Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas dataframe.reindex()函数使用可选的填充逻辑使DataFrame符合新索引,将NA /NaN放置在先前索引中没有值的位置。除非新索引等于当前索引并且copy = False,否则将生成一个新对象。
用法: DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
参数:
labels:新标签/索引使“ axis”指定的轴与之一致。
index, columns:要符合的新标签/索引。最好是一个Index对象,以避免重复数据
axis:轴到目标。可以是轴名称(“索引”,“列”)或数字(0、1)。
method:{None,“ backfill” /“ bfill”,“ pad” /“ ffill”,“ nearest”},可选
copy:即使传递的索引相同,也返回一个新对象
level:在一个级别上广播,在传递的MultiIndex级别上匹配索引值
fill_value:在计算之前,请使用此值填充现有的缺失(NaN)值以及成功完成DataFrame对齐所需的任何新元素。如果两个对应的DataFrame位置中的数据均丢失,则结果将丢失。
limit:向前或向后填充的最大连续元素数
tolerance:不完全匹配的原始标签和新标签之间的最大距离。匹配位置处的索引值最满足方程abs(index [indexer]-target)
返回:重新索引:DataFrame
范例1:采用reindex()用于重新索引 DataFrame 的函数。默认情况下,新索引中在 DataFrame 中没有对应记录的值被分配为NaN。
注意:我们可以通过将值传递给关键字fill_value来填充缺失的值。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["first", "second", "third", "fourth", "fifth"])
# Print the dataframe
df
让我们使用dataframe.reindex()重新索引 DataFrame 的函数
# reindexing with new index values
df.reindex(["first", "dues", "trois", "fourth", "fifth"])输出:
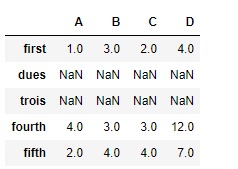
注意输出,新索引填充为NaN值,我们可以使用参数fill_value填写缺少的值
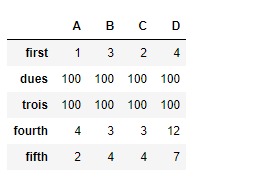
# filling the missing values by 100
df.reindex(["first", "dues", "trois", "fourth", "fifth"], fill_value = 100)输出:
范例2:采用reindex()重新索引列轴的函数
# importing pandas as pd
import pandas as pd
# Creating the first dataframe
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]})
# reindexing the column axis with
# old and new index values
df.reindex(columns =["A", "B", "D", "E"])输出:
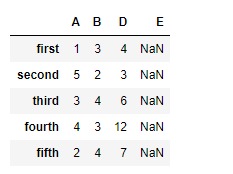
注意,我们有NaN重新编制索引后,新列中的值会发生变化,我们可以解决重新编制索引时遗漏的值。通过论证fill_value 函数。
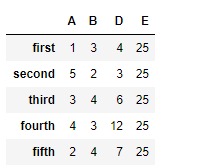
# reindex the columns
# fill the missing values by 25
df.reindex(columns =["A", "B", "D", "E"], fill_value = 25)输出:
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas dataframe.reindex()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。