使用线性回归模型来校准数值预测
用法
cal_estimate_linear(
.data,
truth = NULL,
estimate = dplyr::matches("^.pred$"),
smooth = TRUE,
parameters = NULL,
...,
.by = NULL
)
# S3 method for data.frame
cal_estimate_linear(
.data,
truth = NULL,
estimate = dplyr::matches("^.pred$"),
smooth = TRUE,
parameters = NULL,
...,
.by = NULL
)
# S3 method for tune_results
cal_estimate_linear(
.data,
truth = NULL,
estimate = dplyr::matches("^.pred$"),
smooth = TRUE,
parameters = NULL,
...
)
# S3 method for grouped_df
cal_estimate_linear(
.data,
truth = NULL,
estimate = NULL,
smooth = TRUE,
parameters = NULL,
...
)参数
- .data
-
是未分组的
data.frame对象或tune_results对象,其中包含预测列。 - truth
-
观察到的结果数据的列标识符(数字)。这应该是一个不带引号的列名。
- estimate
-
预测值的列标识符
- smooth
-
适用于线性模型。当
TRUE时,它在使用样条项的广义加法模型之间切换;当FALSE时,它在简单线性回归之间切换。 - parameters
-
(可选)可选的调整参数值小标题,可用于在处理之前过滤预测值。仅适用于
tune_results对象。 - ...
-
传递给用于计算新预测的模型或例程的附加参数。
- .by
-
分组变量的列标识符。这应该是一个不带引号的列名称,用于选择用于分组的定性变量。默认为
NULL。当.by = NULL时,不会进行分组。
细节
该函数使用其他包中的现有建模函数来创建校准:
-
当
smooth设置为FALSE时,使用stats::glm() -
当
smooth设置为TRUE时,使用mgcv::gam()
这些方法估计未修改的预测值中的关系,然后在调用 cal_apply() 时消除该趋势。
例子
library(dplyr)
library(ggplot2)
head(boosting_predictions_test)
#> # A tibble: 6 × 2
#> outcome .pred
#> <dbl> <dbl>
#> 1 -4.65 4.12
#> 2 1.12 1.83
#> 3 14.7 13.1
#> 4 36.3 19.1
#> 5 14.1 14.9
#> 6 -4.22 8.10
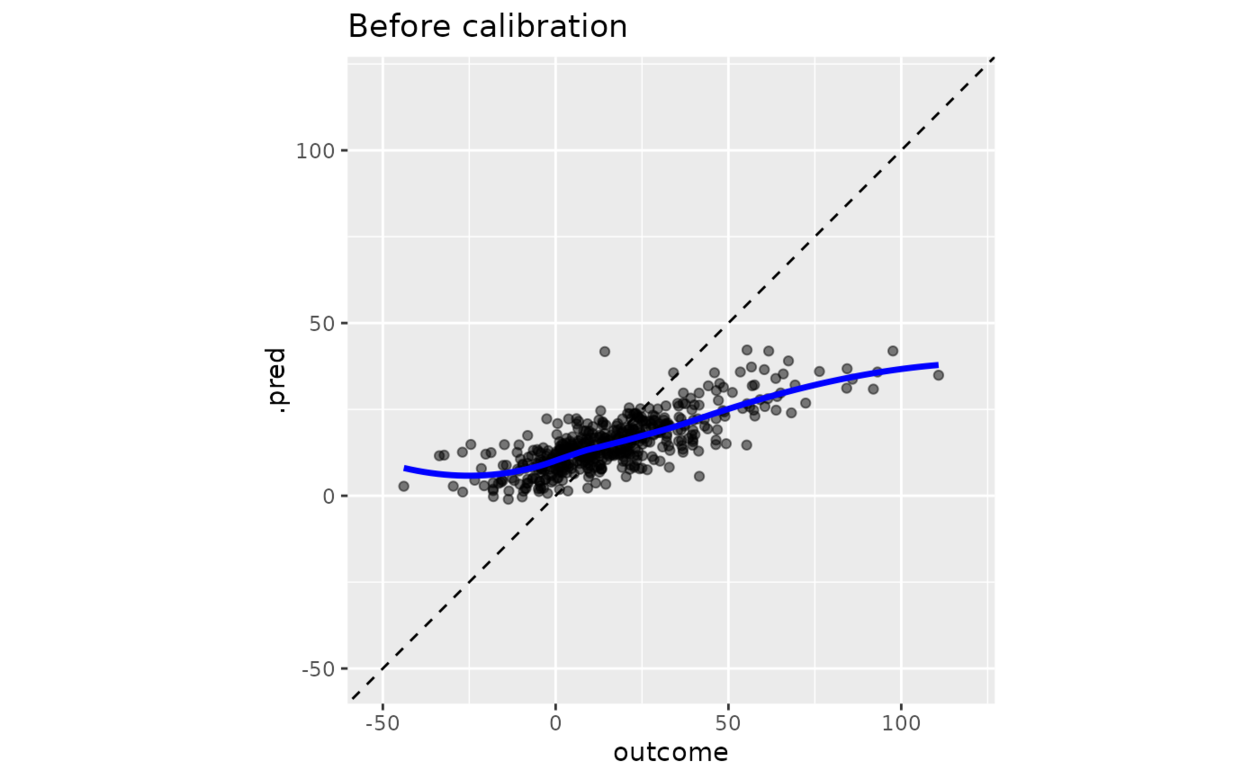
# ------------------------------------------------------------------------------
# Before calibration
y_rng <- extendrange(boosting_predictions_test$outcome)
boosting_predictions_test %>%
ggplot(aes(outcome, .pred)) +
geom_abline(lty = 2) +
geom_point(alpha = 1 / 2) +
