Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas Series.clip_upper()用于裁剪超过传递的最大值的值。阈值作为参数传递,并且所有大于阈值的串联值都等于阈值。
用法:Series.clip_upper(threshold, axis=None, inplace=False)
参数:
threshold:数字或类似列表,设置最大阈值,如果是列表,则为调用者系列中的每个值设置单独的阈值(给定列表大小相同)
axis:0或“索引”按行应用方法,1或“列”按列应用。
inplace:在调用者系列本身中进行更改。 (用新值覆盖)
返回类型:具有更新值的系列
要下载以下示例中使用的数据集,请单击此处。在以下示例中,使用的 DataFrame 包含一些NBA球员的数据。下面是任何操作之前的数据帧图像。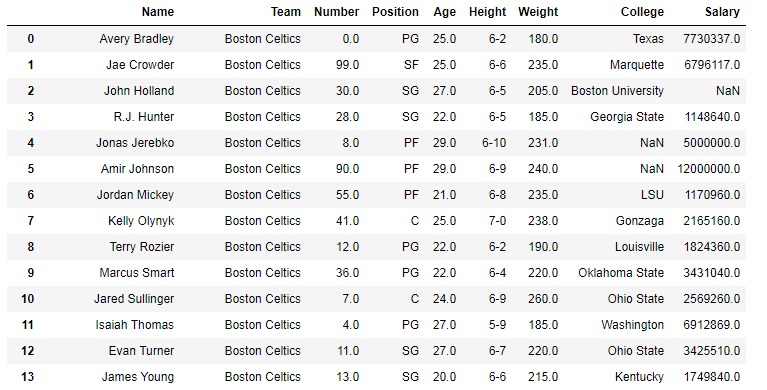
例子1:适用于单值系列
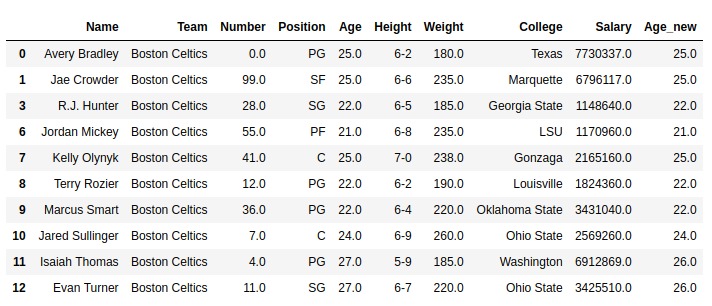
在此示例中,最大阈值26作为参数传递给.clip_upper()方法。在数据帧的Age列上调用此方法,并将新值存储在Age_new列中。在执行任何操作之前,使用.dropna()删除空行
# importing pandas module
import pandas as pd
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True)
# setting threshold value
threshold = 26.0
# applying method and passing to new column
data["Age_new"]= data["Age"].clip_upper(threshold)
# displaying top 10 rows
data.head(10)输出:
如输出图像中所示,Age_new列的最大值为26。超过26的所有值均被裁剪并等于26。
范例2:应用于具有列表类型值的系列
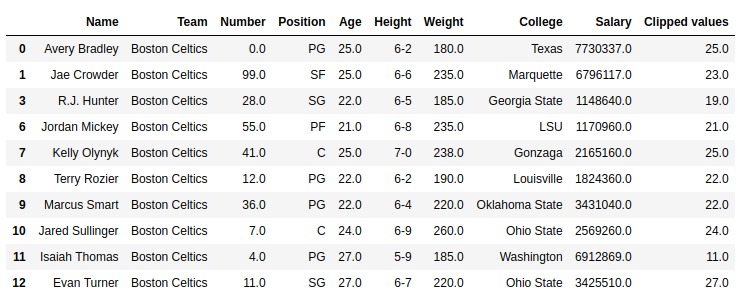
在此示例中,使用以下方法提取并存储“年龄”列的前10行:.head() 方法。之后,将创建一个相同长度的列表,并将其传递给的阈值参数.clip_upper() 为串联的每个值设置单独的阈值的方法。返回的值存储在新列“ clipped_values”中。
# importing pandas module
import pandas as pd
# importing regex module
import re
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org /wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True)
# returning top rows
new_data = data.head(10).copy()
# list for separate threshold values
threshold =[27, 23, 19, 30, 26, 22, 22, 41, 11, 33]
# applying method and returning to new column
new_data["Clipped values"]= new_data["Age"].clip_upper(threshold = threshold)
# display
new_data输出:
如输出图像所示,根据传递的列表,每个串联的值都有不同的阈值,因此,根据每个元素的单独阈值返回结果。所有比其各自的阈值大的值都被缩减到阈值。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas Series.clip_upper()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。