用法:
DataFrame.plot.density(bw_method=None, ind=None, **kwargs)使用高斯核生成核密度估计图。
在统计学中,kernel density estimation (KDE) 是一种估计随机变量概率密度函数 (PDF) 的非参数方法。此函数使用高斯核并包括自动带宽确定。
- bw_method:str,标量或可调用,可选
用于计算估计器带宽的方法。这可以是‘scott’, ‘silverman’、标量常量或可调用对象。如果无(默认),则使用‘scott’。有关详细信息,请参阅
scipy.stats.gaussian_kde。- ind:NumPy 数组或 int,可选
估计 PDF 的评估点。如果无(默认),则使用 1000 个等距点。如果
ind是 NumPy 数组,则在传递的点处评估 KDE。如果ind是整数,则使用ind等距点数。- **kwargs:
其他关键字参数记录在
DataFrame.plot()中。
- matplotlib.axes.Axes 或其中的 numpy.ndarray
参数:
返回:
例子:
给定从未知分布中随机采样的一系列点,使用具有自动带宽确定函数的 KDE 估计其 PDF 并绘制结果,在 1000 个等间距点处评估它们(默认):
>>> s = pd.Series([1, 2, 2.5, 3, 3.5, 4, 5]) >>> ax = s.plot.kde()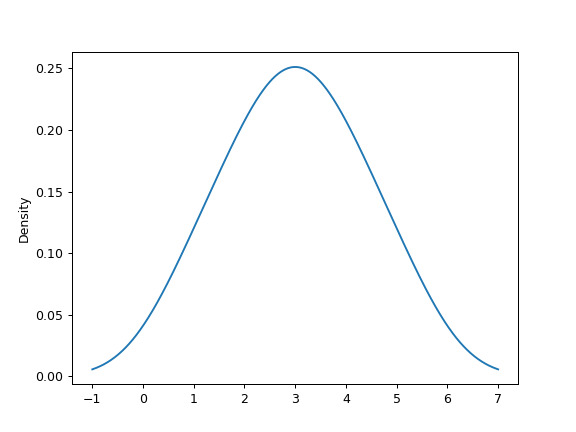
可以指定标量带宽。使用较小的带宽值会导致 over-fitting,而使用较大的带宽值可能会导致 under-fitting:
>>> ax = s.plot.kde(bw_method=0.3)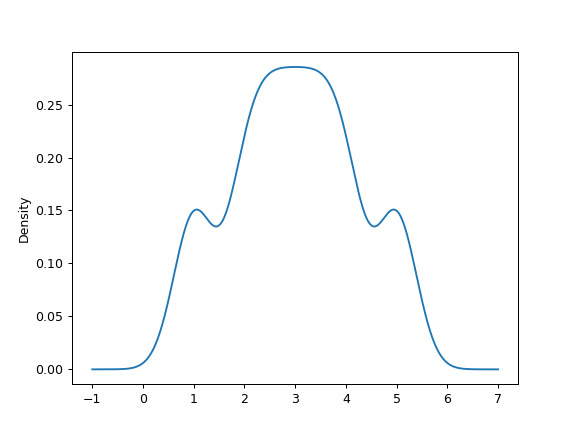
>>> ax = s.plot.kde(bw_method=3)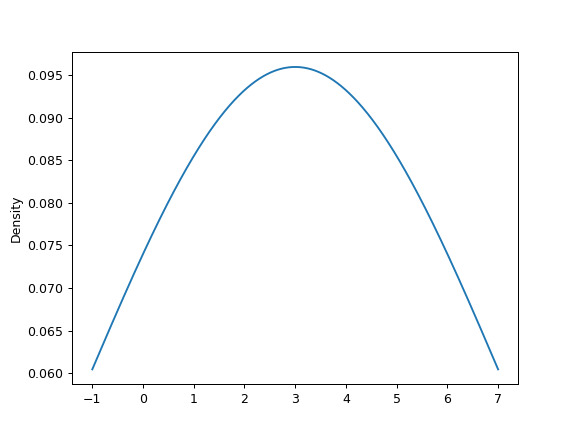
最后,
ind参数确定估计 PDF 绘图的评估点:>>> ax = s.plot.kde(ind=[1, 2, 3, 4, 5])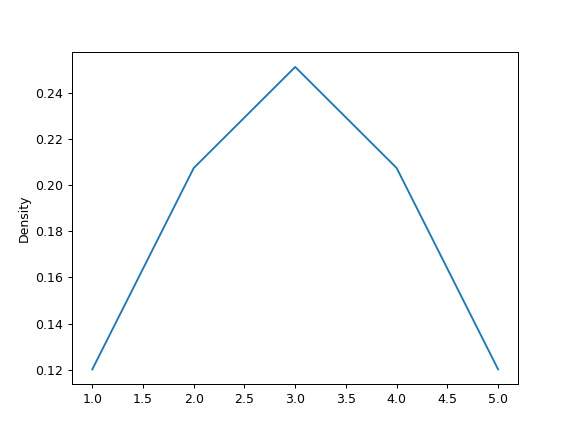
对于 DataFrame,它的工作方式相同:
>>> df = pd.DataFrame({ ... 'x': [1, 2, 2.5, 3, 3.5, 4, 5], ... 'y': [4, 4, 4.5, 5, 5.5, 6, 6], ... }) >>> ax = df.plot.kde()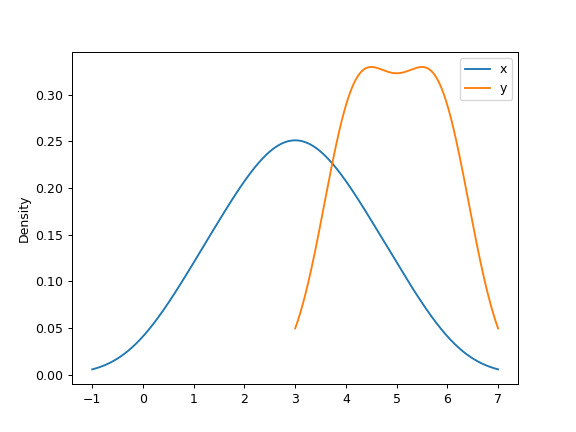
可以指定标量带宽。使用较小的带宽值会导致 over-fitting,而使用较大的带宽值可能会导致 under-fitting:
