这篇文章是结合论文http://www.cqvip.com/Main/Detail.aspx?id=7707219对博文:http://www.cnblogs.com/hexinuaa/p/3353479.html加入自己的理解做了简化重写,另外本文末尾附上了最大熵模型的实现。
一个例子 我们通过一个简单的例子来了解最大熵的概念。假设现在需要做一个自动将英语到法语的翻译模型,为了方便说明,我们将这个问题简化为将英文句子中的单词{in}翻译成法语词汇。那么翻译模型p就是对于给定包含单词”in”的英文句子,需要给出选择某个法语单词f 做为”in”的翻译结果的概率p(f)。为了帮助开发这个模型,需要收集大量已经翻译好的样本数据。收集好样本之后,接下来需要做两件事情:一是从样本中抽取规则(特征),二是基于这些规则建立模型。
从样本中我们能得到的第一个规则就是in可能被翻译成的法语词汇有:
{dans, en, à, au cours de, pendant}。
也就是说,我们可以给模型p施加第一个约束条件:
p(dans)+p(en)+ p(à)+p(au cours de)+p(pendant) = 1。
这个等式是翻译模型可以用到的第一个对样本的统计信息。显然,有无数可以满足上面约束的模型p可供选择,例如:
p(dans)=1,即这个模型总是预测dans
或者
p(pendant)=1/2 and p(à)=1/2,即模型要么选择预测pendant,要么预测à。
这两个模型都只是在没有足够经验数据的情况下,做的大胆假设。事实上我们只知道当前可能的选项是5个法语词汇,没法确定究竟哪个概率分布式正确。那么,一个更合理的模型假设可能是:
p(dans) = 1/5
p(en) = 1/5
p(à) = 1/5
p(au cours de) = 1/5
p(pendant) = 1/5
即该模型将概率均等地分给5个词汇。但现实情况下,肯定不会这么简单,所以我们尝试收集更多的经验知识。假设我们从语料中发现有30%的情况下,in会被翻译成dans 或者en,那么运用这个知识来更新我们的模型,得到2模型约束:
p(dans) + p(en) = 3/10
p(dans)+p(en)+ p(à)+p(au cours de)+p(pendant) = 1
同样,还是有很多概率分布满足这两个约束。在没有其他知识的情况下,最直观的模型p应该是最均匀的模型(例如,我拿出一个色子问你丢出5的概率是多少,你肯定会回答1/6),也就是在满足约束条件的情况下,将概率均等分配:
p(dans) = 3/20
p(en) = 3/20
p(à) = 7/30
p(au cours de) = 7/30
p(pendant) = 7/30
假设我们再一次观察样本数据,发现:有一半的情况,in被翻译成了dans 或 à。这样,我们有就了3个模型约束:
p(dans) + p(en) = 3/10
p(dans)+p(en)+ p(à)+p(au cours de)+p(pendant) = 1
p(dans)+ p(à)=1/2
我们可以再一次选择满足3个约束的最均匀的模型p,但这一次结果没有那么明显。由于经验知识的增加,问题的复杂度也增加了,归结起来,我们要解决两组问题:第一,均匀(uniform)究竟是什么意思?我们怎样度量一个模型的均匀度(uniformity)?第二,有了上述两个问题的答案,我们如何找到满足所有约束并且均匀的模型?
最大熵算法可以回答上面的2组问题。直观上来将,很简单,即:对已知的知识建模,对未知的知识不做任何假设。换句话说,在给定一组事实(features + output)的情况下,选择符合所有事实,且在其他方面尽可能均匀的模型。这也是我们在上面的例子中,每次选择最恰当的模型用到的原理。俗话说,不把鸡蛋放在一个篮子里,正是运用的这个原理来规避风险。
最大熵(MaxEnt)建模
我们考察一个随机过程,它的输出是y, y属于有穷集合Y。对于上面提到的例子,该过程输出”in”的翻译结果y, y∈Y = {dans, en, à, au cours de, pendant}。在输出y时,该过程会受到”in”在句子中上下文信息x的影响, x属于有穷集合X。在上文的例子中,这个x主要就是在英文句子中”in”周围的单词。
我们的任务就是构造一个统计模型,该模型的任务是:在给定上下文x的情况下,输出y的概率p(y|x)。
训练数据
为了研究上述过程,我们观察一段时间随机过程的行为,收集到大量的样本数据:(x1, y1), (x2, y2), …, (xN, yN)。在之前讨论的例子中,每个样本包括:在英文句子中”in”周围的单词x,”in”的翻译y。假设我们已经拿到了足够多的训练样本,我们可以用样本的经验分布p~来表示所有样本的分布特性:
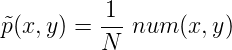
其中N为训练样本的大小, num(x,y)是样本中某一对(x,y)同时出现的次数。
特征和约束
我们的目标是构造一个能产生训练样本这一随机过程p~(x,y)的统计模型。而我们能够使用的数据就是对训练样本的各种统计信息或者说特征。定义特征如下:

这个也叫指示函数(indicator function),它表示某个特定的x和某个特定的y之间是否有一定的关系。例如,在之前的例子中,如果April这个词出现在in之后,那么in会被翻译成en,那么这个特征可以表示成:
 特征f(x,y)关于训练样本经验分布p~(x,y)的期望如下,这个是我们可以在语料中统计到的特征经验值:
特征f(x,y)关于训练样本经验分布p~(x,y)的期望如下,这个是我们可以在语料中统计到的特征经验值:
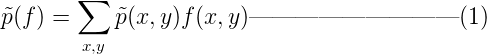
而特征关于模型分布p(y|x)的理论期望值是:
 其中p~(x)是x在训练样本中的经验分布。我们约束这一期望值和训练样本中的经验值相等:即要求期望概率值等于经验概率值。
其中p~(x)是x在训练样本中的经验分布。我们约束这一期望值和训练样本中的经验值相等:即要求期望概率值等于经验概率值。
![]() 结合等式(1)(2)(3)我们得到等式:
结合等式(1)(2)(3)我们得到等式:
 我们称等式(3)为约束(constraint)。我们只关注满足约束(3)的模型p(y|x),也就是说不再考察跟训练样本的特征经验值不一致的模型。
我们称等式(3)为约束(constraint)。我们只关注满足约束(3)的模型p(y|x),也就是说不再考察跟训练样本的特征经验值不一致的模型。
到这里,我们已经有办法来表示训练样本中内在的统计现象(p~(f)),同时也有办法来让模型拟合这一现象(p(f) = p~(f))。
最大熵原理
再回到之前例子中的问题:什么是均匀?
