这篇文章包括一些有用的Pandas技巧,这些技巧有助于在大型数据集上使用Pandas进行有效的预处理和特征工程。
Pandas ufuncs (Universal functions)以及为什么它们比apply命令好得多
Pandas 有一个apply函数,您几乎可以将任何函数应用(apply)于列中的所有值。注意apply只是比python for循环快一点!这就是为什么推荐使用Pandas内置的 ucfuns 在列上应用预处理任务。ucfuns,是用C语言实现的一些特定功能(基于numpy库),因此非常高效。我们将提到的有用的功能包括:.diff,.shift,.cumsum,.cumcount,.str命令(用于字符串),.dt命令(用于日期) ,等等。
数据集示例-暑期活动
我将在如下图说是的数据集上演示 Pandas 技巧。暑期活动数据集说明:一个人可以在不同的时间戳下进行多项活动。
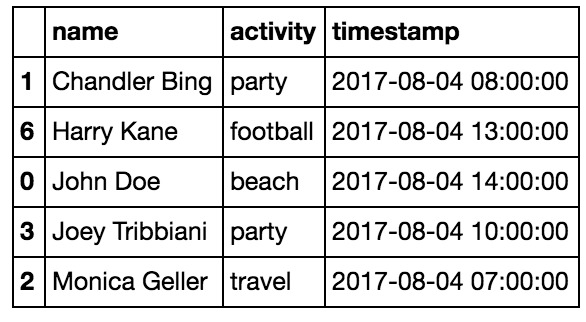
假设我们的目标是根据给定的数据集预测谁是数据集中最有趣的人:)。

1.字符串命令
对于字符串操作,最推荐使用Pandas string 命令(属于ufuncs)。
例如,您可以使用以下方式将包含一个人的全名的列分为两列:.str.split, 参数expand = True。
df[‘name’] = df.name.str.split(" ", expand=True)
另外,您可以使用.str.replace和一个合适的正则表达式有效地清理任何字符串列。
2. group by和value_counts
group by是一个非常强大的 Pandas 方法。您可以使用以下方式对一列进行分组,并使用value_counts根据该列值计算另一列的值。使用group by和value_counts我们可以计算每个人进行的活动数量。
df.groupby('name')['activity'].value_counts()
这就是多索引情况,它是pandas DataFrame中的一个有价值的技巧,它使我们在DataFrame中具有几个级别的索引层次结构。在这种情况下,人员名称是索引的级别0,而活动是级别1。
3.Unstack
通过在上面的代码中应用unstack,我们还可以为每个人的夏季活动计数。unstack将行切换为列,以将活动计数作为特征值。通过做unstack将索引的最后一级转换为列。现在,所有活动值将成为DataFrame的列。其中当某人未执行某项活动时,此特征值为Nan。Fillna函数用0填充所有这些缺失值(人员未进行的活动)。
