Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
数据分析的重要部分是分析重复值并将其删除。 Pandas drop_duplicates()方法有助于从 DataFrame 中删除重复项。
用法:DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
参数:
subset:子集采用一列或一列标签列表。默认值为无。传递列后,它将仅将它们视为重复项。
keep:keep是控制如何考虑重复值。它只有三个不同的值,默认值为“第一”。
- 如果为“第一个”,则它将第一个值视为唯一值,并将其余相同的值视为重复值。
- 如果为“ last”,则它将last值视为唯一值,并将其余相同的值视为重复值。
- 如果为False,则将所有相同的值视为重复项
inplace:布尔值,如果为True,则删除重复的行。
返回类型:根据传递的参数删除了重复行的DataFrame。
要下载使用的CSV文件,请单击此处。
范例1:删除具有相同名字的行
在以下示例中,具有相同名字的行将被删除,并返回一个新的数据帧。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# sorting by first name
data.sort_values("First Name", inplace = True)
# dropping ALL duplicte values
data.drop_duplicates(subset ="First Name",
keep = False, inplace = True)
# displaying data
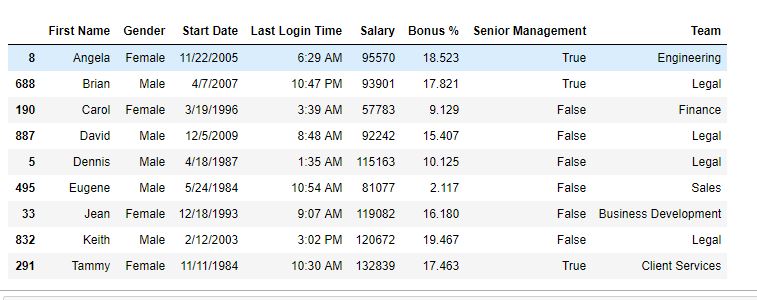
data输出:
如图所示,具有相同名称的行已从 DataFrame 中删除。
范例2:删除所有重复值的行
在此示例中,将删除具有所有值的行。由于csv文件没有这样的行,因此将复制一个随机行,然后将其首先插入数据帧。
#importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
#length before adding row
length1 = len(data)
# manually inserting duplicate of a row of row 440
data.loc[1001] = [data["First Name"][440],
data["Gender"][440],
data["Start Date"][440],
data["Last Login Time"][440],
data["Salary"][440],
data["Bonus %"][440],
data["Senior Management"][440],
data["Team"][440]]
# length after adding row
length2= len(data)
# sorting by first name
data.sort_values("First Name", inplace=True)
# dropping duplicate values
data.drop_duplicates(keep=False,inplace=True)
# length after removing duplicates
length3=len(data)
# printing all data frame lengths
print(length1, length2, length3)
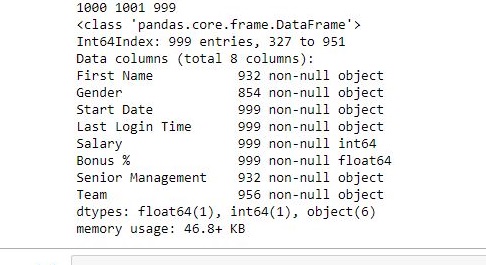
输出:
如输出图像中所示,删除重复项后的长度为999。由于keep参数设置为False,因此删除了所有重复行。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Series.str.len()用法及代码示例
- Python Pandas.factorize()用法及代码示例
- Python Pandas TimedeltaIndex.name用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.between()用法及代码示例
- Python Pandas DataFrame.where()用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas.pivot_table()用法及代码示例
- Python Pandas Series.mod()用法及代码示例
- Python Pandas Dataframe.at[ ]用法及代码示例
- Python Pandas Dataframe.iat[ ]用法及代码示例
- Python Pandas.pivot()用法及代码示例
- Python Pandas dataframe.mul()用法及代码示例
- Python Pandas.melt()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas dataframe.drop_duplicates()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。