数学上,条件分布p(y|x)的均匀度就是条件熵,定义如下:
 熵的最小值是0,这时模型没有任何不确定性;熵的最大值是log|Y|, 即在所有可能的y(|Y|个)上的均匀分布。
熵的最小值是0,这时模型没有任何不确定性;熵的最大值是log|Y|, 即在所有可能的y(|Y|个)上的均匀分布。
有了这个条件熵,最大熵的原理定义为:当从允许的概率分布集合C中选择一个模型时,选择模型p*∈C ,使得熵H(p)最大。即:
![]()
![]() 其中C的含义是所有满足约束的模型集合,n为特征或者说特征函数fi的数量(注意跟样本数量N区别)。
其中C的含义是所有满足约束的模型集合,n为特征或者说特征函数fi的数量(注意跟样本数量N区别)。
指数形式
最大熵要解决的是约束优化问题:find the p*∈C which maximizes H(p)。对于上述翻译的例子,如果只施加了前面两个约束,很容易直接求得p的分布。但是,绝大多数情况下最大熵模模型的解无法直接给出,我们需要引入像拉格朗日乘子(Lagrange Multiplier)这样的方法。
我们具体要优化的问题是: 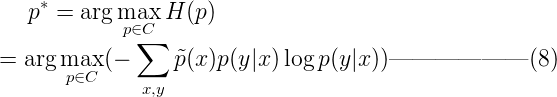 相应的约束为:
相应的约束为: 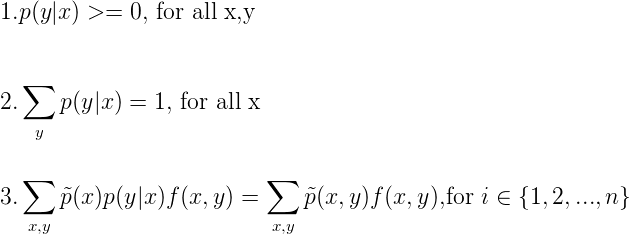 为解决这个优化问题,为每一个fi引入参数λi ,得到拉格朗日函数ζ(p, Λ, γ)如下:
为解决这个优化问题,为每一个fi引入参数λi ,得到拉格朗日函数ζ(p, Λ, γ)如下: 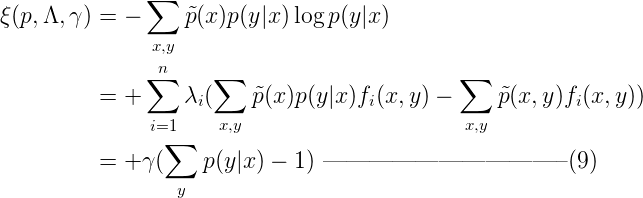 其中实值参数Λ = {λ1, λ2, …, λn}和γ对应着约束2和3的n+1个限制。保持Λ和γ不变,计算拉格朗日函数ζ(p, Λ, γ)在不受限的情况下的最大值,即可得到p(y|x)的最优解。因此对ζ(p, Λ, γ)在p(y|x)上求导得(注意为了方便计算,我们这里对数以自然对数e为底):
其中实值参数Λ = {λ1, λ2, …, λn}和γ对应着约束2和3的n+1个限制。保持Λ和γ不变,计算拉格朗日函数ζ(p, Λ, γ)在不受限的情况下的最大值,即可得到p(y|x)的最优解。因此对ζ(p, Λ, γ)在p(y|x)上求导得(注意为了方便计算,我们这里对数以自然对数e为底):  令上式(10)等于0,即:
令上式(10)等于0,即: 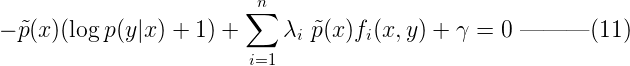 解上面的单变量方程(把p(y|x)当未知数),可得p(y|x) :
解上面的单变量方程(把p(y|x)当未知数),可得p(y|x) : 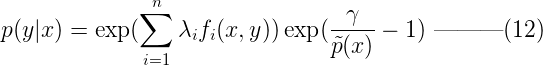 根据约束2,对于任意x, Σyp(y|x) = 1,我们对等式(12)两边分别求和,可以得到:
根据约束2,对于任意x, Σyp(y|x) = 1,我们对等式(12)两边分别求和,可以得到: 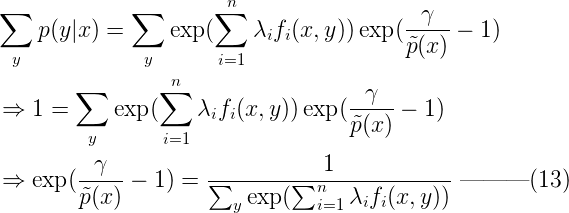 将等式(13)代入等式(12),可以得到:
