Tidy 总结了有关模型组件的信息。模型组件可能是回归中的单个项、单个假设、聚类或类。 tidy 所认为的模型组件的确切含义因模型而异,但通常是不言而喻的。如果模型具有多种不同类型的组件,您将需要指定要返回哪些组件。
参数
- x
-
从
stats::nls()返回的nls对象。 - conf.int
-
逻辑指示是否在整理的输出中包含置信区间。默认为
FALSE。 - conf.level
-
用于置信区间的置信水平(如果
conf.int = TRUE)。必须严格大于 0 且小于 1。默认为 0.95,对应于 95% 的置信区间。 - ...
-
附加参数。不曾用过。仅需要匹配通用签名。注意:拼写错误的参数将被吸收到
...中,并被忽略。如果拼写错误的参数有默认值,则将使用默认值。例如,如果您传递conf.lvel = 0.9,所有计算将使用conf.level = 0.95进行。这里有两个异常:
也可以看看
tidy、stats::nls()、stats::summary.nls()
其他 nls 整理器:augment.nls() 、glance.nls()
值
带有列的 tibble::tibble():
- conf.high
-
估计置信区间的上限。
- conf.low
-
估计置信区间的下限。
- estimate
-
回归项的估计值。
- p.value
-
与观察到的统计量相关的两侧 p 值。
- statistic
-
在回归项非零的假设中使用的 T-statistic 的值。
- std.error
-
回归项的标准误差。
- term
-
回归项的名称。
例子
# fit model
n <- nls(mpg ~ k * e^wt, data = mtcars, start = list(k = 1, e = 2))
# summarize model fit with tidiers + visualization
tidy(n)
#> # A tibble: 2 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 k 49.7 3.79 13.1 5.96e-14
#> 2 e 0.746 0.0199 37.5 8.86e-27
augment(n)
#> # A tibble: 32 × 4
#> mpg wt .fitted .resid
#> <dbl> <dbl> <dbl> <dbl>
#> 1 21 2.62 23.0 -2.01
#> 2 21 2.88 21.4 -0.352
#> 3 22.8 2.32 25.1 -2.33
#> 4 21.4 3.22 19.3 2.08
#> 5 18.7 3.44 18.1 0.611
#> 6 18.1 3.46 18.0 0.117
#> 7 14.3 3.57 17.4 -3.11
#> 8 24.4 3.19 19.5 4.93
#> 9 22.8 3.15 19.7 3.10
#> 10 19.2 3.44 18.1 1.11
#> # ℹ 22 more rows
glance(n)
#> # A tibble: 1 × 9
#> sigma isConv finTol logLik AIC BIC deviance df.residual nobs
#> <dbl> <lgl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 2.67 TRUE 0.00000204 -75.8 158. 162. 214. 30 32
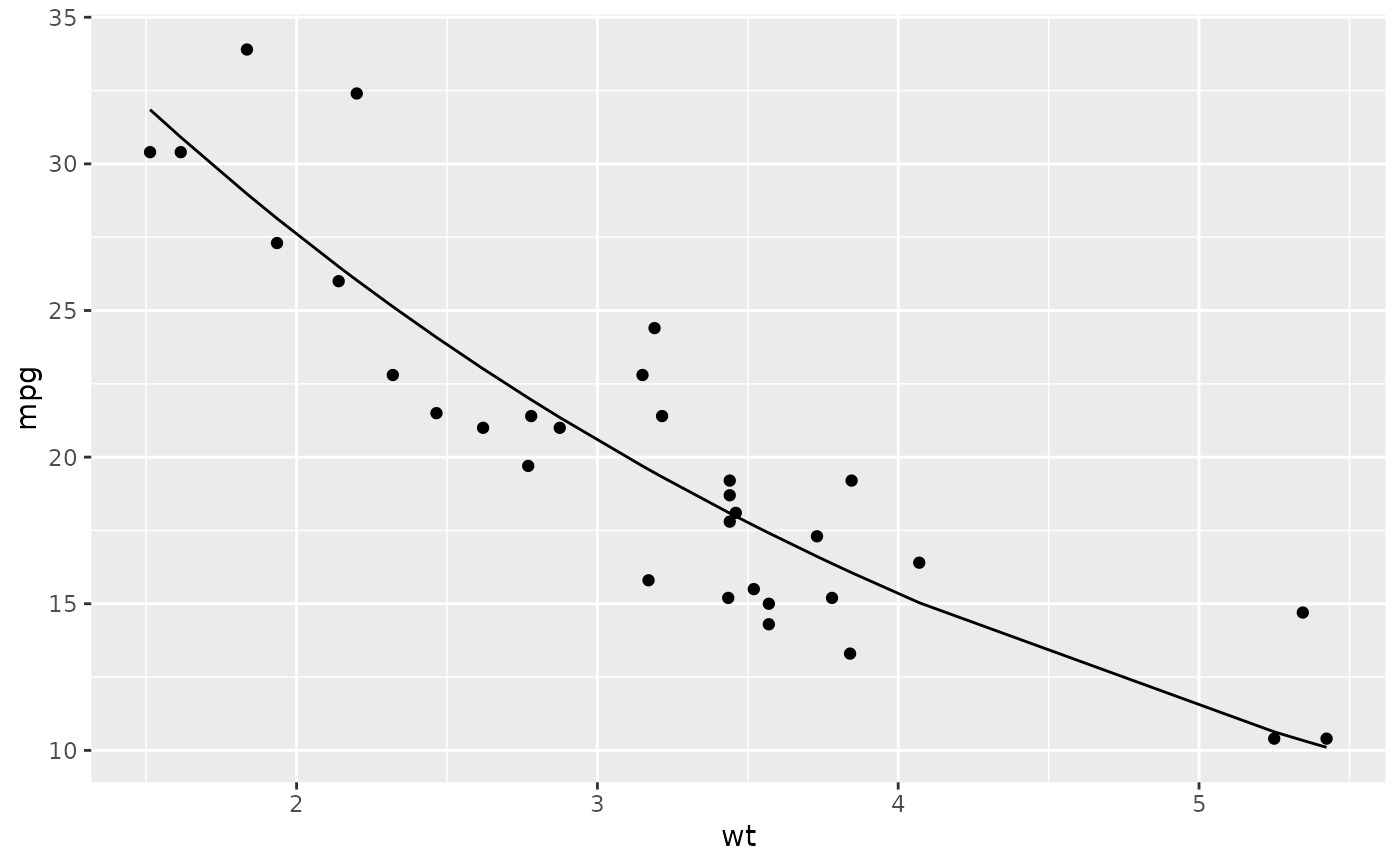
library(ggplot2)
ggplot(augment(n), aes(wt, mpg)) +
geom_point() +
geom_line(aes(y = .fitted))
 newdata <- head(mtcars)
newdata$wt <- newdata$wt + 1
augment(n, newdata = newdata)
#> # A tibble: 6 × 13
#> .rownames mpg cyl disp hp drat wt qsec vs am gear
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Mazda RX4 21 6 160 110 3.9 3.62 16.5 0 1 4
