Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas str.count()方法用于计算一系列字符串中每个字符串或正则表达式模式的出现。还可以传递其他标志参数来处理以修改正则表达式的某些方面,例如区分大小写,多行匹配等。
由于这是一个pandas字符串方法,因此仅适用于字符串系列,并且.str在每次调用此方法之前都必须加上前缀。否则,将产生错误。
用法:Series.str.count(pat, flags=0)
参数:
pat:要在串联的字符串中搜索的字符串或正则表达式
flags:可以传递的正则表达式标志(A,S,L,M,I,X),默认值为0,表示无。对于此正则表达式模块(re)也必须导入。
返回类型:系列,每个字符串中已通过字符的出现次数。
要下载代码中使用的CSV,请点击此处。
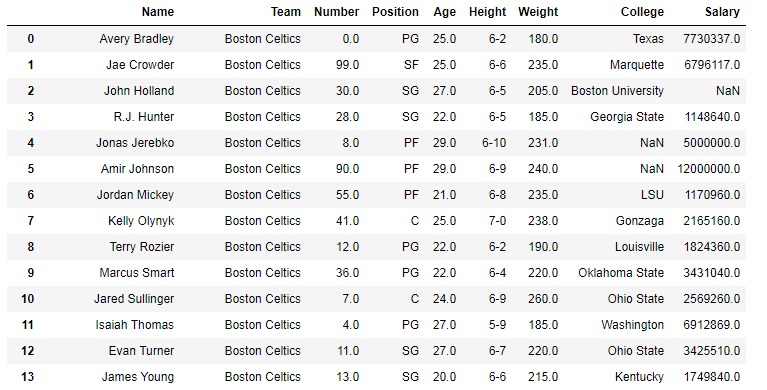
在以下示例中,使用的 DataFrame 包含一些NBA球员的数据。下面是任何操作之前的数据帧图像。
范例1:计数单词出现
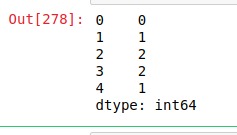
在此示例中,从列表中创建了一个 Pandas 系列,并使用str.count()方法对gfg的出现进行计数。
# importing pandas package
import pandas as pd
# making list
list =["GeeksforGeeks", "Geeksforgeeks", "geeksforgeeks",
"geeksforgeeks is a great platform", "for tech geeks"]
# making series
series = pd.Series(list)
# counting occurrence of geeks
count = series.str.count("geeks")
# display
count输出:
如输出图像所示,显示了每个字符串中出现的极客,并且由于第一个大写字母而没有计算极客。
范例2:使用标志
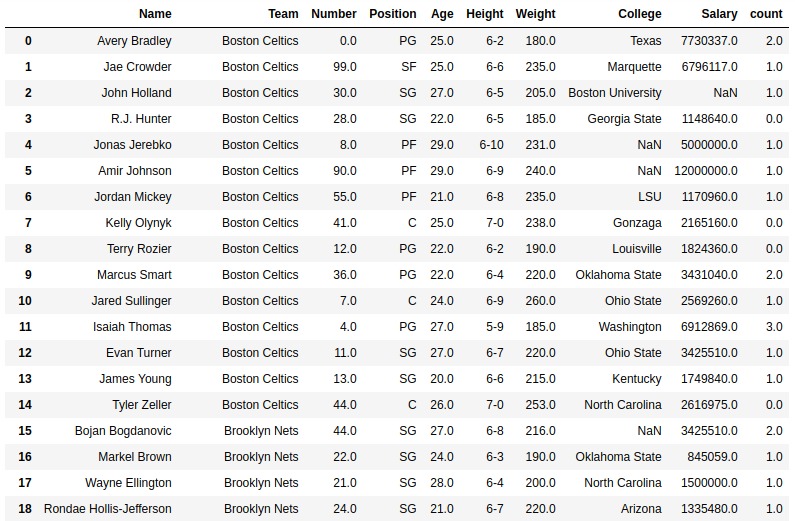
在此的示例“a”出现在名称列中。还使用了flag参数,并将re.I传递给它,这意味着IGNORECASE。因此,在计数期间将同时考虑a和A。
# importing pandas module
import pandas as pd
# importing module for regex
import re
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# String to be searched in start of string
search ="a"
# count of occurrence of a and creating new column
data["count"]= data["Name"].str.count(search, re.I)
# display
data输出:
如输出图像中所示,通过查看第一个索引本身可以清楚地进行比较,Avery Bradely中a的计数为2,这意味着要同时考虑大写和小写。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas Series.str.count()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。