Python是進行數據分析的一種出色語言,主要是因為以數據為中心的Python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas str.count()方法用於計算一係列字符串中每個字符串或正則表達式模式的出現。還可以傳遞其他標誌參數來處理以修改正則表達式的某些方麵,例如區分大小寫,多行匹配等。
由於這是一個pandas字符串方法,因此僅適用於字符串係列,並且.str在每次調用此方法之前都必須加上前綴。否則,將產生錯誤。
用法:Series.str.count(pat, flags=0)
參數:
pat:要在串聯的字符串中搜索的字符串或正則表達式
flags:可以傳遞的正則表達式標誌(A,S,L,M,I,X),默認值為0,表示無。對於此正則表達式模塊(re)也必須導入。
返回類型:係列,每個字符串中已通過字符的出現次數。
要下載代碼中使用的CSV,請點擊此處。
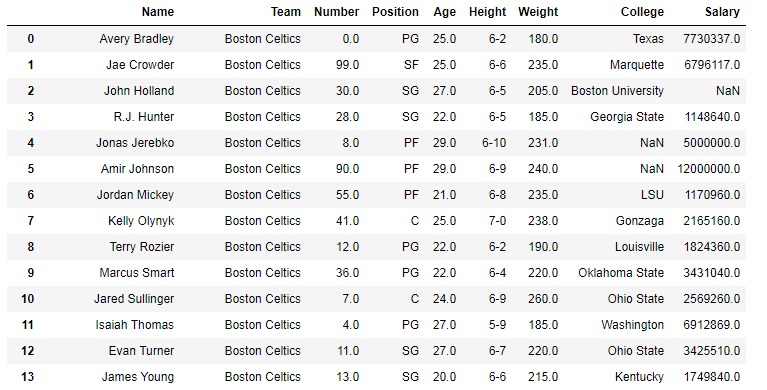
在以下示例中,使用的 DataFrame 包含一些NBA球員的數據。下麵是任何操作之前的數據幀圖像。
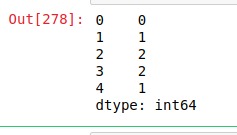
範例1:計數單詞出現
在此示例中,從列表中創建了一個 Pandas 係列,並使用str.count()方法對gfg的出現進行計數。
# importing pandas package
import pandas as pd
# making list
list =["GeeksforGeeks", "Geeksforgeeks", "geeksforgeeks",
"geeksforgeeks is a great platform", "for tech geeks"]
# making series
series = pd.Series(list)
# counting occurrence of geeks
count = series.str.count("geeks")
# display
count輸出:
如輸出圖像所示,顯示了每個字符串中出現的極客,並且由於第一個大寫字母而沒有計算極客。
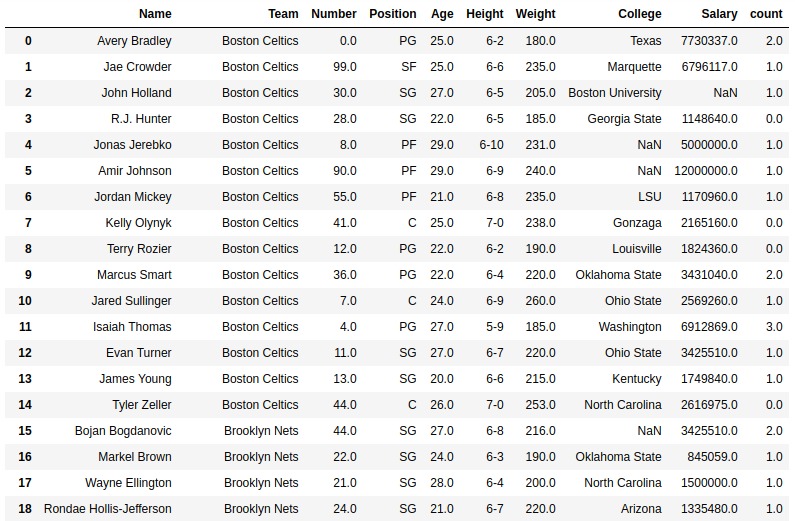
範例2:使用標誌
在此的示例“a”出現在名稱列中。還使用了flag參數,並將re.I傳遞給它,這意味著IGNORECASE。因此,在計數期間將同時考慮a和A。
# importing pandas module
import pandas as pd
# importing module for regex
import re
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# String to be searched in start of string
search ="a"
# count of occurrence of a and creating new column
data["count"]= data["Name"].str.count(search, re.I)
# display
data輸出:
如輸出圖像中所示,通過查看第一個索引本身可以清楚地進行比較,Avery Bradely中a的計數為2,這意味著要同時考慮大寫和小寫。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Series.str.count()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。