TensorFlow是進行large-scale數值計算的強大庫。它擅長的任務之一是實施和訓練深度神經網絡。在本教程中,我們將學習TensorFlow模型的基本構建模塊,同時構建深度卷積MNIST分類器。
這個介紹假定熟悉神經網絡和MNIST數據集。如果你沒有他們的背景,請參考MNIST初學者介紹。在開始之前務必安裝TensorFlow。
關於本教程
本教程的第一部分解釋了這個代碼文件,這是一個Tensorflow模型的基本實現。第二部分展示了一些提高準確性的方法。
您可以將本教程中的每個代碼片段複製並粘貼到Python環境中,或者您可以下載完整實現的深度網絡。
我們將在本教程中完成的任務:
-
根據查看圖像中的每個像素,創建一個softmax回歸函數,該函數是識別MNIST數字的模型
-
使用Tensorflow通過數千個示例來訓練模型以識別數字(並運行我們的第一個Tensorflow會話來執行此操作)
-
用我們的測試數據檢查模型的準確性
-
構建,訓練和測試多層卷積神經網絡以改善結果
開始
在我們創建模型之前,我們將首先加載MNIST數據集,然後啟動一個TensorFlow會話。
加載MNIST數據
如果您正在複製和粘貼本教程中的代碼,請從這裏開始這兩行代碼,它們將自動下載並讀取數據:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
這裏mnist是一個輕量級類,它將訓練,驗證和測試集存儲為NumPy數組。它還提供了一個函數來迭代數據minibatches,我們將在下麵使用。
啟動TensorFlow InteractiveSession
TensorFlow依靠高效的C++後端來完成它的計算。與此後端的連接稱為會話。 TensorFlow程序的常見用法是首先創建一個圖,然後在會話中啟動它。
在這裏,我們改為使用方便的InteractiveSession類,這使得TensorFlow在你的代碼結構上更加靈活。它允許你交互操作構建一個計算圖並運行圖。在IPython等交互式環境中工作時,這特別方便。如果你不使用一個InteractiveSession,那麽你應該在開始一個會話之前建立整個計算圖啟動圖表。
import tensorflow as tf
sess = tf.InteractiveSession()
計算圖
為了在Python中進行高效的數值計算,我們通常使用NumPy這樣的庫,在Python之外執行昂貴的操作,例如矩陣乘法,使用以另一種語言實現的高效代碼。
TensorFlow也在Python之外進行繁重的工作,但是為了避免這種開銷,還需要進一步的工作。 TensorFlow不是獨立於Python運行一個昂貴的操作,而是讓我們描述一個完全在Python之外運行的交互操作圖。這種方法類似於Theano或Torch中使用的方法。
因此,Python代碼的作用是構建這個外部計算圖,並指定運行圖的哪個部分。見計算圖部分TensorFlow入門了解更多細節。
建立一個Softmax回歸模型
在本節中,我們將建立一個單線性層的softmax回歸模型。在下一節中,我們將擴展到具有多層卷積網絡的softmax回歸的情況。
占位符
我們通過為輸入圖像和目標輸出類創建節點來開始構建計算圖。
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])
這裏x和y_不是具體的值。相反,他們都是placeholder – 我們要求TensorFlow運行計算時才會輸入值。
輸入圖像x將由一個二維張量的浮點數組成。在這裏,我們給它分配shape為[None, 784],其中784是28×28像素MNIST圖像的單一平麵的維度,None表示與批次大小相對應的第一個維度可以是任何大小。目標輸出類y_也將由2d張量組成,其中每行是one-hot 10維向量,指示對應的MNIST圖像屬於哪個數字類(0到9)。
placeholder的shape參數是可選的,但它允許TensorFlow自動捕捉源自不一致張量形狀的錯誤。
變量
我們現在為我們的模型定義權重W和偏置b。我們可以想象把這些看作是額外的投入,但是TensorFlow有更好的方法來處理它們:Variable。一個Variable是在TensorFlow計算圖中的一個值。它可以被使用,甚至被計算修改。在機器學習應用中,模型參數通常用Variable表示。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
