Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas sample()用于根据函数调用程序数据帧生成样本随机行或列。
用法:
DataFrame.sample(n =无,frac =无,replace = False,权重=无,random_state =无,轴=无)
参数:
n:int值,要生成的随机行数。
frac:浮点值,返回(浮点值*数据帧值的长度)。 frac不能与n一起使用。
replace:布尔值,如果为True,则返回带有替换值的样本。
axis:行是0或“行”,列是1或“列”。
返回类型:与调用者类型相同的新对象。
要下载使用的CSV文件,请单击此处。
范例1: DataFrame 中的随机行
在此示例中,通过.sample()方法生成了两个随机行,并在以后进行比较。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# generating one row
row1 = data.sample(n = 1)
# display
row1
# generating another row
row2 = data.sample(n = 1)
# display
row2输出:
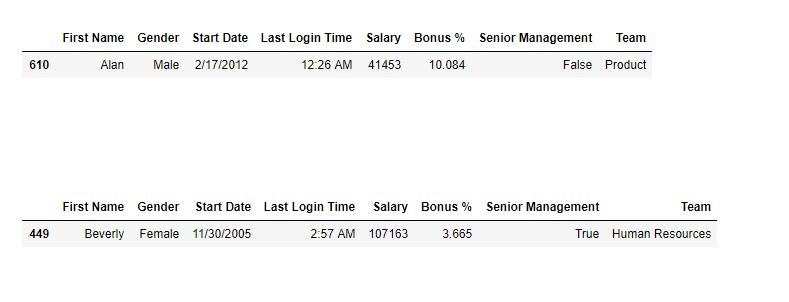
如输出图像所示,生成的两个随机样本行彼此不同。
范例2:生成25%的数据帧样本
在此示例中,从数据帧中生成了25%的随机样本数据。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# generating one row
rows = data.sample(frac =.25)
# checking if sample is 0.25 times data or not
if (0.25*(len(data))== len(rows)):
print( "Cool")
print(len(data), len(rows))
# display
rows输出:
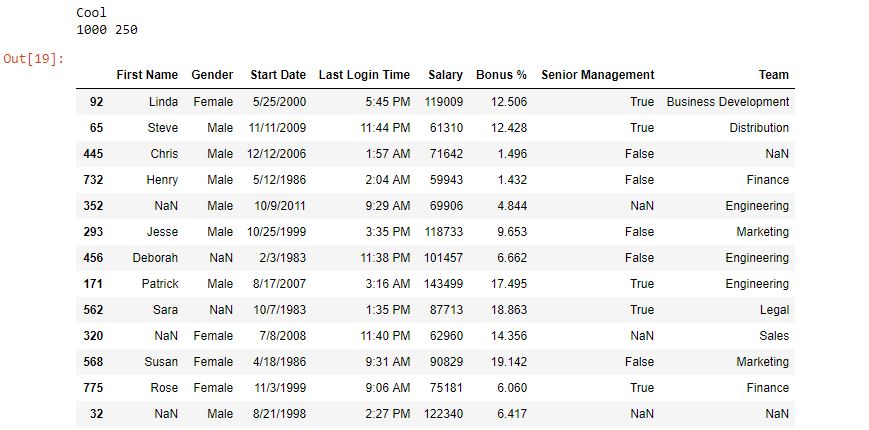
如输出图像所示,生成的样本长度为数据帧的25%。另外,样本是随机生成的。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas Dataframe.sample()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。