Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas sample()用於根據函數調用程序數據幀生成樣本隨機行或列。
用法:
DataFrame.sample(n =無,frac =無,replace = False,權重=無,random_state =無,軸=無)
參數:
n:int值,要生成的隨機行數。
frac:浮點值,返回(浮點值*數據幀值的長度)。 frac不能與n一起使用。
replace:布爾值,如果為True,則返回帶有替換值的樣本。
axis:行是0或“行”,列是1或“列”。
返回類型:與調用者類型相同的新對象。
要下載使用的CSV文件,請單擊此處。
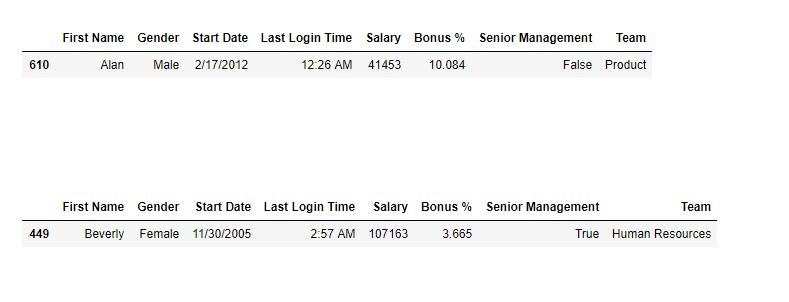
範例1: DataFrame 中的隨機行
在此示例中,通過.sample()方法生成了兩個隨機行,並在以後進行比較。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# generating one row
row1 = data.sample(n = 1)
# display
row1
# generating another row
row2 = data.sample(n = 1)
# display
row2輸出:
如輸出圖像所示,生成的兩個隨機樣本行彼此不同。
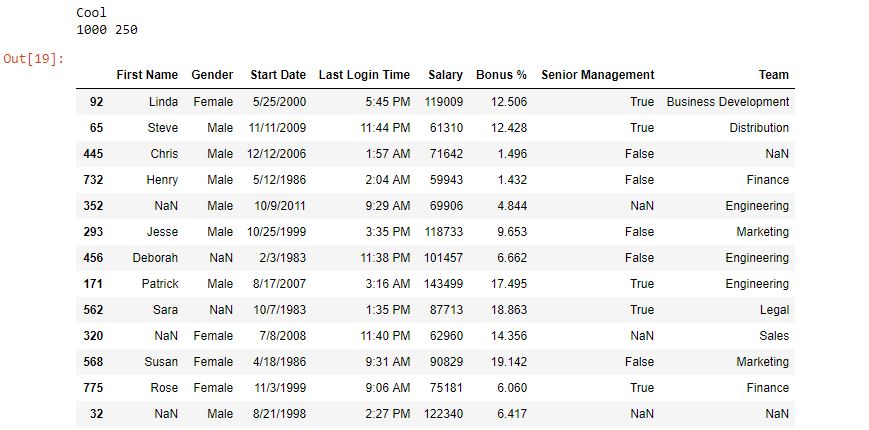
範例2:生成25%的數據幀樣本
在此示例中,從數據幀中生成了25%的隨機樣本數據。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# generating one row
rows = data.sample(frac =.25)
# checking if sample is 0.25 times data or not
if (0.25*(len(data))== len(rows)):
print( "Cool")
print(len(data), len(rows))
# display
rows輸出:
如輸出圖像所示,生成的樣本長度為數據幀的25%。另外,樣本是隨機生成的。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Dataframe.sample()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。