将等式(13)代入等式(12),可以得到: 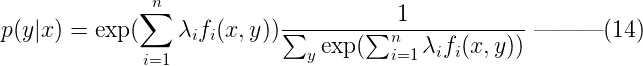 令Z(x) 为:
令Z(x) 为: 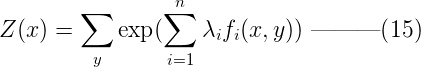 则模型p(y|x)的最优解为,其中Z(x)称为归一化因子:
则模型p(y|x)的最优解为,其中Z(x)称为归一化因子: 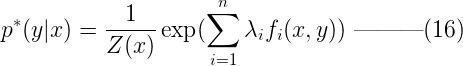 到这里,我们可以看到,满足约束C的最大熵模型具有(16)的参数化形式。由于拉格朗日函数ζ(p, Λ, γ)中的p(y|x)和γ都可以表示成Λ,所以接下来的问题就转化成了求解参数Λ = {λ1, λ2, …, λn}。为此,我们定义对偶函数ψ( Λ ) 及其优化问题:
到这里,我们可以看到,满足约束C的最大熵模型具有(16)的参数化形式。由于拉格朗日函数ζ(p, Λ, γ)中的p(y|x)和γ都可以表示成Λ,所以接下来的问题就转化成了求解参数Λ = {λ1, λ2, …, λn}。为此,我们定义对偶函数ψ( Λ ) 及其优化问题: 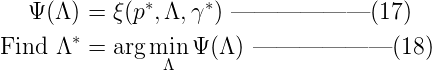 根据所谓的Kuhn-Tucker theorem(KTT)原理(这个目前还没研究,暂不展开),我们有如下结论:公式(16)中模型p*(y|x)中的参数Λ,可以通过最小化对偶函数ψ( Λ ) 求解,如(17)(18)所示。 计算参数 求解Λ = {λ1, λ2, …, λn},解析的方法是行不通的。这种最大熵模型对应的最优化问题,一般有GIS/IIS,IIS是GIS的优化版。这里讨论最简单的GIS。GIS的一般步骤是:
根据所谓的Kuhn-Tucker theorem(KTT)原理(这个目前还没研究,暂不展开),我们有如下结论:公式(16)中模型p*(y|x)中的参数Λ,可以通过最小化对偶函数ψ( Λ ) 求解,如(17)(18)所示。 计算参数 求解Λ = {λ1, λ2, …, λn},解析的方法是行不通的。这种最大熵模型对应的最优化问题,一般有GIS/IIS,IIS是GIS的优化版。这里讨论最简单的GIS。GIS的一般步骤是:
1. 初始化所有λi 为任意值,一般可以设置为0,即: ![]() 其中λ的上标(t)表示第t论迭代,下标i表示第i个特征,n是特征总数。 2. 重复下面的权值更新直至收敛:
其中λ的上标(t)表示第t论迭代,下标i表示第i个特征,n是特征总数。 2. 重复下面的权值更新直至收敛: 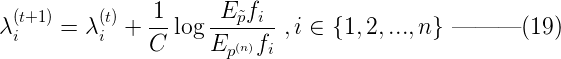 收敛的判断依据可以是λi 前后两次的差价足够小。其中C一般取所有样本数据中最大的特征数量,Ep~和Ep如下:
收敛的判断依据可以是λi 前后两次的差价足够小。其中C一般取所有样本数据中最大的特征数量,Ep~和Ep如下: 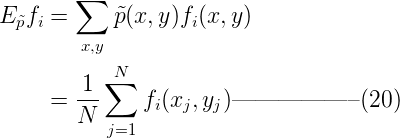

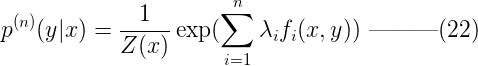 代码实现见:揭开机器学习的面纱:最大熵模型100行代码实现[Python版]
代码实现见:揭开机器学习的面纱:最大熵模型100行代码实现[Python版]