geom_smooth(se = FALSE, col = "blue", linewidth = 1.2, alpha = 3 / 4) +
coord_equal(xlim = y_rng, ylim = y_rng) +
ggtitle("Before calibration")
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'
 # ------------------------------------------------------------------------------
# Smoothed trend removal
smoothed_cal <-
boosting_predictions_oob %>%
# It will automatically identify the predicted value columns when the
# standard tidymodels naming conventions are used.
cal_estimate_linear(outcome)
smoothed_cal
#>
#> ── Regression Calibration
#> Method: Generalized additive model
#> Source class: Data Frame
#> Data points: 2,000
#> Truth variable: `outcome`
#> Estimate variable: `.pred`
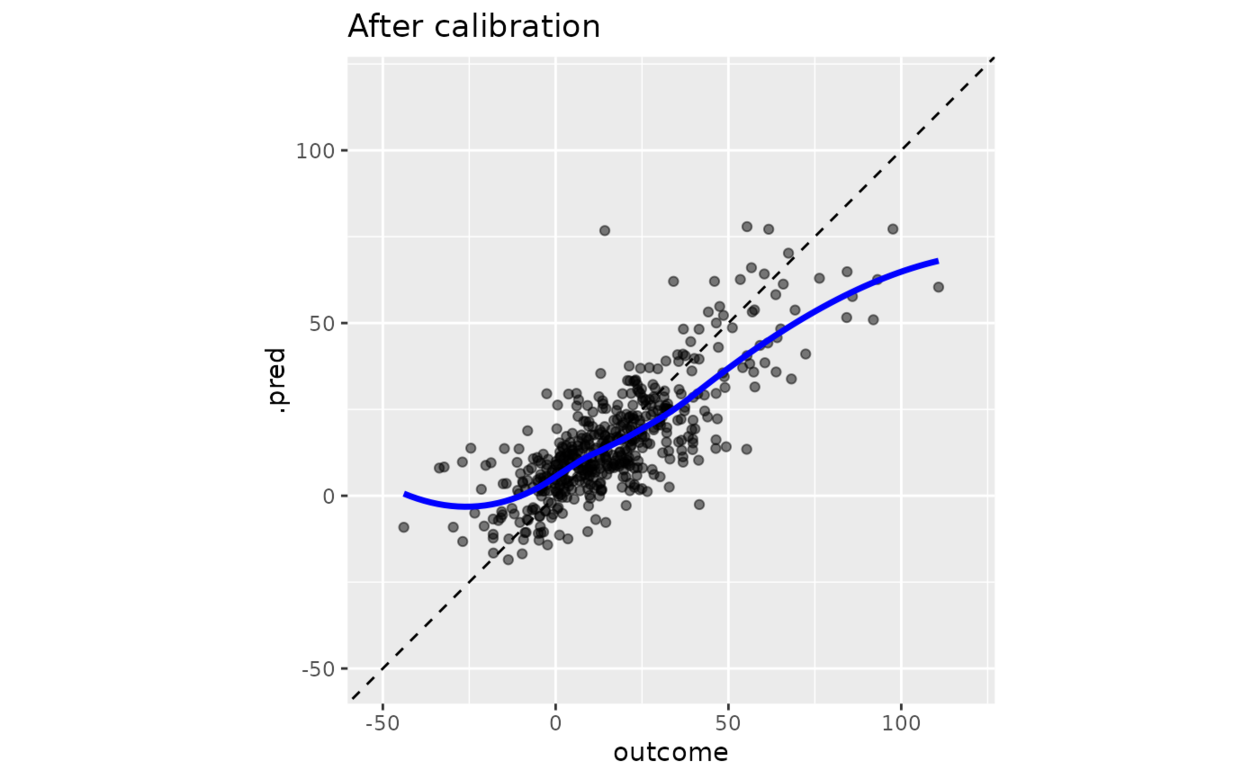
boosting_predictions_test %>%
cal_apply(smoothed_cal) %>%
ggplot(aes(outcome, .pred)) +
geom_abline(lty = 2) +
geom_point(alpha = 1 / 2) +
geom_smooth(se = FALSE, col = "blue", linewidth = 1.2, alpha = 3 / 4) +
coord_equal(xlim = y_rng, ylim = y_rng) +
ggtitle("After calibration")
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'
# ------------------------------------------------------------------------------
# Smoothed trend removal
smoothed_cal <-
boosting_predictions_oob %>%
# It will automatically identify the predicted value columns when the
# standard tidymodels naming conventions are used.
cal_estimate_linear(outcome)
smoothed_cal
#>
#> ── Regression Calibration
#> Method: Generalized additive model
#> Source class: Data Frame
#> Data points: 2,000
#> Truth variable: `outcome`
#> Estimate variable: `.pred`
boosting_predictions_test %>%
cal_apply(smoothed_cal) %>%
