HTML中的normalizeDocument()方法用於通過刪除任何空文本節點(如果存在)來標準化HTML文檔。刪除空節點後,它還會合並文檔中存在的所有相鄰節點。
例如,考慮以下元素:
Element Geeks
Text node:""
Text node:"Hello "
Text node:"wor"
Text node:"ld"
標準化後的以上元素將變為“Hello world”。
注意:任何瀏覽器均不支持此方法,但它用作DOM normalize()方法並顯示輸出。
用法:
geeknode.normalize()
參數:
- normalize()方法不需要任何參數。
例:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=utf-8" />
<title>GeeksForGeeks | HTML DOM Normalize Method</title>
</head>
<body>
<script type="text/javascript">
var parent = document.createElement("div");
parent.appendChild(document.createTextNode("Child 1 "));
parent.appendChild(document.createTextNode("Child 2 "));
parent.appendChild(document.createTextNode("Child 3"));
// Here the length of parent's child nodes would be 3,
// you can check the same
// using parent.childNodes.length.
alert('Before Normalize:child nodes length:' +
parent.childNodes.length);
parent.normalize();
document.body.appendChild(parent);
// Now, parent.childNodes.length === 1
// Content of all 3 childs nodes
// are in one child node only.
alert('After Normalize:child nodes length:' +
parent.childNodes.length);
</script>
</body>
</html>輸出:
在Normalize()調用之前:
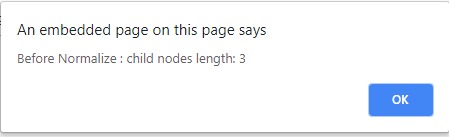
在Normalize()調用之後:
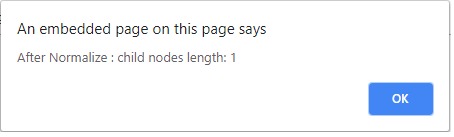
支持的瀏覽器:DOM normalizeDocument()方法不支持主要的瀏覽器
相關用法
- PHP DOMDocument normalizeDocument()用法及代碼示例
- HTML DOM contains()用法及代碼示例
- HTML DOM fullscreenEnabled()用法及代碼示例
- HTML DOM getElementById()用法及代碼示例
- HTML DOM History go()用法及代碼示例
- HTML DOM write()用法及代碼示例
- HTML DOM setNamedItem()用法及代碼示例
- HTML DOM getElementsByName()用法及代碼示例
- HTML DOM isDefaultNamespace()用法及代碼示例
- HTML DOM importNode()用法及代碼示例
- HTML DOM getElementsByClassName()用法及代碼示例
- HTML DOM getNamedItem()用法及代碼示例
- HTML DOM open()用法及代碼示例
- HTML DOM getElementsByTagName()用法及代碼示例
- HTML DOM removeAttribute()用法及代碼示例
注:本文由純淨天空篩選整理自KV30大神的英文原創作品 HTML | DOM normalizeDocument() Method。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。