Pandas中有map,還有applymap和apply方法/函數,它們之間有什麽區別?
簡單示例比較
我們知道map是Series方法,另外2個是的是DataFrame方法。容易讓人困惑的是apply和applymap方法——為什麽我們有兩種方法將函數應用於DataFrame?
我們看看來自韋斯·麥金尼(Wes McKinney)的Python for Data Analysis書的解釋,第132頁。(強烈推薦這本書):
Another frequent operation is applying a function on 1D arrays to each column or row. DataFrame’s apply method does exactly this:
譯文:另一常見操作是將一維數組上的函數應用於每一列或每一行。 DataFrame的apply方法正是這樣做的:
In [116]: frame = DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon'])
In [117]: frame
Out[117]:
b d e
Utah -0.029638 1.081563 1.280300
Ohio 0.647747 0.831136 -1.549481
Texas 0.513416 -0.884417 0.195343
Oregon -0.485454 -0.477388 -0.309548
In [118]: f = lambda x: x.max() - x.min()
In [119]: frame.apply(f)
Out[119]:
b 1.133201
d 1.965980
e 2.829781
dtype: float64
Many of the most common array statistics (like sum and mean) are DataFrame methods, so using apply is not necessary.
Element-wise Python functions can be used, too. Suppose you wanted to compute a formatted string from each floating point value in frame. You can do this with applymap:
譯文:許多最常見的數組統計信息(例如sum和mean)用DataFrame內置方法就可以實現, 當然也可以使用基於元素的Python函數,所以做這些計算的話apply並不是必須的。假設您要根據DataFrame中的每個浮點值來計算格式化的字符串,您可以使用applymap做到這一點:
In [120]: format = lambda x: '%.2f' % x
In [121]: frame.applymap(format)
Out[121]:
b d e
Utah -0.03 1.08 1.28
Ohio 0.65 0.83 -1.55
Texas 0.51 -0.88 0.20
Oregon -0.49 -0.48 -0.31
The reason for the name applymap is that Series has a map method for applying an element-wise function:
譯文:之所以使用applymap作為名稱,是因為Series具有用於應用逐元素函數的map方法:
