Pandas 索引是一个不变的ndarray,它实现了有序的,可切片的集合。它是存储所有 Pandas 对象的轴标签的基本对象。
Pandas Index.nbytes属性返回存储给定Index对象的基础数据所需的字节数。
用法: Index.nbytes
参数:没有
返回:存储数据所需的字节数
范例1:采用Index.nbytes属性以找出存储给定Index对象的基础数据所需的字节数。
# importing pandas as pd
import pandas as pd
# Creating the index
idx = pd.Index(['Melbourne', 'Sanghai', 'Lisbon', 'Doha', 'Moscow', 'Rio'])
# Print the index
print(idx)输出:
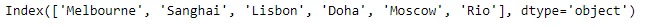
现在我们将使用Index.nbytes属性以找出将数据存储在给定Index对象中所需的字节数。
# return the number of bytes occupied
# by idx object
result = idx.nbytes
# Print the result
print(result)输出:

正如我们在输出中看到的,Index.nbytes属性已返回48,表示需要48个字节才能将数据存储在给定的Index对象中。
范例2:采用Index.nbytes属性以找出存储给定Index对象的基础数据所需的字节数。
# importing pandas as pd
import pandas as pd
# Creating the index
idx = pd.Index([900 + 3j, 700 + 25j, 620 + 10j, 388 + 44j, 900])
# Print the index
print(idx)输出:
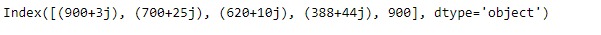
现在我们将使用Index.nbytes属性以找出将数据存储在给定Index对象中所需的字节数。
# return the number of bytes occupied
# by idx object
result = idx.nbytes
# Print the result
print(result)输出:

正如我们在输出中看到的,Index.nbytes属性已返回40,表示将数据存储在给定的Index对象中需要40个字节。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas Index.nbytes。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。