本文簡要介紹 python 語言中 scipy.stats.sampling.DiscreteAliasUrn 的用法。
用法:
class scipy.stats.sampling.DiscreteAliasUrn(dist, *, domain=None, urn_factor=1, random_state=None)#離散Alias-Urn 方法。
該方法用於從具有有限域的單變量離散分布中采樣。它使用大小為 的概率向量或具有有限支持的概率質量函數從分布中生成隨機數。
- dist: 數組 或對象,可選
分布的概率向量 (PV)。如果 PV 不可用,則需要一個具有
pmf方法的類的實例。 PMF 的簽名預計為:def pmf(self, k: int) -> float。即它應該接受一個 Python 整數並返回一個 Python 浮點數。- domain: 整數,可選
支持 PMF。如果概率向量 (
pv) 不可用,則必須給出有限域。即 PMF 必須有一個有限的支持。默認為None。當None:如果一個
support方法由分發對象提供距離,用於設置分布的域。否則,假定支持為
(0, len(pv))。當此參數與概率向量一起傳遞時,domain[0]用於將分布從(0, len(pv))重新定位到(domain[0], domain[0]+len(pv)),而domain[1]將被忽略。有關更詳細的說明,請參閱注釋和教程。
- urn_factor: 浮點數,可選
甕表的大小相對於概率向量的大小。它不能小於 1。更大的表會導致更快的生成時間,但需要更昂貴的設置。默認值為 1。
- random_state: {無,整數,
numpy.random.Generator, numpy.random.RandomState}, optionalNumPy 隨機數生成器或底層NumPy 隨機數生成器的種子,用於生成統一隨機數流。如果random_state是無(或np.random), 這
numpy.random.RandomState使用單例。如果random_state是一個 int,一個新的RandomState使用實例,播種random_state.如果random_state已經是一個Generator或者RandomState實例然後使用該實例。
參數 ::
注意:
當有限概率向量可用或分布的 PMF 可用時,此方法有效。如果隻有 PMF 可用,則還必須給出 PMF 的有限支持(域)。建議首先通過評估支持中每個點的 PMF 來獲得概率向量,然後再使用它。
如果給定一個概率向量,它必須是一個非負浮點數的一維數組,沒有任何
inf或nan值。此外,必須至少有一個非零條目,否則會引發異常。默認情況下,概率向量從 0 開始索引。但是,這可以通過傳遞
domain參數來更改。當domain與 PV 一起給出時,它具有將分布從(0, len(pv))重新定位到(domain[0]、domain[0] + len(pv))的效果。domain[1]在這種情況下被忽略。可以增加參數
urn_factor以加快生成速度,但會增加設置時間。此方法使用表來生成隨機變量。urn_factor控製此表相對於概率向量的大小(或支持的寬度,以防 PV 不可用)的大小。由於此表是在設置期間計算的,因此增加此參數會線性增加設置所需的時間。建議將此參數保持在 2 以下。參考:
[1]UNU.RAN 參考手冊,第 5.8.2 節,“DAU -(離散)Alias-Urn 方法”,http://statmath.wu.ac.at/software/unuran/doc/unuran.html#DAU
[2]A.J.沃克 (1977)。一種生成具有一般分布的離散隨機變量的有效方法,ACM Trans。數學。軟件 3,第 253-256 頁。
例子:
>>> from scipy.stats.sampling import DiscreteAliasUrn >>> import numpy as np要使用概率向量創建隨機數生成器,請使用:
>>> pv = [0.1, 0.3, 0.6] >>> urng = np.random.default_rng() >>> rng = DiscreteAliasUrn(pv, random_state=urng)RNG 已設置完畢。現在,我們現在可以使用
rvs方法從分布中生成樣本:>>> rvs = rng.rvs(size=1000)為了驗證隨機變量是否遵循給定分布,我們可以使用卡方檢驗(作為goodness-of-fit 的度量):
>>> from scipy.stats import chisquare >>> _, freqs = np.unique(rvs, return_counts=True) >>> freqs = freqs / np.sum(freqs) >>> freqs array([0.092, 0.292, 0.616]) >>> chisquare(freqs, pv).pvalue 0.9993602047563164由於 p 值非常高,我們無法拒絕觀察到的頻率與預期頻率相同的零假設。因此,我們可以安全地假設變量是根據給定的分布生成的。請注意,這隻是給出了算法的正確性,而不是樣本的質量。
如果 PV 不可用,也可以傳遞具有 PMF 方法和有限域的類的實例。