我們將調用中每個參數的初始值傳遞給tf.Variable。在這種情況下,我們初始化W和b作為充滿零的張量。W是一個784×10矩陣(因為我們有784個輸入功能和10個輸出),而b是一個10維向量(因為我們有10個類)。
Variables可以在會話中使用之前,必須使用會話進行初始化。這一步取得已經指定的初始值(在這種情況下張量是零),並分配給每個Variable:
sess.run(tf.global_variables_initializer())
預測類和損失函數
我們現在可以實現我們的回歸模型。隻需要一行!我們將向量化的輸入圖像x和權重矩陣W相乘,加上偏置b。
y = tf.matmul(x,W) + b
我們可以很容易地指定一個損失函數。損失表明模型的預測在一個例子上有多糟糕;在所有的例子訓練,我們盡量減小損失函數值。在這裏,我們的損失函數是應用於模型預測的目標和softmax激活函數之間的cross-entropy。正如在初學者教程中,我們使用穩定的公式:
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
注意tf.nn.softmax_cross_entropy_with_logits在模型的非歸一化模型預測中內部應用softmax,並在所有類別上進行求和tf.reduce_mean取這些數目的平均值。
訓練模型
現在我們已經定義了我們的模型和訓練損失函數,然後使用TensorFlow進行訓練是很簡單的。由於TensorFlow知道整個計算圖,因此可以使用自動微分來查找相對於每個變量的損失的梯度。 TensorFlow有多種內置優化算法。對於這個例子,我們將使用最陡的梯度下降,步長為0.5,下降交叉熵。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
TensorFlow在這一行中實際上做的事情是在計算圖中添加新的操作。這些操作包括計算梯度、計算參數更新步驟、以及將更新步驟應用於參數。
train_step返回的操作,運行時,會將梯度下降更新應用於參數。訓練模型可以通過反複運行train_step來完成。
for _ in range(1000):
batch = mnist.train.next_batch(100)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
我們在每次訓練迭代中加載100個訓練樣例。我們然後運行train_step操作,使用feed_dict取代placeholder張量x和y_。請注意,您可以使用feed_dict替換計算圖中的任何張量 – 它不僅限於placeholder。
評估模型
我們的模型有多好?
首先我們要弄清楚我們在哪裏預測了正確的標簽。tf.argmax是一個非常有用的函數,它可以得出在張量中沿某個軸值最大的索引。例如,tf.argmax(y,1)是我們模型認為最有可能的標簽,而tf.argmax(y_,1)是真正的標簽。我們可以用tf.equal檢查我們的預測是否符合事實。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
這給了我們一個布爾的列表。為了確定什麽分數是正確的,我們轉換為浮點數,然後取平均值。例如,[True, False, True, True]會成為[1,0,1,1]這將成為0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
最後,我們可以評估我們的測試數據的準確性,大約92%。
print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
構建一個多層卷積網絡
在MNIST上獲得92%的準確性還不夠好。在這一節中,我們將解決這個問題,從一個非常簡單的模型跳到一些中等複雜的問題:一個小的卷積神經網絡。這將使我們達到約99.2%的準確性 – 不是最先進的,但已經很不錯了。
下麵是一個用TensorBoard創建的關於我們將要構建的模型的圖表:
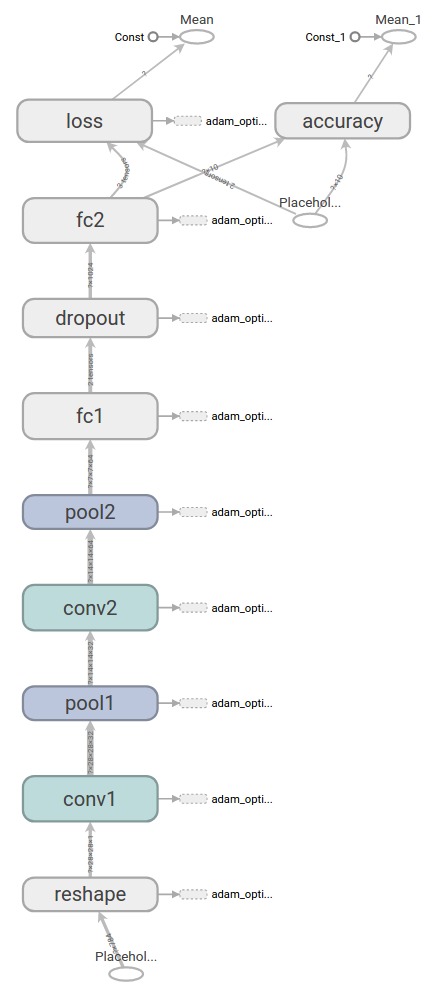
權重初始化
