Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas Dataframe.rank()方法返回傳遞的係列的每個索引的等級。排序後根據排名返回排名。
用法:
DataFrame.rank(axis=0, method=’average’, numeric_only=None, na_option=’keep’, ascending=True, pct=False)
參數:
axis:行為0或“索引”,列為1或“列”。
method:接受一個字符串輸入(“平均值”,“最小”,“最大”,“第一”,“密集”),該字符串告訴 Pandas 如何處理相同的值。默認值為平均值,這意味著將等級的平均值分配給相似的值。
numeric_only:接受一個布爾值,並且隻有當它為False時,rank函數才能對非數字值起作用。
na_option:接受3個字符串輸入(“ keep”,“ top”,“ bottom”)來設置Null值在傳遞的Series中的位置。
ascending:如果為True,則按升序排列的布爾值。
pct:布爾值,如果為True,則按百分比排序。
返回類型:具有調用者係列的每個索引的排名的係列。
有關在“代碼中使用”的CSV文件的鏈接,請單擊此處。
範例1:具有唯一值的排名列
在下麵的示例中,將創建一個新的排名列,該列將對每個Player的名稱進行排名。 “名稱”列中的所有值都是唯一的,因此無需描述方法。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# creating a rank column and passing the returned rank series
data["Rank"] = data["Name"].rank()
# display
data
# sorting w.r.t name column
data.sort_values("Name", inplace = True)
# display after sorting w.r.t Name column
data輸出:
如圖中所示,使用每個Name的等級創建了一個列等級。在sort_value函數根據名稱對數據幀進行排序之後,可以看出,由於這些僅是對Names的排名,因此該排名也已排序。
排序前-
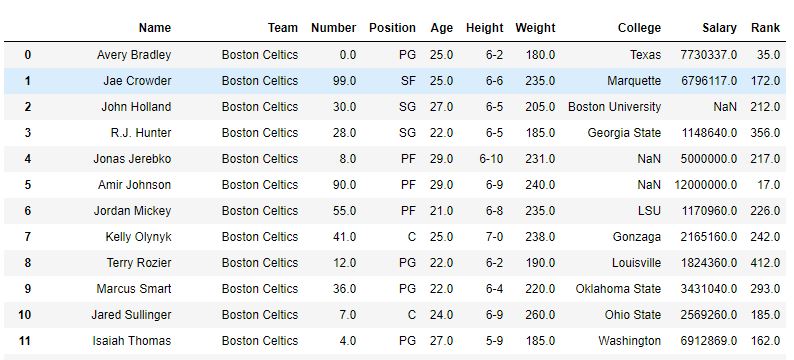
排序後-
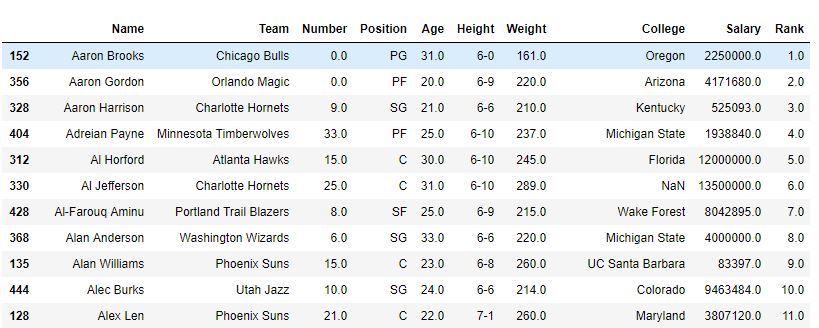
範例2:具有一些相似值的排序列
在下麵的示例中,首先根據球隊名稱對 DataFrame 進行排序,然後首先使用默認方法(即平均),因此,相同球隊隊員的排名是平均。之後,還使用min方法查看輸出。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# sorting w.r.t team name
data.sort_values("Team", inplace = True)
# creating a rank column and passing the returned rank series
# change method to 'min' to rank by minimum
data["Rank"] = data["Team"].rank(method ='average')
# display
data輸出:
使用method =“平均值”
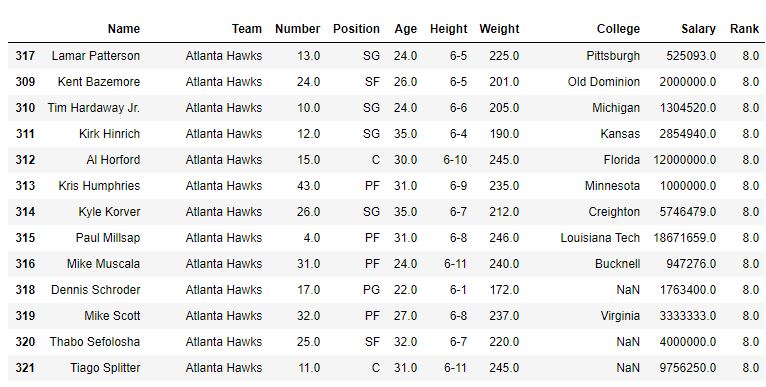
使用method ='min'
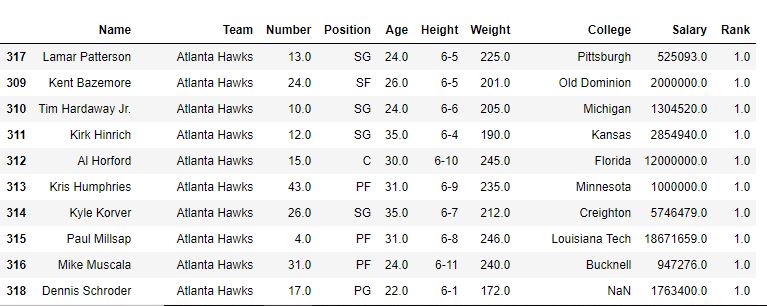
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Dataframe.rank()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。