df.groupby('name')['activity'].value_counts().unstack().fillna(0)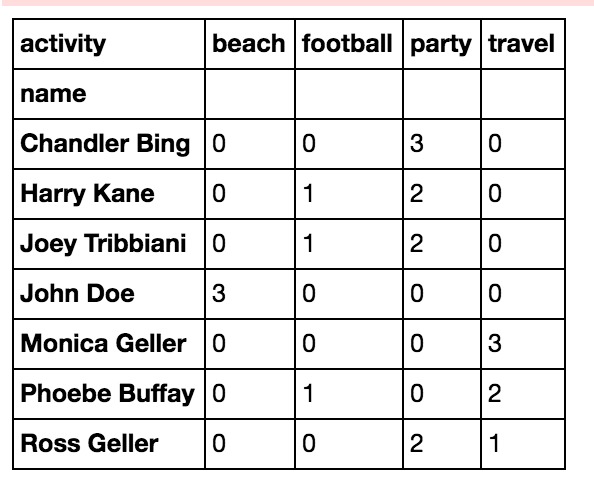
3. groupby,diff,shift和loc +高效技巧
了解人的活动之间的时差对于预测谁是最有趣的人可能会很有用。一个人参加聚会多久了?他/她在海滩闲逛了多长时间?这可能对我们有用。
计算时间差的最直接方法是group by人员名称,然后使用diff()命令计算时间戳字段上的差异:
df = df.sort_values(by=['name','timestamp'])
df['time_diff'] = df.groupby('name')['timestamp'].diff()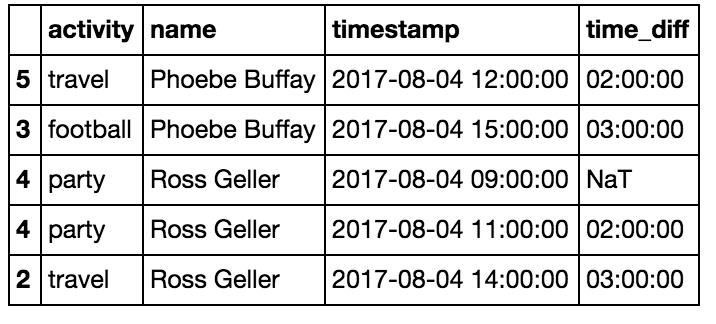
如果您有大量数据,并且想节省一些时间(根据数据大小的不同,速度可能会快10倍左右),则可以跳过groupby,在对数据进行排序之后做diff,然后删除每个不相关的人的第一行。
df = df.sort_values(by=['name','timestamp'])
df['time_diff'] = df['timestamp'].diff()
df.loc[df.name != df.name.shift(), 'time_diff'] = None其中.shift命令将所有列向下移动一格,因此我们可以通过执行以下操作查看此列在哪一行上更改:
df.name!= df.name.shift()。
其中.loc是为特定索引设置列的值。
要将time_diff更改为以秒为单位:
df['time_diff'] = df.time_diff.dt.total_seconds()要获得每行的持续时间:
df[‘row_duration’] = df.time_diff.shift(-1)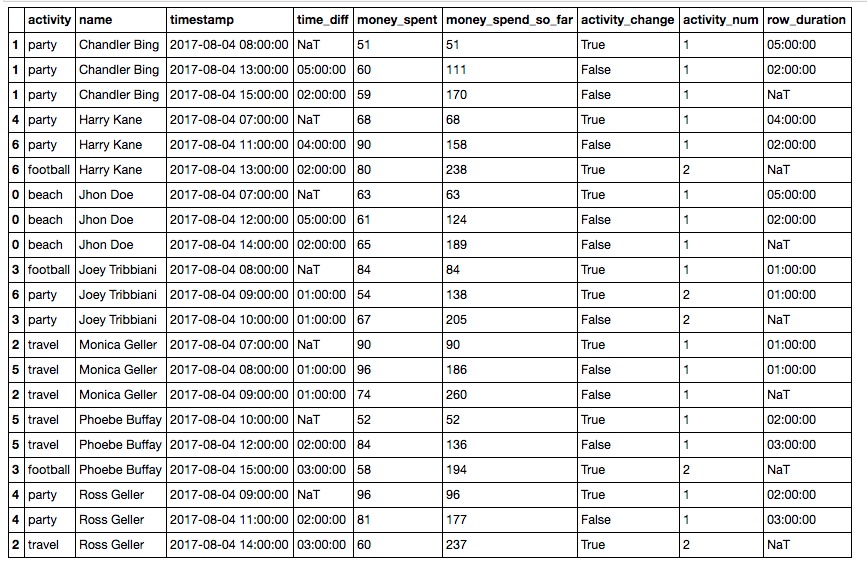
4.Cumcount and Cumsum
这是两个非常酷的Ufunc,可以为您提供许多帮助。 Cumcount创建一个累积计数。例如,我们可以通过按人员名称分组然后对每个人员的第二项活动应用cumcount。这将仅按活动顺序对活动进行计数。然后我们可以对每个人的第二项活动仅仅进行== 1(或通过== 2)操作即可将索引应用于原始排序的DataFrame上。
df = df.sort_values(by=['name','timestamp'])df2 = df[df.groupby(‘name’).cumcount()==1]