>>> ax = df.plot.kde(bw_method=0.3)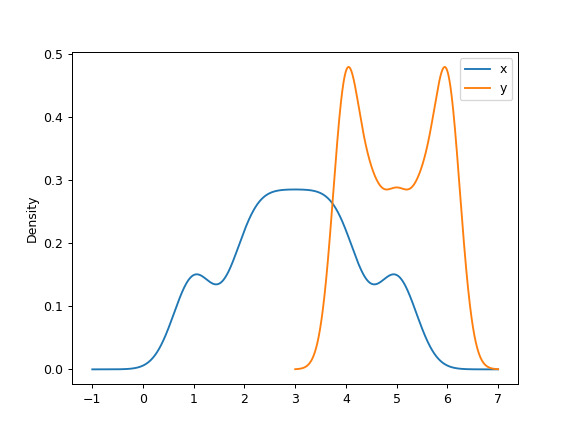
>>> ax = df.plot.kde(bw_method=3)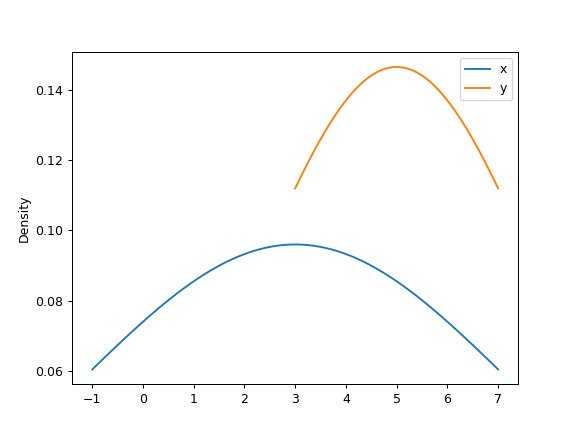
最后,
ind参数确定估计 PDF 绘图的评估点:>>> ax = df.plot.kde(ind=[1, 2, 3, 4, 5, 6])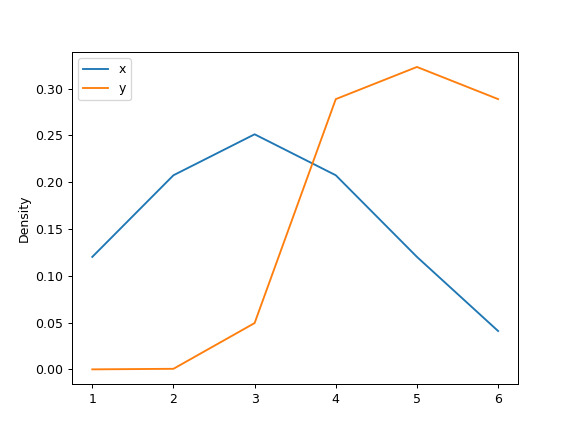
相关用法
- Python pandas.DataFrame.plot.hexbin用法及代码示例
- Python pandas.DataFrame.plot.barh用法及代码示例
- Python pandas.DataFrame.plot.kde用法及代码示例
- Python pandas.DataFrame.plot.box用法及代码示例
- Python pandas.DataFrame.plot.area用法及代码示例
- Python pandas.DataFrame.plot.scatter用法及代码示例
- Python pandas.DataFrame.plot.bar用法及代码示例
- Python pandas.DataFrame.plot.hist用法及代码示例
- Python pandas.DataFrame.plot.pie用法及代码示例
- Python pandas.DataFrame.plot.line用法及代码示例
- Python pandas.DataFrame.product用法及代码示例
- Python pandas.DataFrame.prod用法及代码示例
- Python pandas.DataFrame.pivot用法及代码示例
- Python pandas.DataFrame.pipe用法及代码示例
- Python pandas.DataFrame.pivot_table用法及代码示例
- Python pandas.DataFrame.pop用法及代码示例
- Python pandas.DataFrame.pow用法及代码示例
- Python pandas.DataFrame.pct_change用法及代码示例
- Python pandas.DataFrame.ewm用法及代码示例
- Python pandas.DataFrame.dot用法及代码示例
注:本文由纯净天空筛选整理自pandas.pydata.org大神的英文原创作品 pandas.DataFrame.plot.density。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。