In [122]: frame['e'].map(format)
Out[122]:
Utah 1.28
Ohio -1.55
Texas 0.20
Oregon -0.31
Name: e, dtype: object
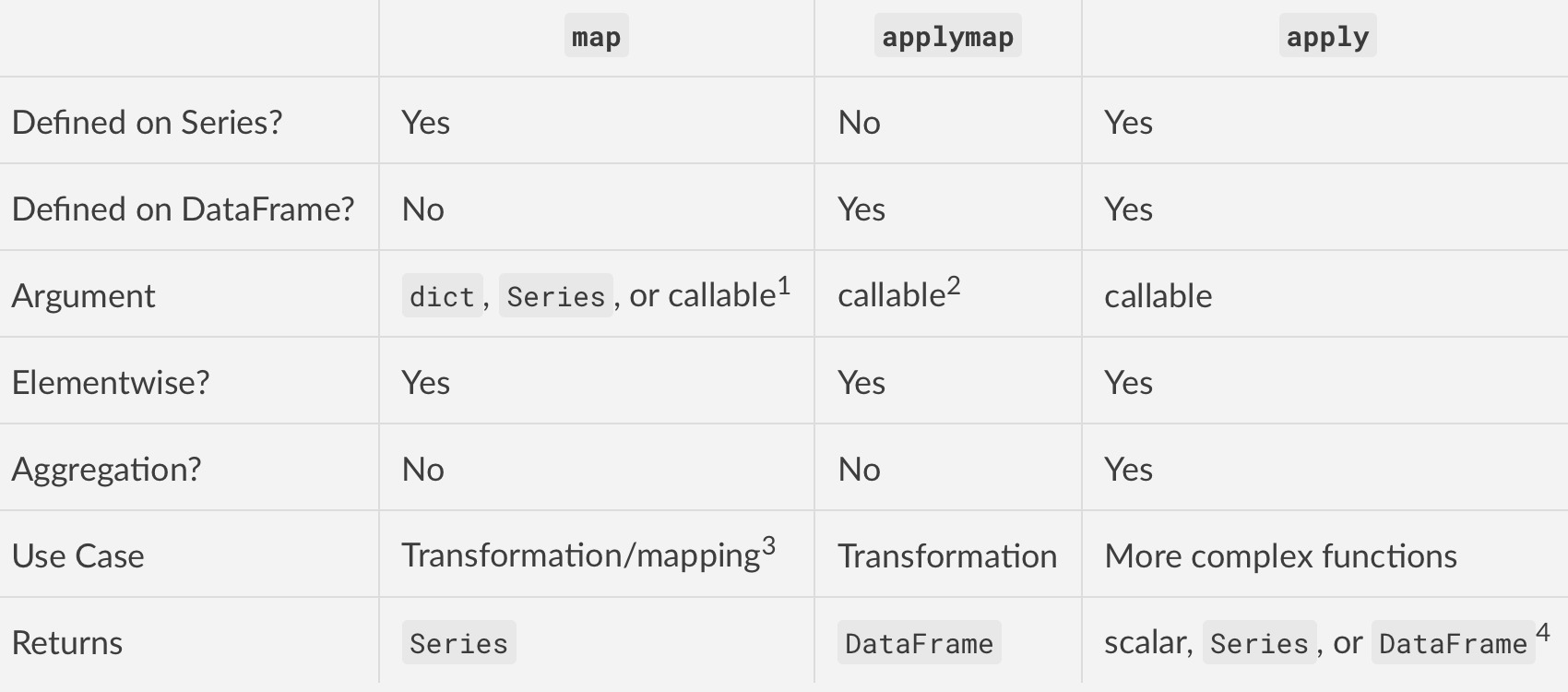
總結起來,apply在DataFrame的行/列上執行,applymap在DataFrame的元素上執行,map在係列數據(Series)上按元素執行。
全麵的差異對比
map,applymap和apply的比較:上下文相關
第一個主要區別:定義
map僅在Series(係列)上定義applymap僅在DataFrame上定義apply在Series和DataFrame兩者上均有定義
第二個主要區別:輸入參數
map接受dict,Series或可調用的函數對象applymap和apply僅接受可調用函數對象
第三大區別:行為
map是對Series按元素操作的applymap是對DataFrames按元素操作的apply也可以逐元素運行,但適用於更複雜的操作和聚合。行為和返回值取決於函數。
第四大區別(最重要的區別):用例
map用於將值從一個域映射到另一個域,因此針對性能進行了優化(例如df['A'].map({1:'a', 2:'b', 3:'c'}))applymap適用於跨多個行/列的元素轉換(例如df[['A', 'B', 'C']].applymap(str.strip))apply用於應用無法向量化的任何功能(例如df['sentences'].apply(nltk.sent_tokenize))
小結
Footnotes(腳注)
- 傳入字典/係列參數時,map將基於該字典/係列中的鍵來映射元素。缺少的值將在輸出中記錄為NaN。
- 最新版本中的applymap已針對某些操作進行了優化。在某些情況下,您會發現applymap的速度比apply速度稍快。我的建議是對它們都進行測試,並使用更好的方法。
- map針對元素映射和轉換進行了優化。涉及字典或係列的操作將使Panda是能夠使用更快的代碼路徑來獲得更好的性能。
- Series.apply返回用於聚合操作的標量,或者返回Series。對於DataFrame.apply來說也一樣。請注意,當通過某些NumPy函數(例如均值,總和等)調用apply時,apply也具有快速路徑。
補充的知識點
Series.apply和Series.map的功能之間有很多重疊之處,這意味著在大多數情況下任何一種都可以使用。但是,它們確實有一些細微的差異,參考下麵的對比示例,map隻會將一個係列放在另一個係列的每個單元格中,這可能不是您想要的。
In [40]: p=pd.Series([1,2,3])
In [41]: p
Out[31]:
0 1
1 2
2 3
dtype: int64
In [42]: p.apply(lambda x: pd.Series([x, x]))
Out[42]:
0 1
0 1 1
1 2 2
2 3 3
In [43]: p.map(lambda x: pd.Series([x, x]))
Out[43]:
0 0 1
1 1
dtype: int64
1 0 2
1 2
dtype: int64
2 0 3
1 3
dtype: int64
dtype: object
另外,如果我有一個帶有副作用的函數,例如“連接到Web服務器”,則可能為了清楚起見,我可能會使用apply。
series.apply(download_file_for_every_element)
參考資料