Pandas 系列是带有轴标签的一维ndarray。标签不必是唯一的,但必须是可哈希的类型。该对象同时支持基于整数和基于标签的索引,并提供了许多方法来执行涉及索引的操作。
Pandas Series.describe()函数会生成描述性统计信息,以汇总给定系列对象的数据集分布的集中趋势,离散度和形状。通过排除NaN值来执行所有计算。
用法: Series.describe(percentiles=None, include=None, exclude=None)
参数:
percentiles:要包含在输出中的百分比。
include:要包含在结果中的数据类型的白名单。忽略系列。
exclude:要从结果中忽略的数据类型黑名单。忽略系列
返回:系列摘要统计
范例1:采用Series.describe()函数查找给定系列对象的摘要统计信息。
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series([80, 25, 3, 25, 24, 6])
# Create the Index
index_ = ['Coca Cola', 'Sprite', 'Coke', 'Fanta', 'Dew', 'ThumbsUp']
# set the index
sr.index = index_
# Print the series
print(sr)输出:

现在我们将使用Series.describe()函数以查找给定系列对象中基础数据的摘要统计信息。
# find summary statistics of the underlying
# data in the given series object.
result = sr.describe()
# Print the result
print(result)输出:
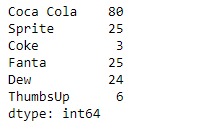
正如我们在输出中看到的,Series.describe()函数已成功返回给定系列对象的摘要统计信息。
范例2:采用Series.describe()函数以查找给定系列对象中基础数据的摘要统计信息。给定的系列对象包含一些缺失值。
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series([100, None, None, 18, 65, None, 32, 10, 5, 24, None])
# Create the Index
index_ = pd.date_range('2010-10-09', periods = 11, freq ='M')
# set the index
sr.index = index_
# Print the series
print(sr)输出:
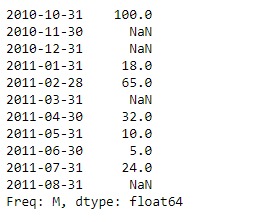
现在我们将使用Series.describe()函数以查找给定系列对象中基础数据的摘要统计信息。
# find summary statistics of the underlying
# data in the given series object.
result = sr.describe()
# Print the result
print(result)输出:
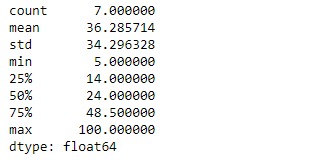
正如我们在输出中看到的,Series.describe()函数已成功返回给定系列对象的摘要统计信息。NaN计算这些统计值时,将忽略这些值。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas Series.describe()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。