> plt.show()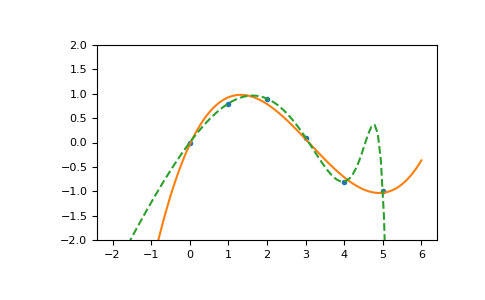
相關用法
- Python numpy polyder用法及代碼示例
- Python numpy polynomial.polyfit用法及代碼示例
- Python numpy polynomial.polyline用法及代碼示例
- Python numpy polynomial.polyadd用法及代碼示例
- Python numpy polynomial.polyder用法及代碼示例
- Python numpy polyutils.as_series用法及代碼示例
- Python numpy polynomial.polydomain用法及代碼示例
- Python numpy poly用法及代碼示例
- Python numpy polynomial.polyint用法及代碼示例
- Python numpy polysub用法及代碼示例
- Python numpy polyutils.getdomain用法及代碼示例
- Python numpy polyutils.mapdomain用法及代碼示例
- Python numpy polyutils.mapparms用法及代碼示例
- Python numpy polynomial.polydiv用法及代碼示例
- Python numpy polynomial.polyvalfromroots用法及代碼示例
- Python numpy polydiv用法及代碼示例
- Python numpy polynomial.polyval用法及代碼示例
- Python numpy polynomial.polysub用法及代碼示例
- Python numpy poly1d用法及代碼示例
- Python numpy polynomial.polyx用法及代碼示例
- Python numpy polyint用法及代碼示例
- Python numpy polyval用法及代碼示例
- Python numpy polynomial.set_default_printstyle用法及代碼示例
- Python numpy polymul用法及代碼示例
- Python numpy polynomial.polytrim用法及代碼示例
注:本文由純淨天空篩選整理自numpy.org大神的英文原創作品 numpy.polyfit。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。