Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas Index.value_counts()函数返回包含唯一值计数的对象。结果对象将按降序排列,因此第一个元素是最frequently-occurring元素。默认情况下不包括NA值。
用法: Index.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
参数:
normalize:如果为True,则返回的对象将包含唯一值的相对频率。
sort:按值排序
ascending:升序排列
bins:而不是对值进行计数,而是将它们分组到half-open箱中,这是pd.cut的一种便利,仅适用于数字数据
dropna:不包括NaN计数。
返回:数量:系列
范例1:采用Index.value_counts()函数计算给定索引中唯一值的数量。
# importing pandas as pd
import pandas as pd
# Creating the index
idx = pd.Index(['Harry', 'Mike', 'Arther', 'Nick',
'Harry', 'Arther'], name ='Student')
# Print the Index
print(idx)输出:
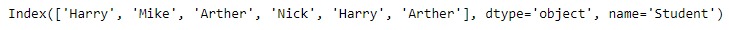
让我们找到索引中所有唯一值的计数。
# find the count of unique values in the index
idx.value_counts()输出:

该函数已返回给定索引中所有唯一值的计数。请注意,函数返回的对象包含值的降序出现。
范例2:采用Index.value_counts()函数查找给定索引中所有唯一值的计数。
# importing pandas as pd
import pandas as pd
# Creating the index
idx = pd.Index([21, 10, 30, 40, 50, 10, 50])
# Print the Index
print(idx)输出:
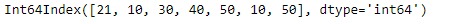
让我们计算一下索引中所有唯一值的出现。
# for finding the count of all
# unique values in the index.
idx.value_counts()输出:
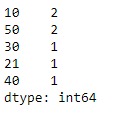
该函数已返回索引中所有唯一值的计数。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas Index.value_counts()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。