Swifter
Swfiter是一个库,它“以最快的可用方式将任何函数应用到 Pandas DataFrame(数据框)或Series(序列)。”。想要了解Swifter是怎么做到的,我们首先需要了解一下向量化和并行处理的概念。
向量化
对于此用例,我们将向量化定义为使用Numpy表示整个数组上的计算而不是单个元素上的计算。
例如,假设您有两个数组:
array_1 = np.array([1,2,3,4,5])
array_2 = np.array([6,7,8,9,10])您希望创建一个新数组,该数组是两个数按项求和,结果是:
result = [7,9,11,13,15]您可以使用Python中的for循环对这些数组求和,但这非常慢。取而代之的是,Numpy允许您直接在阵列上进行操作,这要快得多(尤其是大型阵列)
result = array_1 + array_2加速pandas DataFrame的关键要点之一就是尽可能使用向量化操作。
并行处理
当前几乎所有计算机都具有多个处理器。这意味着您可以通过充分利用这些处理器来轻松地加快代码的处理速度。由于apply函数通常是将某个函数应用于DataFrame的每一行,因此很容易并行化。我们可以将DataFrame分成多个块,然后将每个块分别送到对应的某个处理器,最后将这些块组合回单个DataFrame。
Swifter的作用
- 检查您的函数是否可以向量化,如果可以,则使用向量化计算。
- 如果无法进行向量化,则使用Dask并行化处理,每个并行分组中仍然是普通的DataFrame apply(仅使用单个内核按行处理)。需要主要的问题是:并行处理的额外开销会使小型数据集的处理速度变慢。
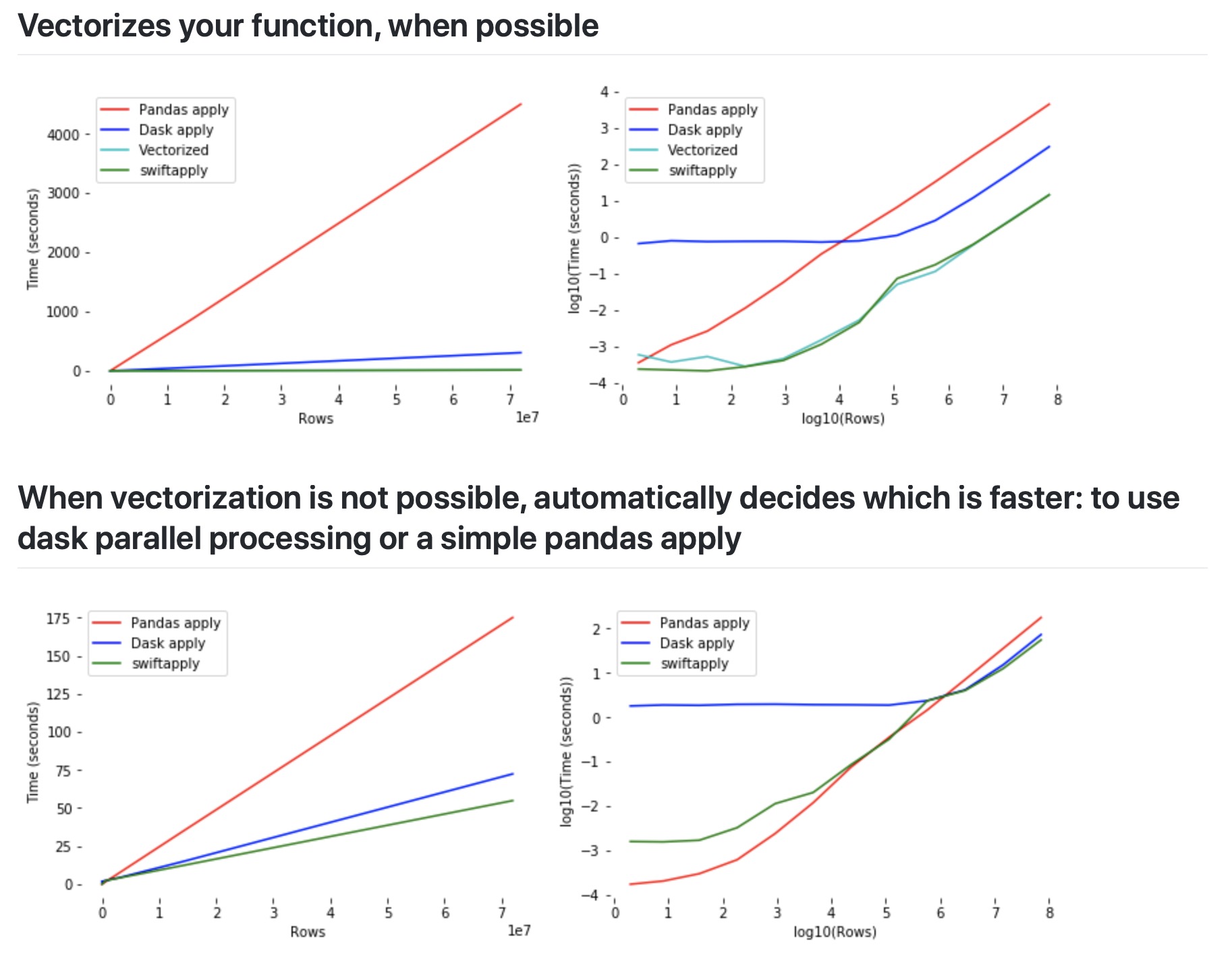
DataFrame不同处理处理方式性能对比图如下

上图可以很明确地看大Swifter的个特点,即,无论数据大小如何,使用向量化效果几乎总是更好;如果数据量较小,那么普通 Pandas 操作有最佳速度,直到数据足够大为止;一旦超过阈值,并行处理就会是处理更快。
那么如何使用swifter呢?非常简单,如下代码所示!您会看到在“swift apply”行,swifter会自动为您选择最佳选项。
import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())
如上面代码所示,只需在apply之前添加swifter调用,即增加一个单词/一行代码就可以更快地运行Pandas DataFrame。
Swifter安装
swifter用pip直接安装即可,很方便。
$ pip install -U pandas # upgrade pandas
$ pip install swifter # first time installation
$ pip install -U swifter # upgrade to latest version if already installed
当然,也可以用Anaconda安装:
conda install -c conda-forge swifter
一个完整Swifter代码示例
import pandas as pd
import swifter
df = pd.DataFrame({'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
df['outCol'] = df[['inCol1', 'inCol2']].swifter.apply(my_func)
df['outCol'] = df[['inCol1', 'inCol2', 'inCol3']].swifter.apply(my_func,
positional_arg, keyword_arg=keyword_argval)
更多性能对比图