Swifter
Swfiter是一個庫,它“以最快的可用方式將任何函數應用到 Pandas DataFrame(數據框)或Series(序列)。”。想要了解Swifter是怎麽做到的,我們首先需要了解一下向量化和並行處理的概念。
向量化
對於此用例,我們將向量化定義為使用Numpy表示整個數組上的計算而不是單個元素上的計算。
例如,假設您有兩個數組:
array_1 = np.array([1,2,3,4,5])
array_2 = np.array([6,7,8,9,10])您希望創建一個新數組,該數組是兩個數按項求和,結果是:
result = [7,9,11,13,15]您可以使用Python中的for循環對這些數組求和,但這非常慢。取而代之的是,Numpy允許您直接在陣列上進行操作,這要快得多(尤其是大型陣列)
result = array_1 + array_2加速pandas DataFrame的關鍵要點之一就是盡可能使用向量化操作。
並行處理
當前幾乎所有計算機都具有多個處理器。這意味著您可以通過充分利用這些處理器來輕鬆地加快代碼的處理速度。由於apply函數通常是將某個函數應用於DataFrame的每一行,因此很容易並行化。我們可以將DataFrame分成多個塊,然後將每個塊分別送到對應的某個處理器,最後將這些塊組合回單個DataFrame。
Swifter的作用
- 檢查您的函數是否可以向量化,如果可以,則使用向量化計算。
- 如果無法進行向量化,則使用Dask並行化處理,每個並行分組中仍然是普通的DataFrame apply(僅使用單個內核按行處理)。需要主要的問題是:並行處理的額外開銷會使小型數據集的處理速度變慢。
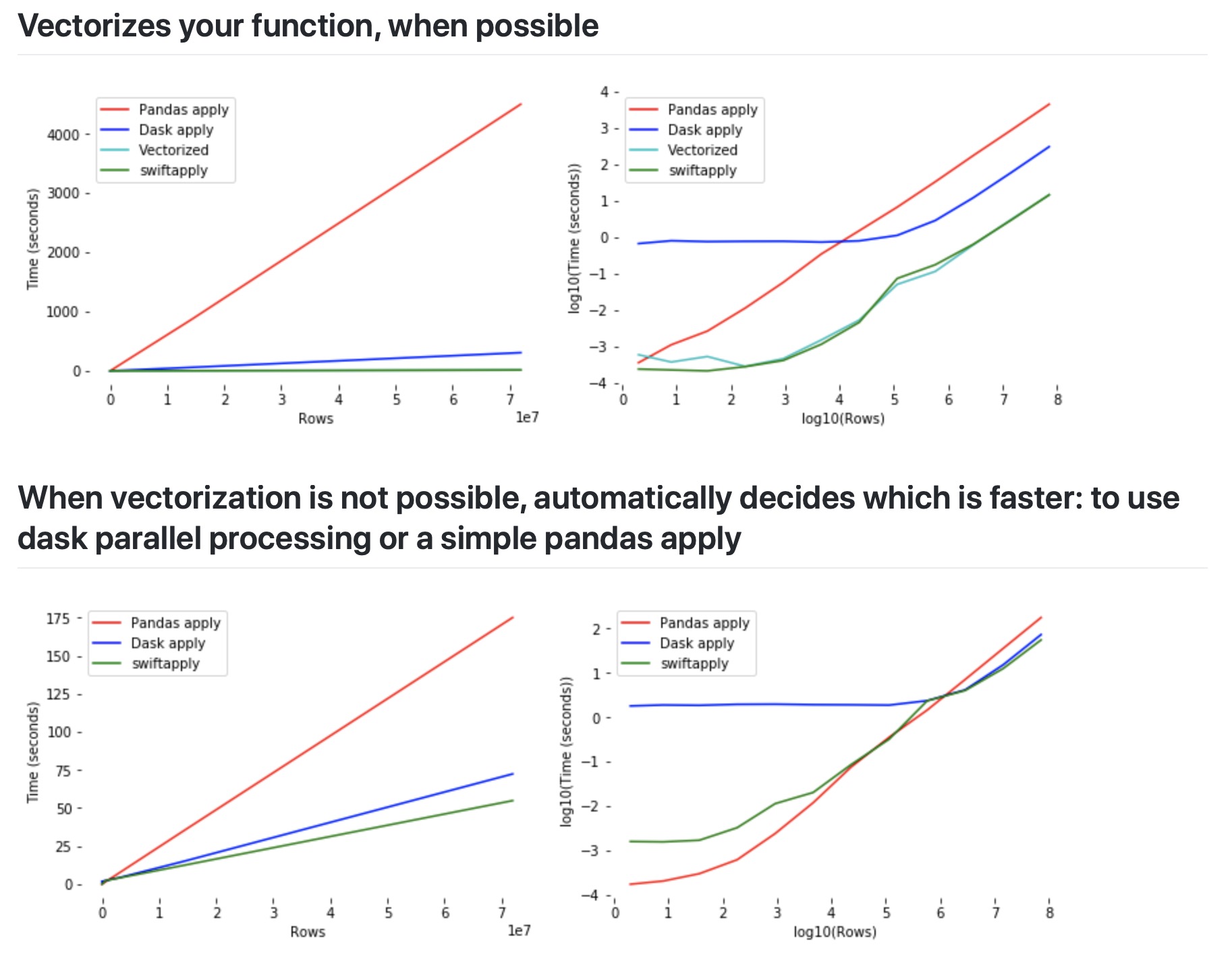
DataFrame不同處理處理方式性能對比圖如下

上圖可以很明確地看大Swifter的個特點,即,無論數據大小如何,使用向量化效果幾乎總是更好;如果數據量較小,那麽普通 Pandas 操作有最佳速度,直到數據足夠大為止;一旦超過閾值,並行處理就會是處理更快。
那麽如何使用swifter呢?非常簡單,如下代碼所示!您會看到在“swift apply”行,swifter會自動為您選擇最佳選項。
import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())
如上麵代碼所示,隻需在apply之前添加swifter調用,即增加一個單詞/一行代碼就可以更快地運行Pandas DataFrame。
Swifter安裝
swifter用pip直接安裝即可,很方便。
$ pip install -U pandas # upgrade pandas
$ pip install swifter # first time installation
$ pip install -U swifter # upgrade to latest version if already installed
當然,也可以用Anaconda安裝:
conda install -c conda-forge swifter
一個完整Swifter代碼示例
import pandas as pd
import swifter
df = pd.DataFrame({'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
df['outCol'] = df[['inCol1', 'inCol2']].swifter.apply(my_func)
df['outCol'] = df[['inCol1', 'inCol2', 'inCol3']].swifter.apply(my_func,
positional_arg, keyword_arg=keyword_argval)
更多性能對比圖