這篇文章包括一些有用的Pandas技巧,這些技巧有助於在大型數據集上使用Pandas進行有效的預處理和特征工程。
Pandas ufuncs (Universal functions)以及為什麽它們比apply命令好得多
Pandas 有一個apply函數,您幾乎可以將任何函數應用(apply)於列中的所有值。注意apply隻是比python for循環快一點!這就是為什麽推薦使用Pandas內置的 ucfuns 在列上應用預處理任務。ucfuns,是用C語言實現的一些特定功能(基於numpy庫),因此非常高效。我們將提到的有用的功能包括:.diff,.shift,.cumsum,.cumcount,.str命令(用於字符串),.dt命令(用於日期) ,等等。
數據集示例-暑期活動
我將在如下圖說是的數據集上演示 Pandas 技巧。暑期活動數據集說明:一個人可以在不同的時間戳下進行多項活動。
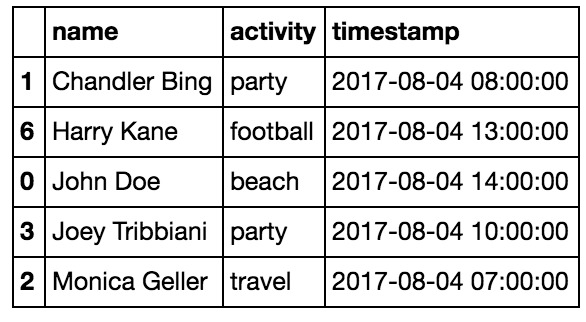
假設我們的目標是根據給定的數據集預測誰是數據集中最有趣的人:)。

1.字符串命令
對於字符串操作,最推薦使用Pandas string 命令(屬於ufuncs)。
例如,您可以使用以下方式將包含一個人的全名的列分為兩列:.str.split, 參數expand = True。
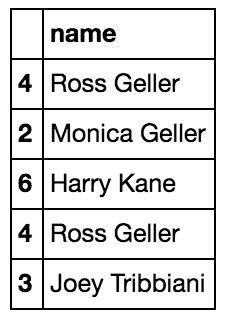
df[‘name’] = df.name.str.split(" ", expand=True)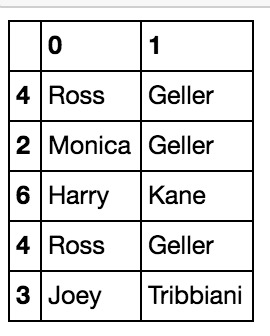
另外,您可以使用.str.replace和一個合適的正則表達式有效地清理任何字符串列。
2. group by和value_counts
group by是一個非常強大的 Pandas 方法。您可以使用以下方式對一列進行分組,並使用value_counts根據該列值計算另一列的值。使用group by和value_counts我們可以計算每個人進行的活動數量。
df.groupby('name')['activity'].value_counts()
這就是多索引情況,它是pandas DataFrame中的一個有價值的技巧,它使我們在DataFrame中具有幾個級別的索引層次結構。在這種情況下,人員名稱是索引的級別0,而活動是級別1。
3.Unstack
通過在上麵的代碼中應用unstack,我們還可以為每個人的夏季活動計數。unstack將行切換為列,以將活動計數作為特征值。通過做unstack將索引的最後一級轉換為列。現在,所有活動值將成為DataFrame的列。其中當某人未執行某項活動時,此特征值為Nan。Fillna函數用0填充所有這些缺失值(人員未進行的活動)。