df = df.sort_values(by=[‘name’,’timestamp’])df2 = df[df.groupby(‘name’).cumcount()==2]

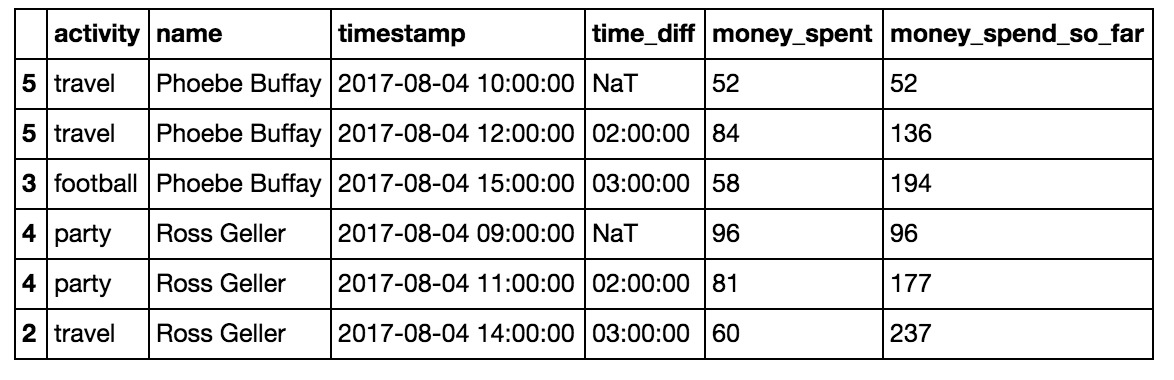
Cumsum只是数字单元格的累积汇总。例如,您可以将人员在每个活动中花费的钱添加为一个附加单元格,然后使用以下方法汇总人员在一天中的每个时间所花费的钱:
df = df.sort_values(by=[‘name’,’timestamp’])df['money_spent_so_far'] = df.groupby(‘name’)['money_spent'].cumsum()
5. groupby,max,min用于测量活动的持续时间
在第3节中,我们想知道每个人在每个活动中花费了多少时间。但是我们忽略了有时我们会得到多个关于活动的记录,实际上是同一活动的继续。因此,要获得实际的活动持续时间,我们应该测量连续活动从第一次出现到最后一次的时间。为此,我们需要标记活动的更改,并用活动编号标记每一行。我们将使用.shift命令和.cumsum。新的活动是在活动发生变化时或者人名变了。
df['activity_change'] = (df.activity!=df.activity.shift()) | (df.name!=df.name.shift())然后,我们将通过按用户分组并应用强大的.cumsum来计算每行的活动编号。:
df['activity_num'] = df.groupby('name')['activity_change'].cumsum()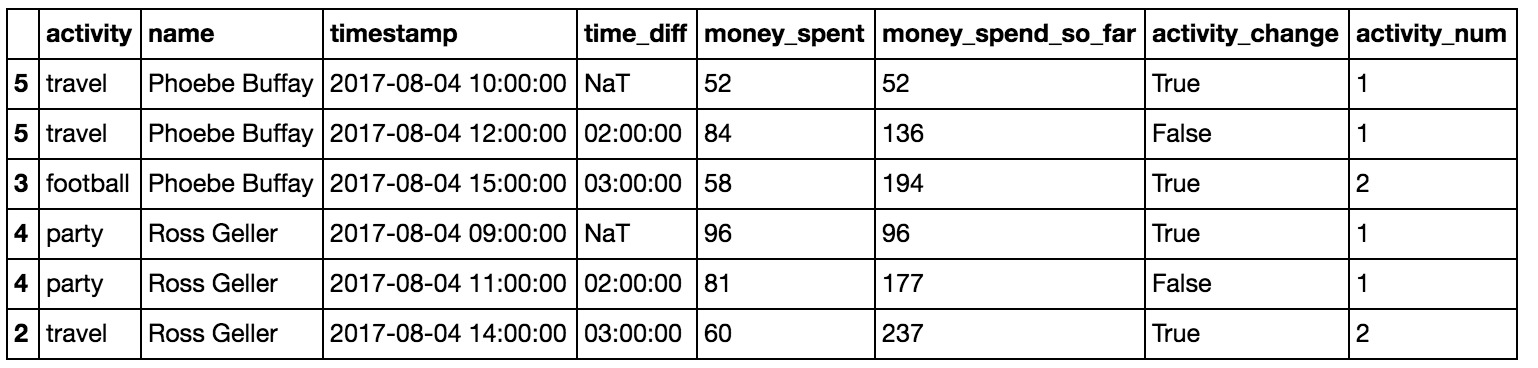
现在,我们可以按照每个名称和活动编号进行分组,并计算每行活动持续时间的总和,如下:
activity_duration = df.groupby(['name','activity_num','activity'])['activity_duration'].sum()
这将以某种timedelta类型返回活动持续时间。您可以使用.dt.total_seconds以秒为单位获取会话活动持续时间:
activity_duration = activity_duration.dt.total_seconds()然后,您可以使用以下命令来确定每个人的最大/最小活动持续时间(或中位数或均值):
activity_duration = activity_duration.reset_index().groupby('name').max()
总结
这是使用夏季活动数据集的 Pandas 之旅。希望您已经学会,祝您下一个 Pandas 项目好运!