>>> urng = np.random.default_rng() >>> class Binomial: ... def __init__(self, n, p): ... self.n = n ... self.p = p ... def pmf(self, x): ... # note that the pmf doesn't need to be normalized. ... return self.p**x * (1-self.p)**(self.n-x) ... def support(self): ... return (0, self.n) ... >>> n, p = 10, 0.2 >>> dist = Binomial(n, p) >>> rng = DiscreteAliasUrn(dist, random_state=urng)現在,我們可以使用
rvs方法從分布中采樣,並測量樣本的 goodness-of-fit:>>> rvs = rng.rvs(1000) >>> _, freqs = np.unique(rvs, return_counts=True) >>> freqs = freqs / np.sum(freqs) >>> obs_freqs = np.zeros(11) # some frequencies may be zero. >>> obs_freqs[:freqs.size] = freqs >>> pv = [dist.pmf(i) for i in range(0, 11)] >>> pv = np.asarray(pv) / np.sum(pv) >>> chisquare(obs_freqs, pv).pvalue 0.9999999999999999為了檢查樣本是否來自正確的分布,我們可以可視化樣本的直方圖:
>>> import matplotlib.pyplot as plt >>> rvs = rng.rvs(1000) >>> fig = plt.figure() >>> ax = fig.add_subplot(111) >>> x = np.arange(0, n+1) >>> fx = dist.pmf(x) >>> fx = fx / fx.sum() >>> ax.plot(x, fx, 'bo', label='true distribution') >>> ax.vlines(x, 0, fx, lw=2) >>> ax.hist(rvs, bins=np.r_[x, n+1]-0.5, density=True, alpha=0.5, ... color='r', label='samples') >>> ax.set_xlabel('x') >>> ax.set_ylabel('PMF(x)') >>> ax.set_title('Discrete Alias Urn Samples') >>> plt.legend() >>> plt.show()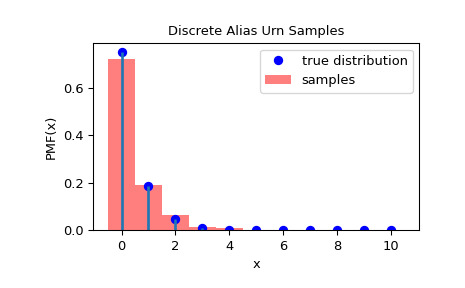
要設置
urn_factor,請使用:>>> rng = DiscreteAliasUrn(pv, urn_factor=2, random_state=urng)這使用兩倍於概率向量大小的表格從分布中生成隨機變量。
相關用法
- Python SciPy sampling.DiscreteGuideTable用法及代碼示例
- Python SciPy sampling.FastGeneratorInversion用法及代碼示例
- Python SciPy sampling.RatioUniforms用法及代碼示例
- Python SciPy sampling.TransformedDensityRejection用法及代碼示例
- Python SciPy sampling.SimpleRatioUniforms用法及代碼示例
- Python SciPy sampling.NumericalInverseHermite用法及代碼示例
- Python SciPy sampling.NumericalInversePolynomial用法及代碼示例
- Python SciPy stats.anderson用法及代碼示例
- Python SciPy stats.iqr用法及代碼示例
- Python SciPy special.exp1用法及代碼示例
- Python SciPy special.expn用法及代碼示例
- Python SciPy signal.czt_points用法及代碼示例
- Python SciPy signal.chirp用法及代碼示例
- Python SciPy stats.genpareto用法及代碼示例
- Python SciPy signal.residue用法及代碼示例
- Python SciPy special.ncfdtri用法及代碼示例
- Python SciPy special.gamma用法及代碼示例
- Python SciPy signal.iirdesign用法及代碼示例
- Python SciPy special.y1用法及代碼示例
- Python SciPy special.y0用法及代碼示例
- Python SciPy special.ellip_harm_2用法及代碼示例
- Python SciPy signal.max_len_seq用法及代碼示例
- Python SciPy sparse.isspmatrix用法及代碼示例
- Python SciPy signal.kaiser_atten用法及代碼示例
- Python SciPy stats.skewnorm用法及代碼示例
注:本文由純淨天空篩選整理自scipy.org大神的英文原創作品 scipy.stats.sampling.DiscreteAliasUrn。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。