#> 2 Mazda RX4 W… 21 6 160 110 3.9 3.88 17.0 0 1 4
#> 3 Datsun 710 22.8 4 108 93 3.85 3.32 18.6 1 1 4
#> 4 Hornet 4 Dr… 21.4 6 258 110 3.08 4.22 19.4 1 0 3
#> 5 Hornet Spor… 18.7 8 360 175 3.15 4.44 17.0 0 0 3
#> 6 Valiant 18.1 6 225 105 2.76 4.46 20.2 1 0 3
#> # ℹ 2 more variables: carb <dbl>, .fitted <dbl>
newdata <- head(mtcars)
newdata$wt <- newdata$wt + 1
augment(n, newdata = newdata)
#> # A tibble: 6 × 13
#> .rownames mpg cyl disp hp drat wt qsec vs am gear
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Mazda RX4 21 6 160 110 3.9 3.62 16.5 0 1 4
#> 2 Mazda RX4 W… 21 6 160 110 3.9 3.88 17.0 0 1 4
#> 3 Datsun 710 22.8 4 108 93 3.85 3.32 18.6 1 1 4
#> 4 Hornet 4 Dr… 21.4 6 258 110 3.08 4.22 19.4 1 0 3
#> 5 Hornet Spor… 18.7 8 360 175 3.15 4.44 17.0 0 0 3
#> 6 Valiant 18.1 6 225 105 2.76 4.46 20.2 1 0 3
#> # ℹ 2 more variables: carb <dbl>, .fitted <dbl>
相关用法
- R broom tidy.nlrq 整理 a(n) nlrq 对象
- R broom tidy.negbin 整理 a(n) negbin 对象
- R broom tidy.robustbase.glmrob 整理 a(n) glmrob 对象
- R broom tidy.acf 整理 a(n) acf 对象
- R broom tidy.robustbase.lmrob 整理 a(n) lmrob 对象
- R broom tidy.biglm 整理 a(n) biglm 对象
- R broom tidy.garch 整理 a(n) garch 对象
- R broom tidy.rq 整理 a(n) rq 对象
- R broom tidy.kmeans 整理 a(n) kmeans 对象
- R broom tidy.betamfx 整理 a(n) betamfx 对象
- R broom tidy.anova 整理 a(n) anova 对象
- R broom tidy.btergm 整理 a(n) btergm 对象
- R broom tidy.cv.glmnet 整理 a(n) cv.glmnet 对象
- R broom tidy.roc 整理 a(n) roc 对象
- R broom tidy.poLCA 整理 a(n) poLCA 对象
- R broom tidy.emmGrid 整理 a(n) emmGrid 对象
- R broom tidy.Kendall 整理 a(n) Kendall 对象
- R broom tidy.survreg 整理 a(n) survreg 对象
- R broom tidy.ergm 整理 a(n) ergm 对象
- R broom tidy.pairwise.htest 整理 a(n)pairwise.htest 对象
- R broom tidy.coeftest 整理 a(n) coeftest 对象
- R broom tidy.polr 整理 a(n) polr 对象
- R broom tidy.map 整理 a(n) Map对象
- R broom tidy.survexp 整理 a(n) survexp 对象
- R broom tidy.margins 整理 a(n) 边距对象
注:本文由纯净天空筛选整理自等大神的英文原创作品 Tidy a(n) nls object。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。