在之前TensorFlow线性模型教程中,我们训练了逻辑回归模型来预测个人年收入超过5万美元的概率,使用的是人口普查收入数据集。 当然,TensorFlow也非常适合训练深度神经网络,您可能会想到应该选择哪一个呢?或者是否有可能在一个模型中结合两者的优势?
在本教程中,我们将介绍如何使用tf.estimator API联合训练宽线性模型和深度前馈(feed-forward)神经网络。这种方法结合了memorization和generalization的优点。这种做法对于具有稀疏输入特征的大规模回归和分类问题(例如,具有大量可能的特征值的类别特征)是有用的。如果您有兴趣了解更多关于Wide&Deep学习的作品,请查看研究论文。

上图显示了一个wide模型(具有稀疏特征和变换的逻辑回归),一个deep模型(具有Embedding层和多个隐藏层的feed-forward神经网络),以及Wide&Deep模型(两者的联合训练)。使用tf.estimator高级API,只需要三个步骤来配置一个Wide&Deep模型:
- 选择Wide部分的特征:选择要使用的稀疏基础列和交叉列。
- 选择Deep部分的特征:选择连续值的特征列,每个类别特征列的Embedding维度以及隐藏层大小。
- 把它们一起放入一个Wide&Deep模型(
DNNLinearCombinedClassifier)。
就是这样!我们来看一个简单的例子。
建立
要尝试本教程的代码,先:
- 安装TensorFlow。
- 下载教程代码。
- 执行我们提供给您的数据下载脚本:
$ python data_download.py - 使用以下命令执行教程代码,以训练本教程中描述的Wide&Deep模型:
$ python wide_deep.py
继续阅读以了解此代码如何构建这个模型。
定义基本特征列
首先,我们来定义我们将要使用的基础类别型和连续型特征列。这些基础列将成为模型的Wide部分和Deep部使用的构建元素。
import tensorflow as tf
# Continuous columns
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
# To show an example of hashing:
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000)
# Transformations.
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
Wide模型:具有交叉特征列的线性模型
Wide模型是一个线性模型,具有一系列稀疏和交叉的特征列:
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000),
]
你也可以阅读TensorFlow线性模型教程了解更多细节。
具有交叉特征列的宽模型可以有效地记住特征之间的稀疏交互。这就是说,交叉特征列的一个局限性是它们没有推广到没有出现在训练数据中的特征组合。让我们添加一个Embedding深层模型来解决这个问题。
Deep模型:带Embedding的神经网络
如上图所示,深层模型是一个前馈神经网络。每个稀疏的高维类别特征首先被转换成低维和密集的实值向量,通常被称为Embedding向量。这些low-dimensional密集Embedding向量与连续的特征连接,然后在正向通道中馈送到神经网络的隐藏层。Embedding值随机初始化,并与所有其他模型参数一起训练,以最大限度地减少训练损失。如果您有兴趣了解更多关于Embedding的知识,请查看TensorFlow教程词的矢量表示或词Embedding在维基百科。
将类别列表示为神经网络的另一种方法是通过one-hot或multi-hot表示形式。这通常适用于只有少数可能值的分类列。作为one-hot表示的一个示例,对于关系列,"Husband"可以表示为[1,0,0,0,0,0],并且"Not-in-family"表示为[0,1,0,0,0,0]。这是一个固定的表示,而Embedding更灵活,并在训练时计算。
我们将使用embedding_column配置分类列的Embedding,并将它们连接到连续值类型的列。我们也使用indicator_column创建一些分类列的multi-hot表示。
deep_columns = [
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(marital_status),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
tf.feature_column.embedding_column(occupation, dimension=8),
]
Embedding维度越高,模型将要学习特征表示的自由度越高。为了简单起见,我们在这里将所有特征列的维数设置为8。从经验上来说,关于维数的一个更明智的决定是从log2(n)或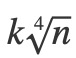 开始,其中n是特征列中唯一特征值的数量,k是一个小常量(通常小于10)。
开始,其中n是特征列中唯一特征值的数量,k是一个小常量(通常小于10)。
通过密集的Embedding,Deep模型可以更好地泛化,并对之前在训练数据中看不到的特征对进行预测。然而,当两个特征列之间的基础交互矩阵是稀疏的并且high-rank时,很难学习特征列的有效低维表示。在这种情况下,大多数特征对之间的交互应该是零,除了少数,但是密集的Embedding将导致所有特征对的非零预测,因此可能over-generalize。另一方面,具有交叉特征的线性模型可以用较少的模型参数有效地记住这些“exception rules”。
现在让我们看看如何共同训练Wide&Deep模型,并让他们互相补充优点和弥补缺点。
将Wide和Deep模型组合成一个
将Wide模型和Deep模型相加,将最终的输出对数相加作为预测,然后将预测提供给逻辑损失函数。所有的图形定义和变量分配已经为你处理,所以你只需要创建一个DNNLinearCombinedClassifier:
model = tf.estimator.DNNLinearCombinedClassifier(
model_dir='/tmp/census_model',
linear_feature_columns=base_columns + crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
训练和评估模型
在我们训练模型之前,先看看人口普查数据集, 见TensorFlow线性模型教程。可以看到data_download.py以及wide_deep.py中的input_fn。
读取数据后,您可以训练和评估模型:
# Train and evaluate the model every `FLAGS.epochs_per_eval` epochs.
for n in range(FLAGS.train_epochs // FLAGS.epochs_per_eval):
model.train(input_fn=lambda: input_fn(
FLAGS.train_data, FLAGS.epochs_per_eval, True, FLAGS.batch_size))
results = model.evaluate(input_fn=lambda: input_fn(
FLAGS.test_data, 1, False, FLAGS.batch_size))
# Display evaluation metrics
print('Results at epoch', (n + 1) * FLAGS.epochs_per_eval)
print('-' * 30)
for key in sorted(results):
print('%s: %s' % (key, results[key]))
最终的输出精度应该在85.5%左右。如果你想看到一个可用的端到端的例子,你可以下载我们的示例代码。
请注意,本教程只是一个小数据集的简单示例,可以帮助您熟悉API。 如果您在具有大量可能的特征值的稀疏特征列的大型数据集上进行尝试,则Wide&Deep学习将更加强大。再次,请随时看看我们的研究论文,了解更多关于如何应用Wide&Deep学习在实践中的大规模机器学习问题。