在之前TensorFlow線性模型教程中,我們訓練了邏輯回歸模型來預測個人年收入超過5萬美元的概率,使用的是人口普查收入數據集。 當然,TensorFlow也非常適合訓練深度神經網絡,您可能會想到應該選擇哪一個呢?或者是否有可能在一個模型中結合兩者的優勢?
在本教程中,我們將介紹如何使用tf.estimator API聯合訓練寬線性模型和深度前饋(feed-forward)神經網絡。這種方法結合了memorization和generalization的優點。這種做法對於具有稀疏輸入特征的大規模回歸和分類問題(例如,具有大量可能的特征值的類別特征)是有用的。如果您有興趣了解更多關於Wide&Deep學習的作品,請查看研究論文。

上圖顯示了一個wide模型(具有稀疏特征和變換的邏輯回歸),一個deep模型(具有Embedding層和多個隱藏層的feed-forward神經網絡),以及Wide&Deep模型(兩者的聯合訓練)。使用tf.estimator高級API,隻需要三個步驟來配置一個Wide&Deep模型:
- 選擇Wide部分的特征:選擇要使用的稀疏基礎列和交叉列。
- 選擇Deep部分的特征:選擇連續值的特征列,每個類別特征列的Embedding維度以及隱藏層大小。
- 把它們一起放入一個Wide&Deep模型(
DNNLinearCombinedClassifier)。
就是這樣!我們來看一個簡單的例子。
建立
要嘗試本教程的代碼,先:
- 安裝TensorFlow。
- 下載教程代碼。
- 執行我們提供給您的數據下載腳本:
$ python data_download.py - 使用以下命令執行教程代碼,以訓練本教程中描述的Wide&Deep模型:
$ python wide_deep.py
繼續閱讀以了解此代碼如何構建這個模型。
定義基本特征列
首先,我們來定義我們將要使用的基礎類別型和連續型特征列。這些基礎列將成為模型的Wide部分和Deep部使用的構建元素。
import tensorflow as tf
# Continuous columns
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
# To show an example of hashing:
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000)
# Transformations.
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
Wide模型:具有交叉特征列的線性模型
Wide模型是一個線性模型,具有一係列稀疏和交叉的特征列:
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000),
]
你也可以閱讀TensorFlow線性模型教程了解更多細節。
具有交叉特征列的寬模型可以有效地記住特征之間的稀疏交互。這就是說,交叉特征列的一個局限性是它們沒有推廣到沒有出現在訓練數據中的特征組合。讓我們添加一個Embedding深層模型來解決這個問題。
Deep模型:帶Embedding的神經網絡
如上圖所示,深層模型是一個前饋神經網絡。每個稀疏的高維類別特征首先被轉換成低維和密集的實值向量,通常被稱為Embedding向量。這些low-dimensional密集Embedding向量與連續的特征連接,然後在正向通道中饋送到神經網絡的隱藏層。Embedding值隨機初始化,並與所有其他模型參數一起訓練,以最大限度地減少訓練損失。如果您有興趣了解更多關於Embedding的知識,請查看TensorFlow教程詞的矢量表示或詞Embedding在維基百科。
將類別列表示為神經網絡的另一種方法是通過one-hot或multi-hot表示形式。這通常適用於隻有少數可能值的分類列。作為one-hot表示的一個示例,對於關係列,"Husband"可以表示為[1,0,0,0,0,0],並且"Not-in-family"表示為[0,1,0,0,0,0]。這是一個固定的表示,而Embedding更靈活,並在訓練時計算。
我們將使用embedding_column配置分類列的Embedding,並將它們連接到連續值類型的列。我們也使用indicator_column創建一些分類列的multi-hot表示。
deep_columns = [
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(marital_status),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
tf.feature_column.embedding_column(occupation, dimension=8),
]
Embedding維度越高,模型將要學習特征表示的自由度越高。為了簡單起見,我們在這裏將所有特征列的維數設置為8。從經驗上來說,關於維數的一個更明智的決定是從log2(n)或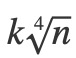 開始,其中n是特征列中唯一特征值的數量,k是一個小常量(通常小於10)。
開始,其中n是特征列中唯一特征值的數量,k是一個小常量(通常小於10)。
通過密集的Embedding,Deep模型可以更好地泛化,並對之前在訓練數據中看不到的特征對進行預測。然而,當兩個特征列之間的基礎交互矩陣是稀疏的並且high-rank時,很難學習特征列的有效低維表示。在這種情況下,大多數特征對之間的交互應該是零,除了少數,但是密集的Embedding將導致所有特征對的非零預測,因此可能over-generalize。另一方麵,具有交叉特征的線性模型可以用較少的模型參數有效地記住這些“exception rules”。
現在讓我們看看如何共同訓練Wide&Deep模型,並讓他們互相補充優點和彌補缺點。
將Wide和Deep模型組合成一個
將Wide模型和Deep模型相加,將最終的輸出對數相加作為預測,然後將預測提供給邏輯損失函數。所有的圖形定義和變量分配已經為你處理,所以你隻需要創建一個DNNLinearCombinedClassifier:
model = tf.estimator.DNNLinearCombinedClassifier(
model_dir='/tmp/census_model',
linear_feature_columns=base_columns + crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
訓練和評估模型
在我們訓練模型之前,先看看人口普查數據集, 見TensorFlow線性模型教程。可以看到data_download.py以及wide_deep.py中的input_fn。
讀取數據後,您可以訓練和評估模型:
# Train and evaluate the model every `FLAGS.epochs_per_eval` epochs.
for n in range(FLAGS.train_epochs // FLAGS.epochs_per_eval):
model.train(input_fn=lambda: input_fn(
FLAGS.train_data, FLAGS.epochs_per_eval, True, FLAGS.batch_size))
results = model.evaluate(input_fn=lambda: input_fn(
FLAGS.test_data, 1, False, FLAGS.batch_size))
# Display evaluation metrics
print('Results at epoch', (n + 1) * FLAGS.epochs_per_eval)
print('-' * 30)
for key in sorted(results):
print('%s: %s' % (key, results[key]))
最終的輸出精度應該在85.5%左右。如果你想看到一個可用的端到端的例子,你可以下載我們的示例代碼。
請注意,本教程隻是一個小數據集的簡單示例,可以幫助您熟悉API。 如果您在具有大量可能的特征值的稀疏特征列的大型數據集上進行嘗試,則Wide&Deep學習將更加強大。再次,請隨時看看我們的研究論文,了解更多關於如何應用Wide&Deep學習在實踐中的大規模機器學習問題。