Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas Dataframe.rank()方法返回传递的系列的每个索引的等级。排序后根据排名返回排名。
用法:
DataFrame.rank(axis=0, method=’average’, numeric_only=None, na_option=’keep’, ascending=True, pct=False)
参数:
axis:行为0或“索引”,列为1或“列”。
method:接受一个字符串输入(“平均值”,“最小”,“最大”,“第一”,“密集”),该字符串告诉 Pandas 如何处理相同的值。默认值为平均值,这意味着将等级的平均值分配给相似的值。
numeric_only:接受一个布尔值,并且只有当它为False时,rank函数才能对非数字值起作用。
na_option:接受3个字符串输入(“ keep”,“ top”,“ bottom”)来设置Null值在传递的Series中的位置。
ascending:如果为True,则按升序排列的布尔值。
pct:布尔值,如果为True,则按百分比排序。
返回类型:具有调用者系列的每个索引的排名的系列。
有关在“代码中使用”的CSV文件的链接,请单击此处。
范例1:具有唯一值的排名列
在下面的示例中,将创建一个新的排名列,该列将对每个Player的名称进行排名。 “名称”列中的所有值都是唯一的,因此无需描述方法。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# creating a rank column and passing the returned rank series
data["Rank"] = data["Name"].rank()
# display
data
# sorting w.r.t name column
data.sort_values("Name", inplace = True)
# display after sorting w.r.t Name column
data输出:
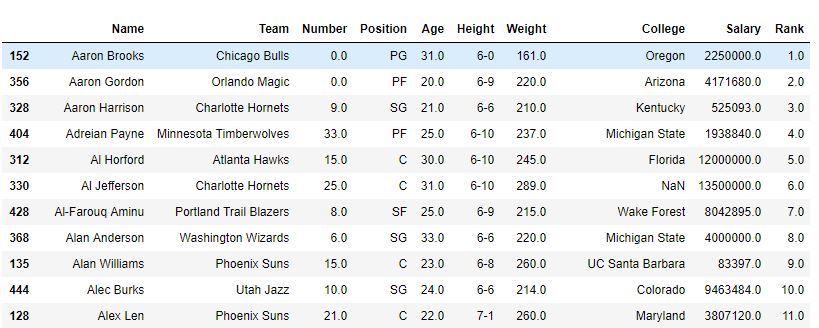
如图中所示,使用每个Name的等级创建了一个列等级。在sort_value函数根据名称对数据帧进行排序之后,可以看出,由于这些仅是对Names的排名,因此该排名也已排序。
排序前-
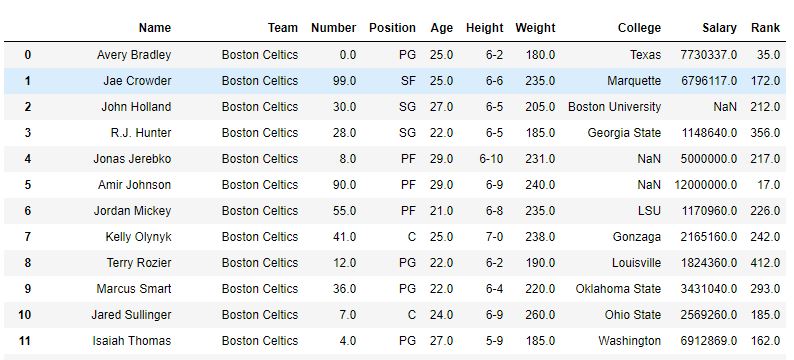
排序后-
范例2:具有一些相似值的排序列
在下面的示例中,首先根据球队名称对 DataFrame 进行排序,然后首先使用默认方法(即平均),因此,相同球队队员的排名是平均。之后,还使用min方法查看输出。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# sorting w.r.t team name
data.sort_values("Team", inplace = True)
# creating a rank column and passing the returned rank series
# change method to 'min' to rank by minimum
data["Rank"] = data["Team"].rank(method ='average')
# display
data输出:
使用method =“平均值”
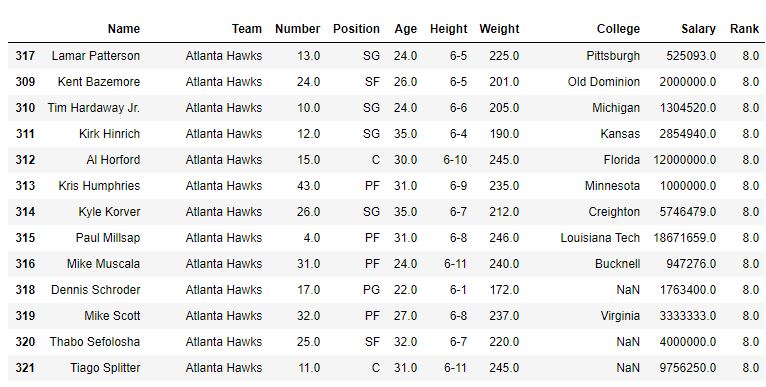
使用method ='min'
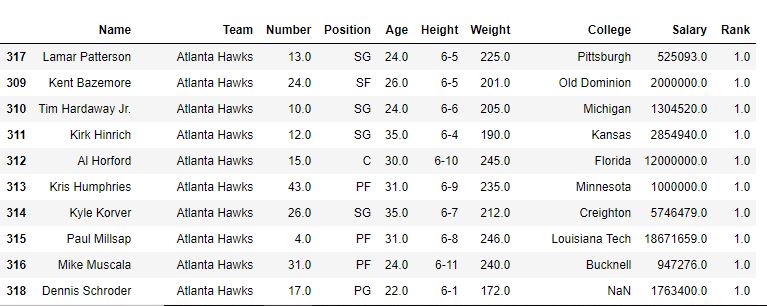
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas Dataframe.rank()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。