df.groupby('name')['activity'].value_counts().unstack().fillna(0)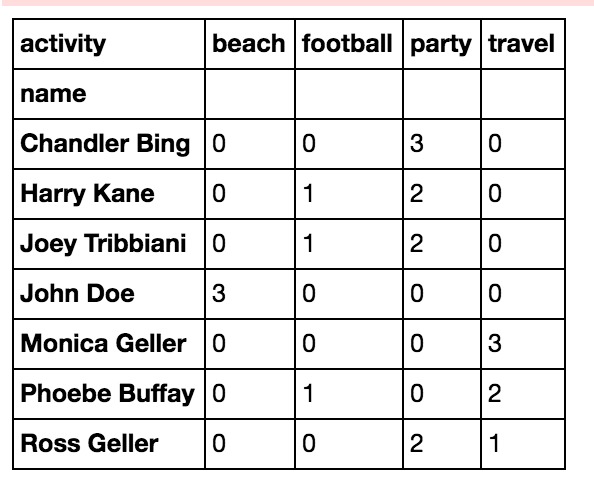
3. groupby,diff,shift和loc +高效技巧
了解人的活動之間的時差對於預測誰是最有趣的人可能會很有用。一個人參加聚會多久了?他/她在海灘閑逛了多長時間?這可能對我們有用。
計算時間差的最直接方法是group by人員名稱,然後使用diff()命令計算時間戳字段上的差異:
df = df.sort_values(by=['name','timestamp'])
df['time_diff'] = df.groupby('name')['timestamp'].diff()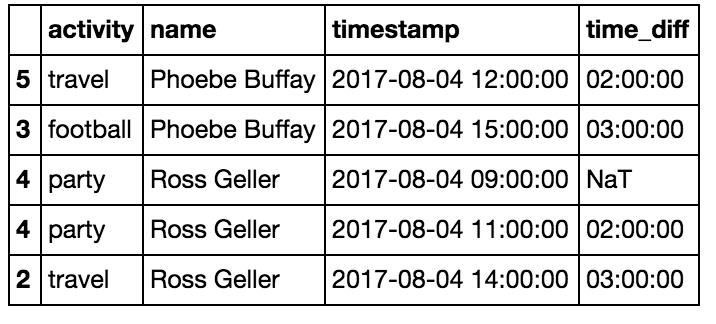
如果您有大量數據,並且想節省一些時間(根據數據大小的不同,速度可能會快10倍左右),則可以跳過groupby,在對數據進行排序之後做diff,然後刪除每個不相關的人的第一行。
df = df.sort_values(by=['name','timestamp'])
df['time_diff'] = df['timestamp'].diff()
df.loc[df.name != df.name.shift(), 'time_diff'] = None其中.shift命令將所有列向下移動一格,因此我們可以通過執行以下操作查看此列在哪一行上更改:
df.name!= df.name.shift()。
其中.loc是為特定索引設置列的值。
要將time_diff更改為以秒為單位:
df['time_diff'] = df.time_diff.dt.total_seconds()要獲得每行的持續時間:
df[‘row_duration’] = df.time_diff.shift(-1)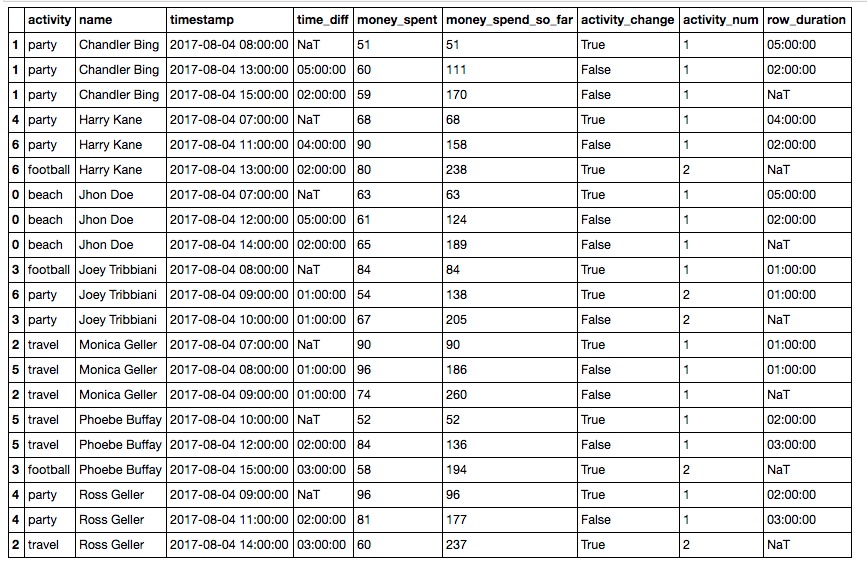
4.Cumcount and Cumsum
這是兩個非常酷的Ufunc,可以為您提供許多幫助。 Cumcount創建一個累積計數。例如,我們可以通過按人員名稱分組然後對每個人員的第二項活動應用cumcount。這將僅按活動順序對活動進行計數。然後我們可以對每個人的第二項活動僅僅進行== 1(或通過== 2)操作即可將索引應用於原始排序的DataFrame上。
df = df.sort_values(by=['name','timestamp'])df2 = df[df.groupby(‘name’).cumcount()==1]

