下麵是章節樸素貝葉斯的正文(其他內容參見全文目錄)
樸素貝葉斯是一個簡單的多分類算法。之所以稱為樸素,是因為該算法假設特征之間相互獨立。樸素貝葉斯的訓練非常高效:通過一趟遍曆訓練數據,計算出每個特征對於給定標簽的條件概率分布,然後應用貝葉斯定理計算標簽對於觀察值的條件概率分布,最後使用這個條件概率進行預測。
樸素貝葉斯算法易於求解的核心原理是:
1) 貝葉斯公式: p(x∩C)=p(x)*p(C|x)=p(C)*p(x|C), 即p(C|x) = p(C) * p(x|C)/p(x)
2)當特征相互獨立的情況下,所有特征同時出現的概率等於每個特征出現的概率之乘積,即:
![]()
基於上述原理,樸素貝葉斯在分類問題可以用公式表達為:
![]()
其中Z = p(x)他的隻依賴於x1, x2, …, xn,而不依賴於類型,即對所有類型來說,Z都是一樣的,所以在實際計算中可以把這個省去。也就是說,樸素貝葉斯分類要解決的問題是:
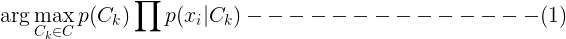
即通過公式計算出每一類的權值,然後取取值最大的類作為預測結果。其中arg max f(Ck)表示使f(Ck)最大的Ck的值。
MLlib支持的是多項式樸素貝葉斯 ,該算法經常用於文檔分類。為什麽要用多項式樸的素貝葉斯?這是因為,當有大量特征的時候,就會有多個特征值(浮點數)相乘,一方麵計算量大,另外也有浮點數溢出的風險。所以我們可以對公式(1)取對數,根據log(x *y) = log(x) + log(y), 我們可以得到:
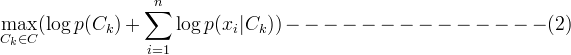
公式(2)就是一個關於概率p(xi)的多項式。
在文檔分類的應用場景中,觀察值是文檔的特征,每個特征值用詞頻表示。這樣每個特征值>=0,對於特征值等於0的情況,需要做特殊處理,根據公式(1),由於是相乘,如果某個特征為0,那麽,即使其他特征頻數很大,最後結果也等於0。所以需要對特征的頻度做特殊處理,常用的方法有Additive Smoothing(加法平滑,平滑參數λ=1.0)。文本分類中特征向量一般是稀疏的,所以可以使用SparseVector來利用這個稀疏性。另外由於訓練數據隻使用一次,所以不用緩存。
樸素貝葉斯實現了多項式貝葉斯。它以RDD[LabeledPoint]和平滑參數lambda作為輸入,輸出一個樸素貝葉斯模型 ,模型可用於評估和預測。示例如下:
from pyspark.mllib.classification import NaiveBayes
from pyspark.mllib.linalg import Vectors
from pyspark.mllib.regression import LabeledPoint
def parseLine(line):
parts = line.split(',')
label = float(parts[0])
features = Vectors.dense([float(x) for x in parts[1].split(' ')])
return LabeledPoint(label, features)
data = sc.textFile('data/mllib/sample_naive_bayes_data.txt').map(parseLine)
# Split data aproximately into training (60%) and test (40%)
training, test = data.randomSplit([0.6, 0.4], seed = 0)
# Train a naive Bayes model.
model = NaiveBayes.train(training, 1.0)
# Make prediction and test accuracy.
predictionAndLabel = test.map(lambda p : (model.predict(p.features), p.label))
accuracy = 1.0 * predictionAndLabel.filter(lambda (x, v): x == v).count() / test.count()