使用Scikit学习的主题建模
潜在狄利克雷分配(LDA)是一种算法,用于发现语料库中存在的主题。主题建模相关的开源库不少,但如果你使用Python,那么主要的竞争者是scickit learn和Gensim。 Gensim是一个非常棒的库,对于大型文本语料库非常好。然而,Gensim不包括Non-negative矩阵分解(NMF)。支持NMF的数学基础与LDA完全不同。我发现比较两种算法的结果很有意思,并且发现NMF有时会为较小的数据集产生更有意义的主题。 NMF已被纳入Scikit学习相当长一段时间,但LDA最近才被纳入(2015年末)。关于使用Scikit Learn的好处是它带来了API一致性,这使得使用LDA和NMF执行主题建模的编程差异几乎是微不足道的。 Scikit Learn还包括NMF的seeding选项,它极大地有助于算法收敛,并提供LDA的在线和批处理变体。
LDA和NMF如何工作?
我不会涉及任何冗长的数学细节 – 有许多博客文章和学术期刊文章对此有详细介绍。虽然LDA和NMF具有不同的数学基础,但这两种算法都能够返回属于语料库中的主题的文档和属于主题的单词。 LDA基于概率图形建模,而NMF依赖于线性代数。两种算法都将一个词组矩阵作为输入(即,每个文档表示为一行,每列包含语料库中单词的计数)。然后每个算法的目的是产生2个更小的矩阵;一个文档到主题的矩阵和一个主题到单词的矩阵,当它们相乘时再现出具有最低误差的文档-单词矩阵。
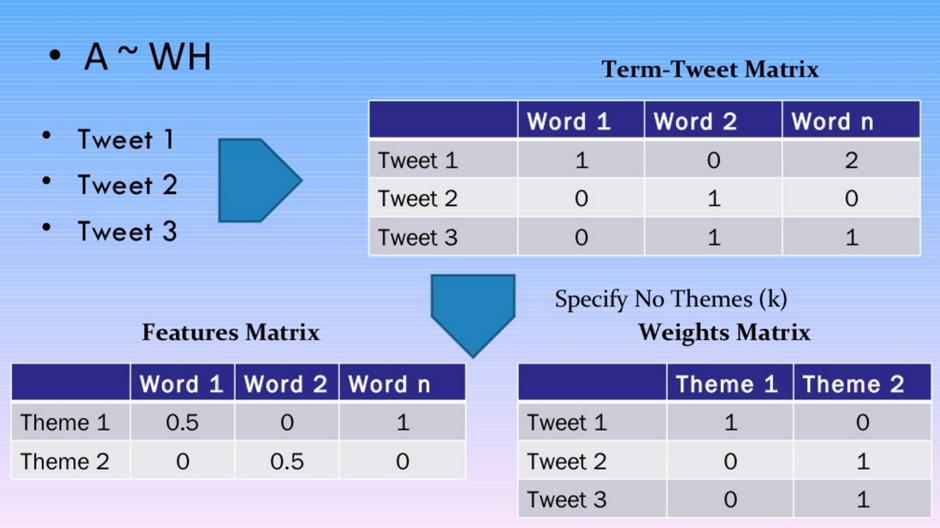
这里没有魔法 – 你只需要指定主题的数量!
