Python是進行數據分析的一種出色語言,主要是因為以數據為中心的Python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Python Series.add()用於向調用者係列添加係列或列出長度相同的對象。
用法:Series.add(other, level=None, fill_value=None, axis=0)
參數:
other:要添加到調用者係列中的其他係列或列表類型
fill_value:添加前要在係列/列表中用NaN替換的值
level:多索引時級別的整數值
返回類型:帶附加值的來電者係列
要下載以下示例中使用的數據集,請單擊此處。在以下示例中,使用的 DataFrame 包含一些NBA球員的數據。下麵是任何操作之前的數據幀圖像。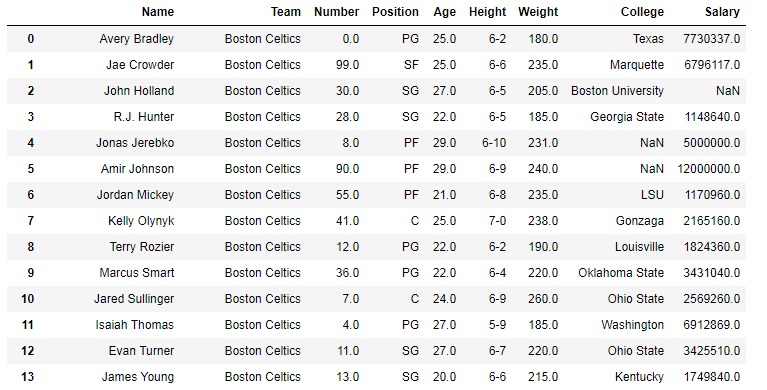
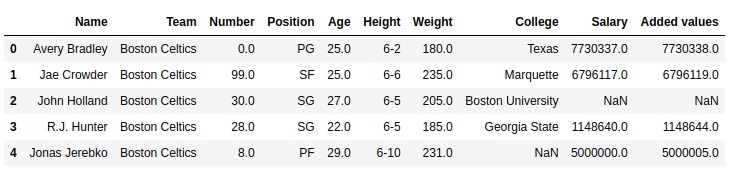
範例1:新增清單
在此示例中,使用.head()方法將前5行存儲在新變量中。之後,創建一個相同長度的列表,並使用將其添加到薪金列.add()方法
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# creating short data of 5 rows
short_data = data.head()
# creating list with 5 values
list =[1, 2, 3, 4, 5]
# adding list data
# creating new column
short_data["Added values"]= short_data["Salary"].add(list)
# display
short_data
輸出:
如輸出圖像中所示,可以將“增加值”列與“薪金”列+列表的增加值進行比較。
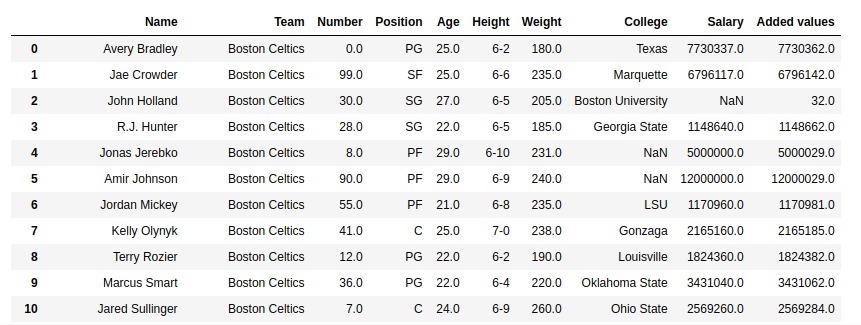
範例2:將係列添加到具有空值的係列
在此示例中,“年齡”列被添加到“工資”列。由於salary列也包含空值,因此無論添加什麽內容,默認情況下它都會返回NaN。在此示例中,傳遞了5以將空值替換為5。
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# age series
age = data["Age"]
# na replacement
na = 5
# adding values
# storing to new column
data["Added values"]= data["Salary"].add(other = age, fill_value = na)
# display
data輸出:
如輸出圖像中所示,在Null值的情況下,Added value列已將age列與5相加。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
- Python Pandas Series.dt.tz用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Series.add()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。