要創建這個模型,我們需要創建很多權重和偏置。一般應該用少量的噪聲初始化權重,以防止對稱性破壞,並防止0梯度。因為我們正在使用RELU神經元,為了避免”dead neurons”,用比較小的正浮點數初始化它們也是一個很好的實踐。為了方便起見,創建兩個輔助函數。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
卷積和pooling(池化)
TensorFlow也為卷積和pooling操作提供了很大的靈活性。我們如何處理邊界?我們的步幅是多少?在這個例子中,我們總是選擇普通版本。我們的卷積使用步長為1,並填充零,以便輸出與輸入大小相同。我們的池化采用2×2塊的普通最大pooling。為了保持我們的代碼更清晰,我們也將這些操作抽象為函數。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
第一卷積層
我們現在可以實現我們的第一層。它將由卷積組成,然後是最大池化。卷積將為每個5×5塊計算32個特征。它的權重張量形狀為[5, 5, 1, 32]。前兩個維度是色塊大小,下一個是輸入通道的數量,最後一個是輸出通道的數量。每個輸出通道還會有一個帶有分量的偏向量。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
為了應用圖層,我們首先重塑x到4d張量,第二維度和第三維度對應於圖像寬度和高度,並且最後一個維度對應於色彩通道的數量。
x_image = tf.reshape(x, [-1, 28, 28, 1])
然後我們用權重張量對x_image做卷積,加上偏差,應用ReLU函數,最後是最大池化。該max_pool_2x2方法將圖像大小減少到14×14。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
第二卷積層
為了建立一個深層網絡,我們堆疊了這種類型的幾個層。第二層將為每個5×5塊生成64個特征。
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
密集連接層
現在圖像尺寸已經減小到7×7,我們添加一個帶有1024個神經元的全連接(FC)圖層,以允許在整個圖像上進行處理。我們將池化層的張量重塑為一批向量,乘以權重矩陣,添加一個偏差,並應用一個ReLU。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
Dropout
為了減少過擬合,我們將在輸出層之前應用dropout。創建一個placeholder在dropout保持神經元輸出的概率。這可以讓我們在訓練過程中開啟dropout,並在測試過程中將其關閉。 TensorFlow的tf.nn.dropoutop除了掩蔽它們之外,還自動處理縮放神經元輸出,所以dropout隻是在沒有任何額外縮放的情況下工作。1
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
輸出層
最後,我們添加一個圖層,就像上麵的一層softmax回歸一樣。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
訓練和評估模型
這個模型有多好?為了訓練和評估,我們將使用與上述簡單的一層SoftMax網絡幾乎相同的代碼。
不同之處在於:
-
我們將用更複雜的ADAM優化器替代最陡的梯度下降優化器。
-
我們將包含附加參數
keep_prob在feed_dict控製dropout率。 -
我們將在訓練過程中每100次迭代輸出一次日誌。
我們也將使用tf.Session而不是tf.InteractiveSession。這更好地分離了創建圖(模型說明)的過程和評估圖(模型擬合)的過程。這樣做通常使代碼更清晰。 tf.Session是在with塊中創建,所以一旦塊被退出,它就會被自動銷毀。
隨意運行這個代碼。請注意,它會進行20,000次訓練迭代,可能需要一段時間(可能長達半小時),具體取決於您的處理器。
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
運行此代碼後的最終測試集精度約為99.2%。
我們已經學會了如何使用TensorFlow快速,輕鬆地構建,訓練和評估相當複雜的深度學習模型。
1:對於這個小卷積網絡,沒有dropout, 性能實際上幾乎是相同的。dropout對於減少過度擬合通常是非常有效的,但是在訓練非常大的神經網絡時它是最有用的。↩