df = df.sort_values(by=[‘name’,’timestamp’])df2 = df[df.groupby(‘name’).cumcount()==2]

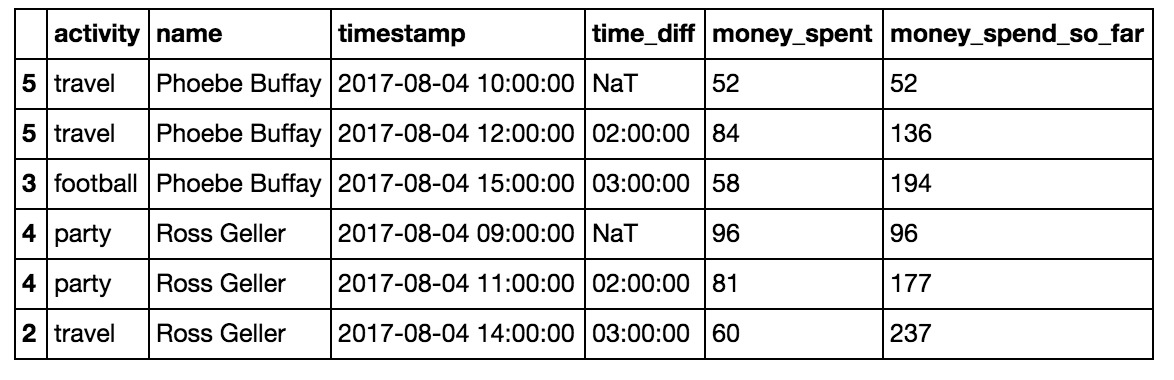
Cumsum隻是數字單元格的累積匯總。例如,您可以將人員在每個活動中花費的錢添加為一個附加單元格,然後使用以下方法匯總人員在一天中的每個時間所花費的錢:
df = df.sort_values(by=[‘name’,’timestamp’])df['money_spent_so_far'] = df.groupby(‘name’)['money_spent'].cumsum()
5. groupby,max,min用於測量活動的持續時間
在第3節中,我們想知道每個人在每個活動中花費了多少時間。但是我們忽略了有時我們會得到多個關於活動的記錄,實際上是同一活動的繼續。因此,要獲得實際的活動持續時間,我們應該測量連續活動從第一次出現到最後一次的時間。為此,我們需要標記活動的更改,並用活動編號標記每一行。我們將使用.shift命令和.cumsum。新的活動是在活動發生變化時或者人名變了。
df['activity_change'] = (df.activity!=df.activity.shift()) | (df.name!=df.name.shift())然後,我們將通過按用戶分組並應用強大的.cumsum來計算每行的活動編號。:
df['activity_num'] = df.groupby('name')['activity_change'].cumsum()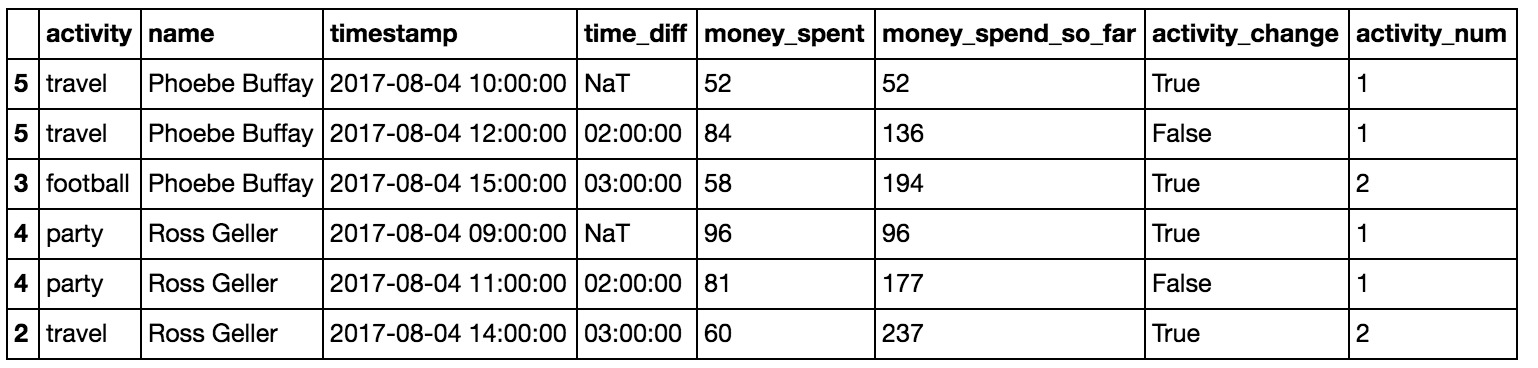
現在,我們可以按照每個名稱和活動編號進行分組,並計算每行活動持續時間的總和,如下:
activity_duration = df.groupby(['name','activity_num','activity'])['activity_duration'].sum()
這將以某種timedelta類型返回活動持續時間。您可以使用.dt.total_seconds以秒為單位獲取會話活動持續時間:
activity_duration = activity_duration.dt.total_seconds()然後,您可以使用以下命令來確定每個人的最大/最小活動持續時間(或中位數或均值):
activity_duration = activity_duration.reset_index().groupby('name').max()
總結
這是使用夏季活動數據集的 Pandas 之旅。希望您已經學會,祝您下一個 Pandas 項目好運!