ggplot(aes(outcome, .pred)) +
geom_abline(lty = 2) +
geom_point(alpha = 1 / 2) +
geom_smooth(se = FALSE, col = "blue", linewidth = 1.2, alpha = 3 / 4) +
coord_equal(xlim = y_rng, ylim = y_rng) +
ggtitle("After calibration")
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'
相关用法
- R probably cal_estimate_logistic 使用逻辑回归模型来校准概率
- R probably cal_estimate_multinomial 使用多项校准模型来计算新的概率
- R probably cal_estimate_beta 使用 Beta 校准模型来计算新概率
- R probably cal_estimate_isotonic 使用等渗回归模型来校准模型预测。
- R probably cal_estimate_isotonic_boot 使用引导等渗回归模型来校准概率
- R probably cal_plot_logistic 通过逻辑回归绘制概率校准图
- R probably cal_plot_breaks 通过分箱绘制概率校准图
- R probably cal_validate_logistic 使用和不使用逻辑校准来测量性能
- R probably cal_validate_isotonic_boot 使用和不使用袋装等渗回归校准来测量性能
- R probably cal_plot_regression 回归校准图
- R probably cal_validate_multinomial 使用和不使用多项式校准来测量性能
- R probably cal_apply 对一组现有预测应用校准
- R probably cal_validate_linear 使用和不使用线性回归校准来测量性能
- R probably cal_plot_windowed 通过移动窗口绘制概率校准图
- R probably cal_validate_isotonic 使用和不使用等渗回归校准来测量性能
- R probably cal_validate_beta 使用和不使用 Beta 校准来测量性能
- R probably class_pred 创建类别预测对象
- R probably append_class_pred 添加 class_pred 列
- R probably threshold_perf 生成跨概率阈值的性能指标
- R probably as_class_pred 强制转换为 class_pred 对象
- R probably levels.class_pred 提取class_pred级别
- R probably locate-equivocal 找到模棱两可的值
- R probably int_conformal_quantile 通过保形推理和分位数回归预测区间
- R probably make_class_pred 根据类概率创建 class_pred 向量
- R probably reportable_rate 计算报告率
注:本文由纯净天空筛选整理自Max Kuhn等大神的英文原创作品 Uses a linear regression model to calibrate numeric predictions。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。