到底设置多少个主题?这是个问题! NMF和LDA都无法自动确定主题的数量,因此必须指定。
数据集预处理
我搜索到了一个很棒的数据集,并最终选择了20个Newsgoups数据集。我选择了一个易于理解和加载Scikit Learn的数据集。该数据集很容易解释,因为这20个新闻组是已知的,并且可以将生成的主题与正在讨论的已知主题进行比较。数据集中排除了页眉,页脚和引号。
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.data
在Scikit Learn中创建词组矩阵非常简单 – 所有这些繁重的工作都是通过为文本数据集提供的特征提取功能完成的。将tf-idf转换应用于NMF必须使用TfidfVectorizer处理的单词矩阵包。另一方面,作为概率图形模型(即处理概率)的LDA仅需要原始计数,因此使用CountVectorizer。停用单词被删除,包含在单词矩阵中的术语数量限制在前1000位。
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
no_features = 1000
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
# LDA can only use raw term counts for LDA because it is a probabilistic graphical model
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tf = tf_vectorizer.fit_transform(documents)
tf_feature_names = tf_vectorizer.get_feature_names()
Scikit Learn中的NMF和LDA
如前所述,算法无法自动确定主题数量,并且在运行算法时必须设置此值。有关可用参数的综合文档可用于两者NMF和LDA。用’nndsvd’初始化NMF中的W和H矩阵,而不是随机初始化,可以缩短NMF收敛的时间。 LDA也可以设置为以批处理或在线模式运行。
from sklearn.decomposition import NMF, LatentDirichletAllocation
no_topics = 20
# Run NMF
nmf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf)
# Run LDA
lda = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
显示和评估主题
由NMF和LDA返回的结果矩阵的结构是相同的,用于访问返回矩阵的Scikit Learn接口也是相同的。这允许使用能够显示主题中的热门词汇的通用Python方法。主题未被算法标记 – 分配了数字索引。
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
no_top_words = 10
display_topics(nmf, tfidf_feature_names, no_top_words)
display_topics(lda, tf_feature_names, no_top_words)
使用NMF和LDA生成的主题显示如下。从NMF生成的主题看,主题0和主题8似乎并不是特别的东西,但其他主题可以根据顶部的单词来解释。用于20个新闻组数据集的LDA产生2个具有噪声数据的主题(即主题4和7)以及一些难以解释的主题(即主题3和主题9)。我想说NMF能够在20个新闻组数据集中找到更有意义的主题。
NMF主题:
主题0:人们不会认为像知道时间正确的善意所说的
主题1:windows文件使用dos文件窗口使用程序问题卡
主题2:神耶稣圣经基督信仰相信基督徒基督徒教会罪
主题3:驱动器scsi驱动器硬盘ide控制器软盘cd mac
主题4:游戏队年度赛季球员打曲棍球赢球员
主题5:核心芯片加密解码器密钥政府代管公共使用算法
主题6:感谢您知道邮件提前嗨任何人信息寻找帮助
主题7:汽车新款00销售价格10报价条件出货20
主题8:就像没有想到会得到哦告诉平均罚款
主题9:edu很快cs大学com电子邮件互联网文章ftp发送
LDA主题:
主题0:政府人员法律枪国家总统州公开使用
主题1:驱动器卡磁盘位scsi使用mac内存感谢电脑
主题2:说人民亚美尼亚人土耳其确实看到去了女人
主题3:一年好的时候像汽车队的年轻人一样想
主题4:10 00 15 25 12 11 20 14 17 16
主题5:windows窗口程序版本文件dos使用文件可用显示
主题6:edu文件空间com信息邮件数据发送可用程序
主题7:ax max b8f g9v a86 pl 145 1d9 0t 34u
主题8:上帝的人耶稣相信确实认为以色列的基督徒是真的
主题9:不要知道,只要认为自己想用就好
在我的下一篇博客文章中,我将讨论主题解释并展示主题中的顶级文档如何显示。
完整代码清单
只有36行Python代码和一些Scikit Learn魔法,可以实现多少功能。完整的代码清单如下所示:
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.datasets import fetch_20newsgroups
from sklearn.decomposition import NMF, LatentDirichletAllocation
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.data
no_features = 1000
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
# LDA can only use raw term counts for LDA because it is a probabilistic graphical model
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tf = tf_vectorizer.fit_transform(documents)
tf_feature_names = tf_vectorizer.get_feature_names()
no_topics = 20
# Run NMF
nmf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf)
# Run LDA
lda = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
no_top_words = 10
display_topics(nmf, tfidf_feature_names, no_top_words)
display_topics(lda, tf_feature_names, no_top_words)