Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
处理长文本数据(段落或消息)时,Pandas str.wrap()是一种重要的方法。当它超过传递的宽度时,用于将长文本数据分发到新行中或处理制表符空间。由于这是一个字符串方法,因此必须在每次调用.str之前添加前缀。
用法:Series.str.wrap(width, **kwargs)
参数:
width:整数值,定义最大线宽
**kwargs[可选参数]
expand_tabs:布尔值,如果为True,则将制表符扩展为空格
replace_whitespace:布尔值(如果为true),则每个空格字符均被单个空格替换。
drop_whitespace:布尔值,如果为true,则在新行的开头删除空白(如果有)
break_long_words:布尔值(如果为True)会打断比传递的宽度长的单词。
break_on_hyphens:布尔值(如果为true)会在字符串长度小于宽度的连字符处中断字符串。
返回类型:带有分隔线/添加字符的系列(“ \ n”)
要下载代码中使用的数据集,请单击此处。
在以下示例中,使用的 DataFrame 包含一些NBA球员的数据。下面是任何操作之前的数据帧图像。
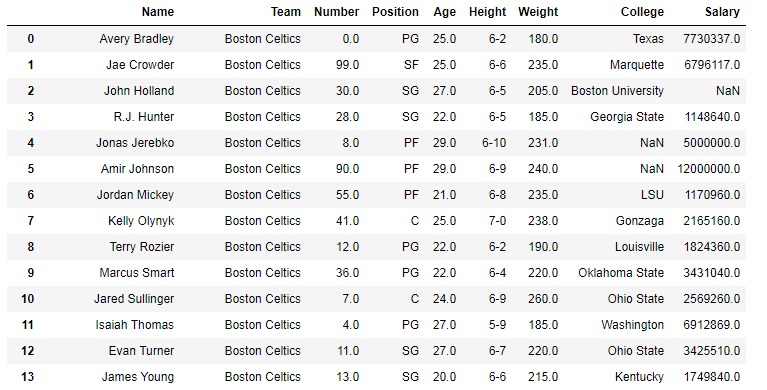
例:
在此示例中,“团队”列的行宽为5个字符。因此,\ n将被放置在每5个字符之后。打印来自新团队列和旧团队列的随机元素以查看工作情况。在应用任何操作之前,请使用.dropna()方法删除空元素。
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# dropping null value columns to avoid errors
data.dropna(inplace = True)
# display
data["New Team"]= data["Team"].str.wrap(5)
# data frame display
data
# printing same index separately
print(data["Team"][120])
print("------------")
print(data["New Team"][120])输出:
如输出图像所示,“新建”列每5个字符后就有“ \ n”。在打印相同的旧团队和新团队列索引之后,可以看出,在print语句中未添加新行字符的情况下,python会自动读取字符串中的“ \ n”并将其放在新行中。
带有新团队列的 DataFrame -
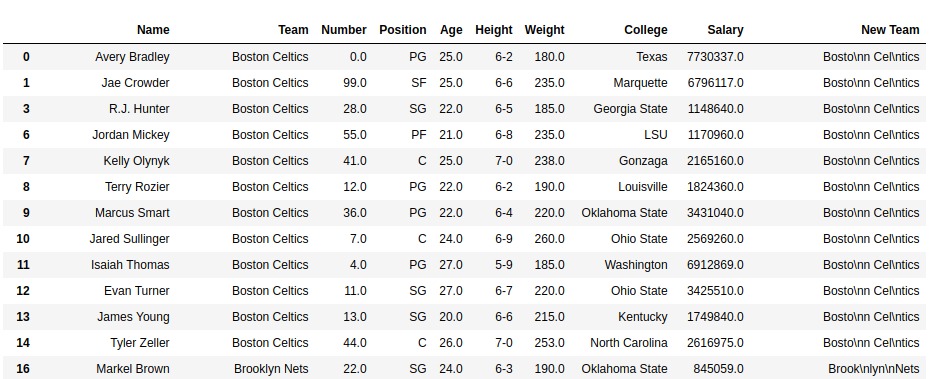
输出:
Los Angeles Lakers ------------ Los A ngele s Lak ers
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Panel.add()用法及代码示例
- Python Pandas Index.where用法及代码示例
- Python Pandas Series.at用法及代码示例
- Python Pandas Series.add()用法及代码示例
- Python Pandas dataframe.std()用法及代码示例
- Python Pandas dataframe.ne()用法及代码示例
- Python Pandas Series.mul()用法及代码示例
- Python Pandas Series.sub()用法及代码示例
- Python Pandas Series.sem()用法及代码示例
- Python Pandas Panel.div()用法及代码示例
- Python Pandas Panel.pow()用法及代码示例
- Python Pandas.to_datetime()用法及代码示例
- Python Pandas Panel.mul()用法及代码示例
- Python Pandas.factorize()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas Series.str.wrap()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。